

«`html
Развитие автономных агентов в исследованиях искусственного интеллекта
Развитие автономных агентов способных выполнять сложные задачи в различных средах получило значительное внимание в исследованиях искусственного интеллекта. Эти агенты разработаны для интерпретации и выполнения инструкций на естественном языке в графических пользовательских интерфейсах (GUI), таких как веб-сайты, настольные операционные системы и мобильные устройства. Их способность безупречно перемещаться и выполнять задачи в различных средах критически важна для развития взаимодействия человека с компьютером, позволяя машинам обрабатывать все более сложные функции, охватывающие несколько платформ и систем.
Основные проблемы и практические решения
Одной из основных проблем в этой области является разработка надежных бенчмарков, способных точно оценить производительность этих агентов в реальных сценариях. Традиционные бенчмарки часто не удовлетворяют эту потребность из-за ограничений, таких как узкое фокусирование на задачах в одной среде, зависимость от статических наборов данных и упрощенные методы оценки, не отражающие динамическую природу приложений в реальном мире.
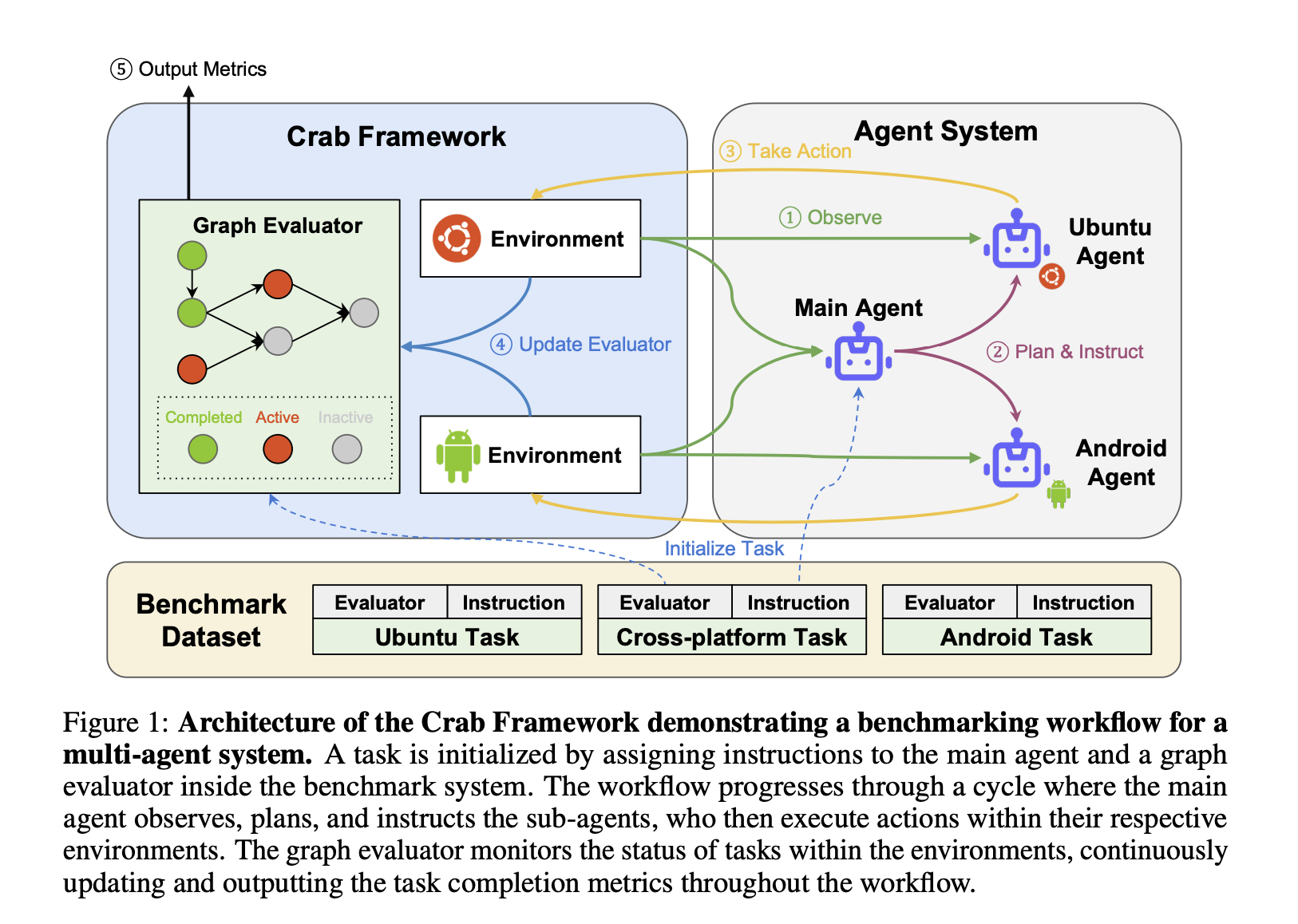
Исследователи из KAUST, Eigent.AI, UTokyo, CMU, Stanford, Harvard, Tsinghua, SUSTech и Oxford разработали Crab Framework, новый инструмент для оценки кросс-средовых задач. Этот фреймворк выделяется поддержкой функций, охватывающих несколько устройств и платформ, таких как настольные компьютеры и мобильные телефоны, а также включает метод оценки на основе графов, предлагающий более детальную и нюансированную оценку производительности агента.
Crab Framework представляет инновационный подход к оценке задач путем декомпозиции сложных задач на более мелкие, управляемые подзадачи, каждая из которых представлена в виде узлов в направленном ациклическом графе (DAG). Эта структура на основе графов позволяет последовательное и параллельное выполнение подзадач, оцениваемых в нескольких точках, а не только в конце. Такой подход позволяет оценивать производительность агента на каждом шаге задачи, обеспечивая более точное представление о том, насколько хорошо агент функционирует в различных средах.
В Crab Benchmark-v0 исследователи реализовали набор из 100 реальных задач, охватывающих как кросс-средовые, так и односредовые вызовы. Этот комплексный набор функций позволяет провести тщательную оценку того, насколько хорошо агенты могут функционировать на различных платформах, максимально приближаясь к реальным условиям.
Команда исследователей протестировала Crab Framework с использованием четырех передовых мультимодальных языковых моделей (MLM): GPT-4o, GPT-4 Turbo, Claude 3 Opus и Gemini 1.5 Pro. Результаты показали, что установка с использованием модели GPT-4o достигла самого высокого коэффициента завершения задач в размере 35,26%, что указывает на ее превосходную способность справляться с кросс-средовыми задачами.
В заключение, Crab Framework представляет детальный метод оценки на основе графов и поддерживает кросс-средовые задачи, предлагая более динамичную и точную оценку производительности агента. Тестирование бенчмарка с использованием передовых MLM, таких как GPT-4o и GPT-4 Turbo, принесло ценные исследовательские результаты, открывая путь для будущих исследований и разработок в этой области.
Получите поддержку и консультации
Если вам нужны советы по внедрению ИИ, пишите нам на itinai.ru. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`

















