

Проект EuroLLM: Революция в мультиязычной обработке текста и искусственном интеллекте
Цель проекта
Создание мультиязычных языковых моделей EuroLLM, способных понимать и генерировать текст на всех официальных языках Европейского союза.
Сбор и фильтрация данных
Использование разнообразных источников данных для обучения моделей EuroLLM, включая веб-данные, параллельные данные, данные по коду и математике, а также высококачественные данные.
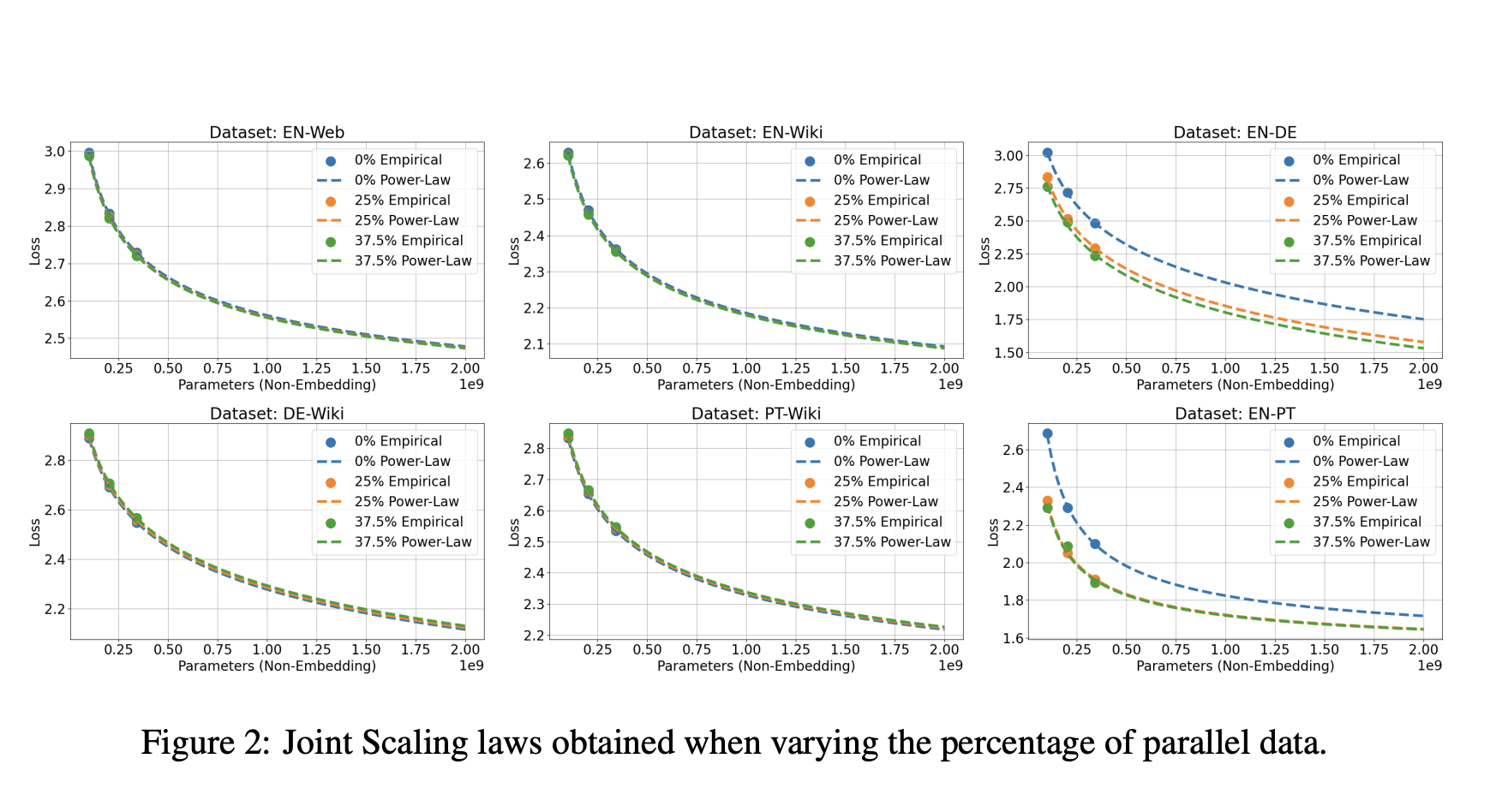
Смесь данных
Балансировка данных разных языков и областей для обучения моделей EuroLLM, включая английский, другие языки и данные по коду и математике.
Токенизатор
Разработка мультиязычного токенизатора для эффективной поддержки различных языков и улучшения работы моделей EuroLLM.
Конфигурация модели
Использование стандартной архитектуры плотного трансформера с дополнительными модификациями для повышения производительности модели EuroLLM.
Результаты
Оценка моделей EuroLLM на различных задачах и бенчмарках показала их эффективность и преимущества в мультиязычной обработке текста.
Заключение и будущая работа
Проект EuroLLM успешно разработал мультиязычные языковые модели, поддерживающие все языки Европейского союза, и планирует дальнейшее улучшение и расширение функционала для обеспечения эффективной работы моделей в многоязычной среде.












![Как искусственный интеллект экономит время в продажах и где использовать дополнительные часы [Новые данные]](https://saile.ru/wp-content/uploads/2025/05/itinai.com_IT-company_office_background_blured_-chaos_50_-v_74e4829b-a652-4689-ad2e-c962916303b4_0-200x200.avif)




