

«`html
Пересмотр обучения LLM: Обещание методов обратного обучения по усилению
Большие языковые модели (LLM) привлекли значительное внимание в области искусственного интеллекта, в первую очередь благодаря их способности имитировать человеческие знания с помощью обширных наборов данных. Текущие методики обучения этих моделей тяжело полагаются на обучение по имитации, в частности на предсказание следующего токена с использованием оценки максимального правдоподобия (MLE) во время предварительного обучения и надзорной доводки. Однако этот подход сталкивается с несколькими проблемами, включая накапливающиеся ошибки в авторегрессионных моделях, предвзятость в экспозиции и сдвиги распределения во время итеративного применения модели. По мере развития области возникает растущая необходимость в решении этих проблем и разработке более эффективных методов обучения и согласования LLM с предпочтениями и намерениями человека.
Существующие попытки решения проблем обучения языковых моделей в основном сосредоточены на двух основных подходах: клонировании поведения (BC) и обратном обучении по усилению (IRL). BC, аналогично надзорной доводке через MLE, напрямую имитирует экспертные демонстрации, но страдает от накапливающихся ошибок и требует обширного охвата данных. IRL, с другой стороны, совместно выводит политику и функцию вознаграждения, потенциально преодолевая ограничения BC путем использования дополнительных взаимодействий с окружающей средой. Недавние методы IRL включают игровые подходы, регуляризацию энтропии и различные техники оптимизации для улучшения стабильности и масштабируемости. В контексте языкового моделирования некоторые исследователи исследовали методы адверсарного обучения, такие как SeqGAN, в качестве альтернатив MLE. Однако эти подходы показали ограниченный успех, работая эффективно только в конкретных температурных режимах. Несмотря на эти усилия, область продолжает искать более надежные и масштабируемые решения для обучения и согласования больших языковых моделей.
Исследователи DeepMind предлагают глубокое изучение оптимизации на основе обратного обучения по усилению, в частности сосредотачиваясь на перспективе согласования распределения IRL для настройки больших языковых моделей. Этот подход направлен на предоставление эффективной альтернативы стандартному MLE. Исследование охватывает как адверсарные, так и неадверсарные методы, а также оффлайн и онлайн техники. Ключевым новшеством является расширение обратного мягкого Q-обучения для установления принципиальной связи с классическим клонированием поведения или MLE. Исследование оценивает модели от 250M до 3B параметров, включая архитектуры кодировщик-декодировщик T5 и только декодер PaLM2. Исследование стремится продемонстрировать преимущества IRL перед клонированием поведения в обучении по имитации для языковых моделей, исследуя производительность задач и разнообразие генерации.
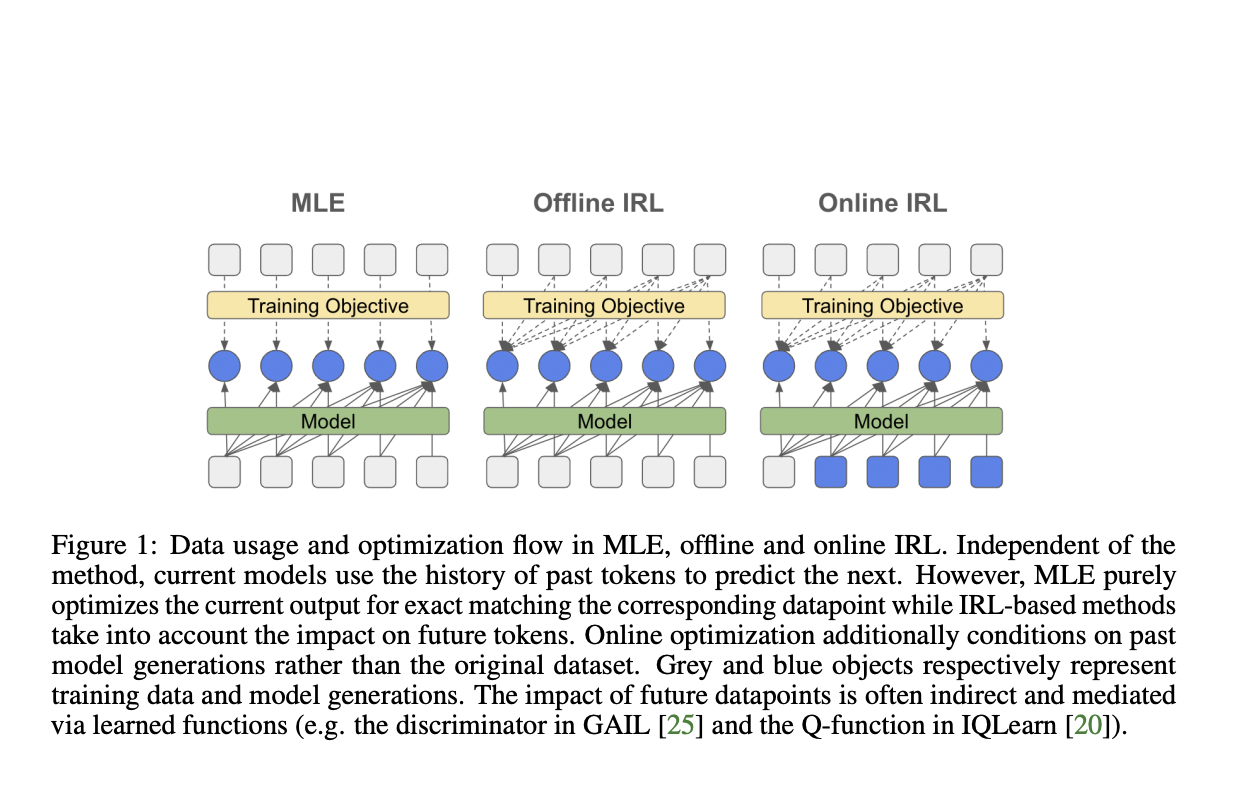
Предложенная методология вводит уникальный подход к настройке языковой модели путем переформулирования обратного мягкого Q-обучения как регуляризованное расширение MLE. Этот метод сокращает разрыв между MLE и алгоритмами, использующими последовательную природу генерации языка.
