

«`html
Оптимизация байтового представления для автоматического распознавания речи (ASR) и сравнение с представлением UTF-8
Энд-ту-энд (E2E) нейронные сети стали гибкими и точными моделями для мультиязычного автоматического распознавания речи. Однако, с увеличением числа поддерживаемых языков, особенно тех, у которых большой набор символов, таких как китайский, японский и корейский (CJK), размер выходного слоя значительно увеличивается. Это отрицательно влияет на вычислительные ресурсы, использование памяти и размер ресурсов. Особенно это становится проблематичным в мультиязычных системах, где выход часто состоит из объединений символов или подслов из различных языков. Исследователи сталкиваются с необходимостью поддерживать эффективность и производительность модели, учитывая разнообразие языков и связанные с ними наборы символов в системах E2E ASR.
Предложенное решение
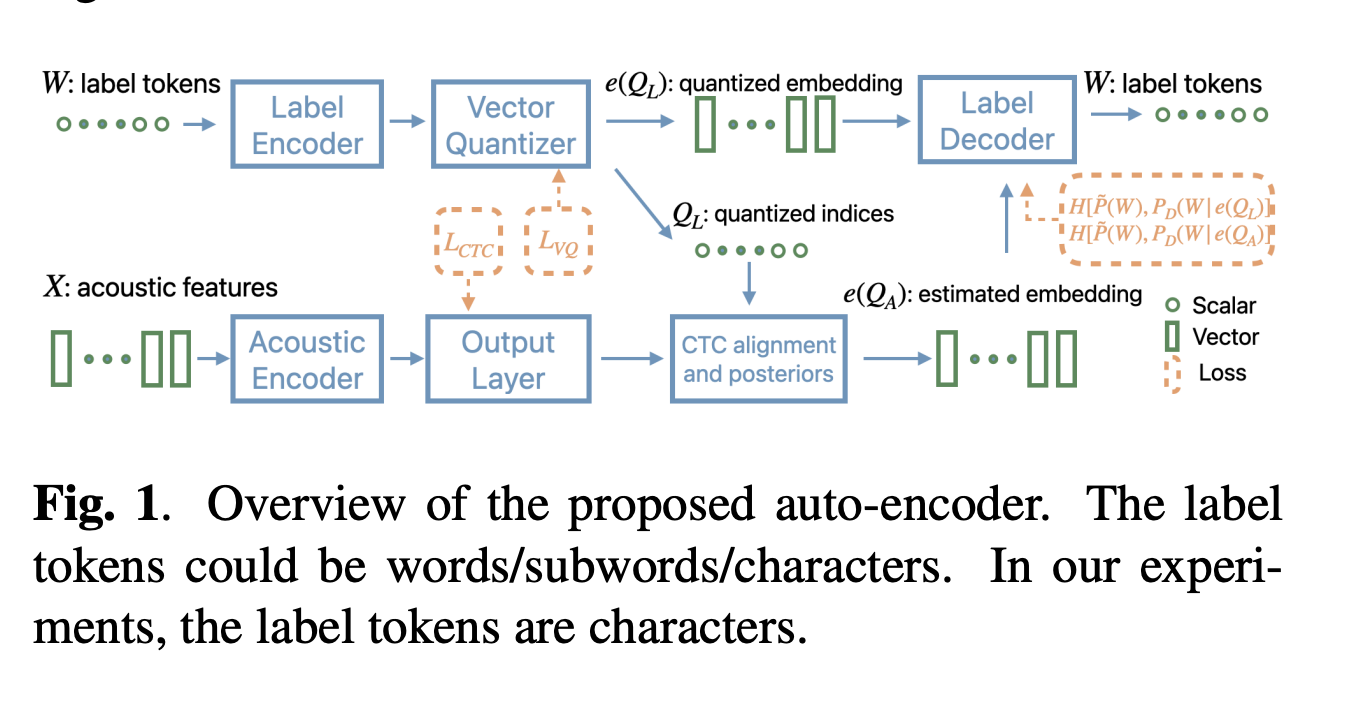
Исследователи Apple предлагают метод оптимизации байтового представления с использованием векторного квантового автокодировщика. Этот метод специально нацелен на задачи E2E ASR, учитывая ограничения предыдущих подходов. Система разработана на основе данных, включая информацию из текста и аудио для повышения точности. Она обладает гибкостью для включения дополнительной информации, такой как лексиконы или фонемы, что делает ее применимой в различных сценариях ASR. Важно отметить, что метод включает механизм коррекции ошибок для обработки недопустимых последовательностей, при этом восстановление оптимизировано для точности, а не для других метрик.
Результаты и преимущества
Эксперименты с двуязычными английскими и мандариновыми наборами данных показали, что предложенный метод превосходит представления UTF-8 по различным размерам подслов. При использовании 8000 подслов, подход на основе векторного квантования позволил достичь относительного снижения коэффициента ошибок слов в 5,8% для английского и относительного снижения коэффициента ошибок символов в 3,7% для мандаринового языка по сравнению с UTF-8. По сравнению с представлением на основе символов, оба представления — VQ и UTF-8 — показали лучшие результаты для английского, сохраняя при этом сходную точность для мандаринового языка.
Это исследование представляет собой надежный алгоритм для оптимизации байтового представления в ASR, предлагая альтернативу представлению UTF-8. Этот подход может быть оптимизирован с использованием аудио- и текстовых данных с механизмом коррекции ошибок, спроектированным для повышения точности. Тестирование на английских и мандариновых наборах данных показало относительное снижение коэффициента ошибок токенов на 5% по сравнению с методами, основанными на UTF-8.
Хотите узнать больше о применении ИИ в вашем бизнесе? Свяжитесь с нами на https://t.me/itinai и следите за новостями в нашем Телеграм-канале https://t.me/aisalesbotnews
Используйте AI Sales Bot https://saile.ru/ — это ИИ-ассистент для продаж, который помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
«`

















