

«`html
Оценка производительности Retrieval-Augmented Generation (RAG) систем
Большие языковые модели (LLM) стали популярными в последнее время. Однако оценка LLM по широкому спектру задач может быть чрезвычайно сложной. Общедоступные стандарты не всегда точно отражают общие навыки LLM, особенно когда речь идет о выполнении высокоспециализированных клиентских задач, требующих знания в определенной области. Различные метрики оценки используются для улавливания различных аспектов производительности LLM, но ни одна отдельная статистика не достаточна для оценки всех аспектов производительности.
Оценка корректности систем Retrieval-Augmented Generation (RAG)
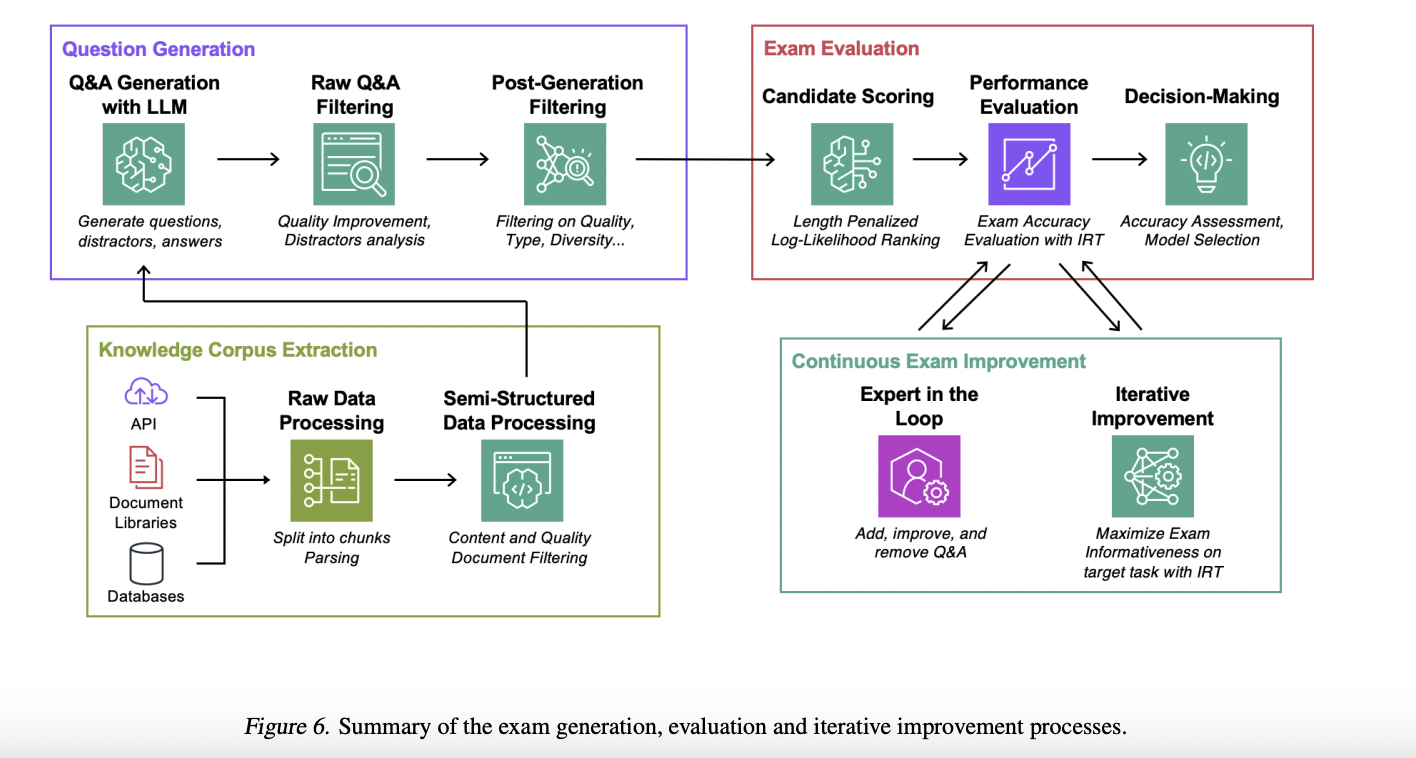
Команда исследователей из Amazon предложила подход к оценке корректности систем Retrieval-Augmented Generation (RAG) на конкретных задачах, основанный на LLM. Для этой полностью автоматизированной процедуры не требуется предварительно аннотированный набор данных. Фактическая точность или способность системы получать и применять правильные данные для точного ответа на запрос пользователя является основной целью измерений. Этот метод предоставляет пользователям больше информации о влияющих на производительность RAG аспектах, включая размер модели, механизмы извлечения, техники подсказок и процедуры настройки, помогая им выбрать оптимальное сочетание компонентов для своих систем RAG.
Автоматизированный подход к оценке
Команда предложила полностью автоматизированный, количественный подход к оценке на основе экзаменов, который можно масштабировать вверх или вниз. Это в отличие от традиционных оценок с участием человека, которые могут быть дорогостоящими из-за необходимости участия эксперта или аннотатора. Экзамены создаются с использованием этого метода LLM, использующего корпус данных, связанных с текущим заданием. Затем кандидатские системы RAG оцениваются по их способности отвечать на вопросы с выбором ответа, взятые из этих оценок.
Основные преимущества
Команда представила свои основные вклады в следующем:
- Разработан обширный подход к автоматической оценке RAG LLM пайплайнов, основанный на синтетических тестах, специфичных для задачи и созданных для удовлетворения уникальных требований каждого задания.
- Использована теория ответов на элементы (IRT) для создания надежных и понятных метрик оценки. Эти метрики помогают количественно оценить и прояснить аспекты, влияющие на эффективность модели.
- Предложен методичный, полностью автоматизированный подход к созданию тестов, использующий итеративный процесс совершенствования для оптимизации информативности экзаменов, обеспечивая точную оценку возможностей модели.
- Предоставлены наборы данных для оценки систем RAG на основе четырех уникальных задач, предлагающих широкий спектр сценариев оценки из-за использования общедоступных наборов данных из различных областей.
Подробнее ознакомьтесь с статьей и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе в LinkedIn. Если вам понравилась наша работа, вам понравится и наш новостной бюллетень.
Не забудьте присоединиться к нашему подразделу ML на Reddit.
Найдите предстоящие вебинары по ИИ здесь.
Оцените возможности использования ИИ в продажах с помощью AI Sales Bot здесь.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab здесь. Будущее уже здесь!
«`



