Подход моделирует генерацию языка как проблему последовательного принятия решений, где генерация следующего токена зависит от ранее сгенерированной последовательности. Исследователи фокусируются на минимизации расхождения между γ-дисконтированным распределением состояний-действий политики и экспертной политики, в сочетании с взвешенным термином причинной энтропии.
Формулировка использует χ2-расхождение и пересчитывает функцию ценности, что приводит к цели IQLearn:
Эта цель состоит из двух основных компонентов:
- Регуляризационный термин, связывающий изученную политику с функцией ценности, благоприятствующий политикам, где логарифмическая вероятность действий соответствует разнице в значениях состояний.
- Термин MLE, поддерживающий связь с традиционным обучением языковых моделей.
Эта формулировка позволяет откалибровать регуляризационный термин, обеспечивая гибкость в балансировке между стандартным MLE (λ = 0) и более сильной регуляризацией. Этот подход позволяет оффлайн-обучение с использованием только экспертных образцов, потенциально улучшая вычислительную эффективность в настройке масштабных языковых моделей.
Исследователи провели обширные эксперименты для оценки эффективности методов IRL по сравнению с MLE для настройки больших языковых моделей. Их результаты демонстрируют несколько ключевых выводов:
- Улучшение производительности: методы IRL, особенно IQLearn, показали небольшие, но заметные улучшения в производительности задач по различным бенчмаркам, включая XSUM, GSM8k, TLDR и WMT22. Эти улучшения были особенно заметны для математических и логических задач.
- Увеличение разнообразия: IQLearn последовательно производил более разнообразные генерации моделей по сравнению с MLE, что указывает на лучший баланс между производительностью задач и разнообразием вывода.
- Масштабируемость модели: Преимущества методов IRL были замечены для различных размеров моделей и архитектур, включая модели T5 (base, large и xl) и PaLM2.
- Чувствительность к температуре: Для моделей PaLM2 IQLearn достиг более высокой производительности в режимах выборки с низкой температурой по всем протестированным задачам, что указывает на улучшенную стабильность качества генерации.
- Снижение зависимости от поиска лучшего варианта: IQLearn продемонстрировал способность снизить зависимость от поиска лучшего варианта во время вывода, сохраняя производительность и, возможно, обеспечивая выигрыши в вычислительной эффективности.
- Производительность GAIL: В то время как стабилизировано для моделей T5, GAIL оказалось сложным для эффективной реализации для моделей PaLM2, что подчеркивает устойчивость подхода IQLearn.
Эти результаты свидетельствуют о том, что методы IRL, особенно IQLearn, представляют собой масштабируемую и эффективную альтернативу MLE для настройки больших языковых моделей, предлагая улучшения как в производительности задач, так и в разнообразии генерации по ряду задач и архитектур моделей.
Эта статья исследует потенциал алгоритмов IRL для настройки языковой модели, сосредотачиваясь на производительности, разнообразии и вычислительной эффективности. Исследователи представляют переформулированный алгоритм IQLearn, обеспечивающий сбалансированный подход между стандартной надзорной доводкой и передовыми методами IRL. Эксперименты показывают значительные улучшения в балансе между производительностью задач и разнообразием генерации с использованием IRL. Исследование в основном демонстрирует, что вычислительно эффективное оффлайн-обучение IRL достигает существенных улучшений производительности по сравнению с оптимизацией на основе MLE без необходимости онлайн-выборки. Кроме того, анализ корреляции между извлеченными из IRL вознаграждениями и метриками производительности указывает на потенциал разработки более точных и надежных функций вознаграждения в языковом моделировании, что открывает путь к улучшению обучения языковых моделей и их согласованию.
Не забудьте присоединиться к нашему Telegram-каналу и следить за нашими новостями об ИИ. Попробуйте AI Sales Bot, это AI ассистент для продаж, который помогает снизить нагрузку на первую линию и генерировать контент для отдела продаж.
«`


















