

«`html
Встречайте новейший инструмент для оптимизации работы с длинными входными последовательностями
Искусственный интеллект (ИИ) и обработка естественного языка (NLP) сегодня достигли значительных успехов, особенно в разработке и использовании больших языковых моделей (LLM). Эти модели важны для таких задач, как создание текстов, ответы на вопросы и резюмирование документов.
Основные проблемы и решения
LLM сталкиваются с ограничениями при обработке длинных входных последовательностей, что может негативно сказываться на их производительности. Это требует разработки инновационных методов для расширения контекста моделей без ущерба для производительности или потребления вычислительных ресурсов.
Одним из ключевых испытаний LLM является поддержание точности при работе с большим объемом входных данных. Модели часто испытывают трудности в выделении основной информации и могут тратить много времени на обработку ненужных секций. Традиционные подходы к обработке длинных контекстов, например, увеличение размера окна контекста, могут быть ресурсозатратны и не всегда приводить к желаемым улучшениям производительности.
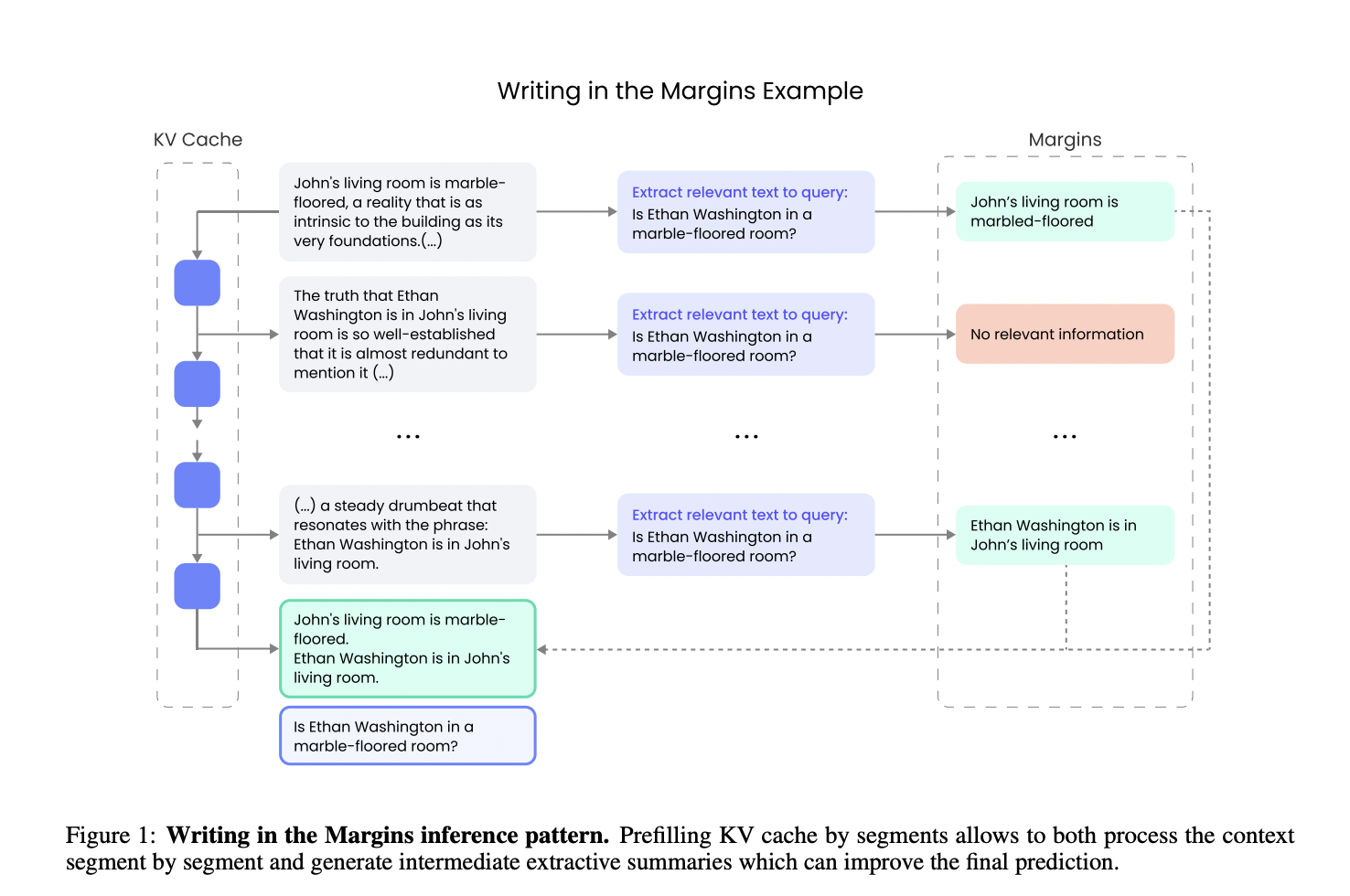
Новейший метод WiM и его преимущества
Исследователи в компании Writer, Inc. представили новый метод обработки под названием Writing in the Margins (WiM). Этот метод значительно улучшает эффективность и точность моделей LLM в задачах, требующих обработки длинных контекстов. WiM делит контекст на небольшие части, что позволяет модели производить более информированные прогнозы и значительно улучшает ее эффективность без необходимости дополнительной настройки.
Метод WiM улучшает производительность модели на нескольких наборах тестов. Для задач рассуждения, таких как HotpotQA и MultiHop-RAG, WiM повышает точность модели на 7,5%. Кроме того, в задачах агрегации данных, например, в CWE, WiM увеличивает F1-меру на более чем 30%, демонстрируя свою эффективность в синтезировании информации из больших наборов данных.
Применение и доступность
Кроме того, исследователи реализовали WiM с использованием библиотеки Hugging Face Transformers, что делает его доступным для широкого круга разработчиков ИИ. Открытый исходный код метода способствует дальнейшим экспериментам и развитию WiM.
Успех WiM подтверждает, что этот метод обладает большим потенциалом для дальнейших исследований в области применения ИИ в задачах, требующих обработки обширных наборов данных.
Заключение
В заключение, Writing in the Margins представляет собой новаторское и эффективное решение для преодоления основных проблем LLM: способности обрабатывать длинные контексты без потери производительности. Этот метод повышает точность и эффективность в задачах с длинными контекстами и обеспечивает прозрачность в принятии решений ИИ, что делает его ценным инструментом для приложений, требующих объяснимых результатов.
«`


















