

«`html
Искусственный интеллект в области обработки естественного языка (NLP)
Искусственный интеллект в области обработки естественного языка (NLP) сосредотачивается на обеспечении возможности машин понимать и генерировать человеческий язык. Это включает в себя задачи, такие как перевод языка, анализ тональности и суммирование текста. В последние годы были сделаны значительные успехи, приведшие к разработке больших языковых моделей (LLM), способных обрабатывать огромные объемы текста. Эти достижения открыли возможности для выполнения сложных задач, таких как суммирование длинных текстов и генерация с использованием поискового алгоритма (RAG).
Оценка производительности LLM в задачах, требующих обработки длинных контекстов
Одной из основных проблем в NLP является эффективная оценка производительности LLM в задачах, требующих обработки длинных контекстов. Традиционные задачи, такие как «Игла в стоге сена», не предоставляют достаточной сложности для различения возможностей последних моделей. Кроме того, оценка качества результатов для этих задач затруднена из-за необходимости использования высококачественных рефератов и надежных автоматических метрик. Этот недостаток в методах оценки затрудняет точную оценку современных LLM.
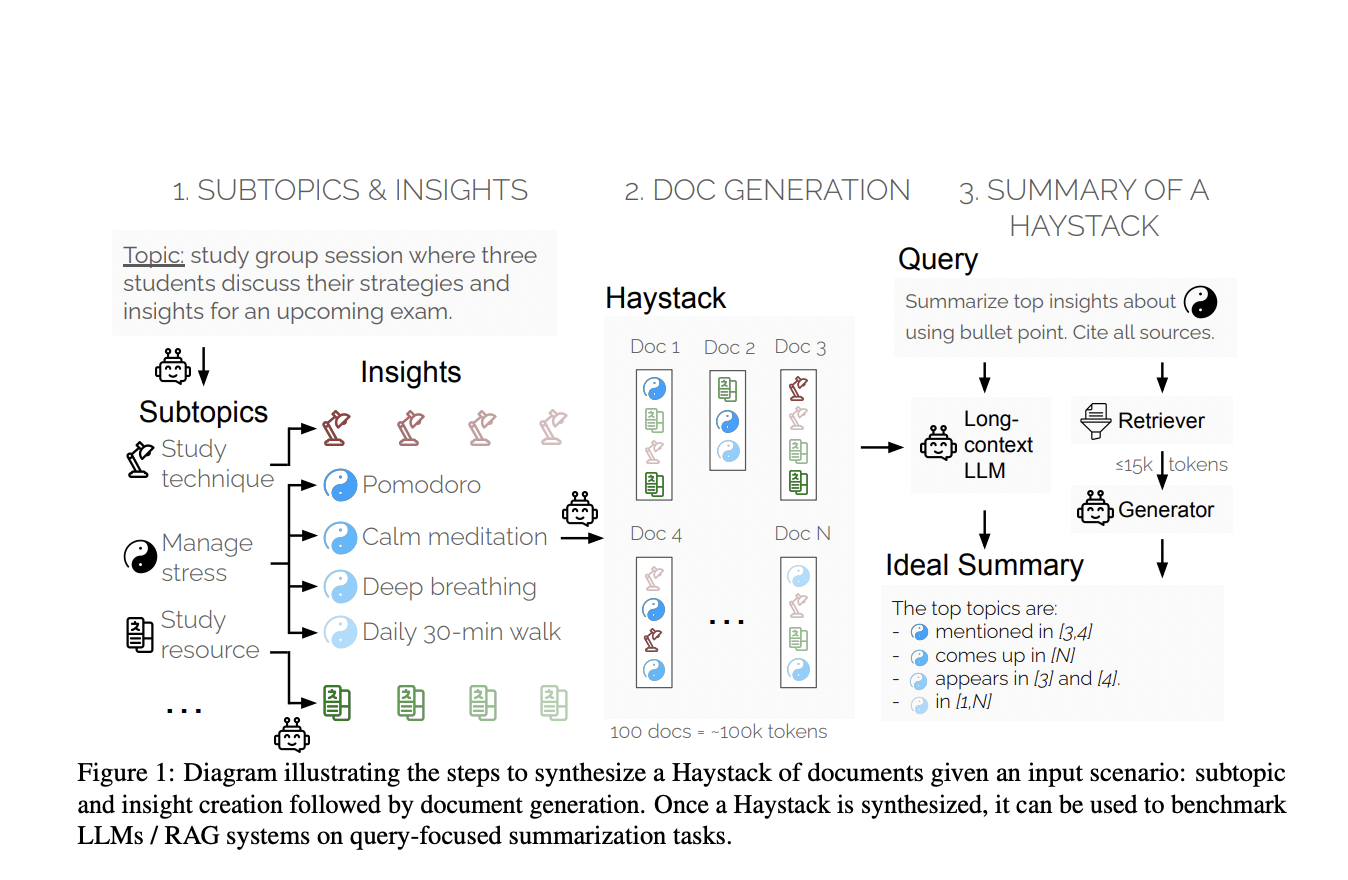
Создание нового метода оценки SummHay
Исследователи из Salesforce AI Research представили новый метод оценки под названием «Summary of a Haystack» (SummHay). Этот метод направлен на более эффективную оценку моделей, обрабатывающих длинные контексты, и систем RAG. Исследователи создали синтетические стоги сена из документов, обеспечивая повторение определенных идей в этих документах. Задача SummHay требует, чтобы системы обрабатывали эти стоги сена, генерировали резюме, точно охватывающие соответствующие идеи, и ссылались на исходные документы. Этот подход обеспечивает воспроизводимую и комплексную основу для оценки.
Оценка производительности
Исследовательская команда провела масштабную оценку 10 LLM и 50 систем RAG. Их результаты показали, что задача SummHay остается значительным вызовом для текущих систем. Например, даже когда системам предоставлялись сигналы о релевантности документов, они отставали от человеческой производительности более чем на 10 пунктов по совместному показателю. Это подчеркивает необходимость дальнейших усовершенствований в этой области.
Заключение
Исследование, проведенное Salesforce AI Research, решает критическую проблему оценки LLM, обрабатывающих длинные контексты, и систем RAG. Бенчмарк SummHay предоставляет надежную основу для оценки возможностей этих систем, выявляя значительные вызовы и области для улучшения. Несмотря на то, что текущие системы показывают результаты ниже человеческих показателей, это исследование проложило путь для будущих разработок, которые в конечном итоге могут соответствовать или превзойти человеческую производительность в суммировании длинных текстов.
Проверьте статью и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему подпреддиту с 46 тысячами подписчиков.
«`


















