

«`html
Технология распознавания речи: значение точности временных меток и шумоустойчивости
Точное транскрибирование устной речи становится все более важным в распознавании речи. Эта технология критически важна для услуг доступности, обработки языка и клинических оценок. Однако вызов заключается в том, чтобы захватить слова и тонкие детали человеческой речи, включая паузы, заполнительные слова и другие дисфлюенции. Эти нюансы предоставляют ценную информацию о когнитивных процессах и особенно важны в клинических условиях, где точный анализ речи может помочь в диагностике и мониторинге речевых нарушений. По мере роста спроса на более точную транскрибацию, возрастает и потребность в инновационных методах эффективного решения этих проблем.
Инновационные методы для улучшения точности транскрипции
Одной из основных проблем в этой области является точность временных меток на уровне слов. Это особенно важно в сценариях с несколькими дикторами или фоновым шумом, где традиционные методы часто нуждаются в улучшении. Точная транскрипция дисфлюенций, таких как заполнительные паузы, повторения слов и исправления, затруднительна, но критична. Эти элементы не являются просто артефактами речи; они отражают основные когнитивные процессы и являются ключевыми показателями при оценке состояний, таких как афазия. Существующие модели транскрипции часто нуждаются в помощи с этими нюансами, что приводит к ошибкам как в транскрипции, так и в определении времени. Эти неточности ограничивают их эффективность, особенно в клинических и других важных средах, где требуется высокая точность.
Текущие методы, такие как модели Whisper и WhisperX, пытаются решить эти проблемы с помощью продвинутых техник, таких как принудительное выравнивание и динамическое временное искривление (DTW). WhisperX, например, использует метод сегментации аудио на основе VAD, что улучшает как скорость, так и точность транскрипции. Хотя этот метод предлагает некоторые улучшения, он по-прежнему сталкивается с серьезными проблемами в шумных средах и при сложных речевых образцах. Зависимость от нескольких моделей, как, например, использование WhisperX Wav2Vec2.0 для выравнивания фонем, добавляет сложность и может привести к дальнейшему снижению точности временных меток в менее чем идеальных условиях. Несмотря на эти преимущества, остается явная потребность в более надежных решениях.
Исследователи из Nyra Health представили новую модель — CrisperWhisper. Эта модель улучшила архитектуру Whisper, повысив устойчивость к шуму и сосредоточившись на речи одного диктора. Исследователи значительно улучшили точность временных меток на уровне слов, тщательно настраивая токенизатор и модель. CrisperWhisper использует алгоритм динамического временного искривления, который выравнивает речевые сегменты с большей точностью, даже в условиях фонового шума. Это улучшение повышает производительность модели в шумных средах и снижает ошибки в транскрипции дисфлюенций, что делает ее особенно полезной для клинических приложений.
Ключевые инновации модели CrisperWhisper
Улучшения CrisperWhisper в значительной степени обусловлены несколькими ключевыми инновациями. Модель удаляет ненужные токены и оптимизирует словарь для более точного обнаружения пауз и заполнительных слов, таких как «э-э» и «э-э-м». Она вводит эвристику, которая ограничивает продолжительность пауз до 160 мс, различая между значимыми паузами в речи и незначительными артефактами. CrisperWhisper использует матрицу стоимости, построенную на нормализованных векторах перекрестного внимания, чтобы обеспечить максимально точные временные метки для каждого слова. Этот метод позволяет модели создавать транскрипции, которые не только более точны, но и более надежны в шумных условиях. Результатом является модель, способная точно захватывать время речи, что критически важно для приложений, требующих детального анализа речи.
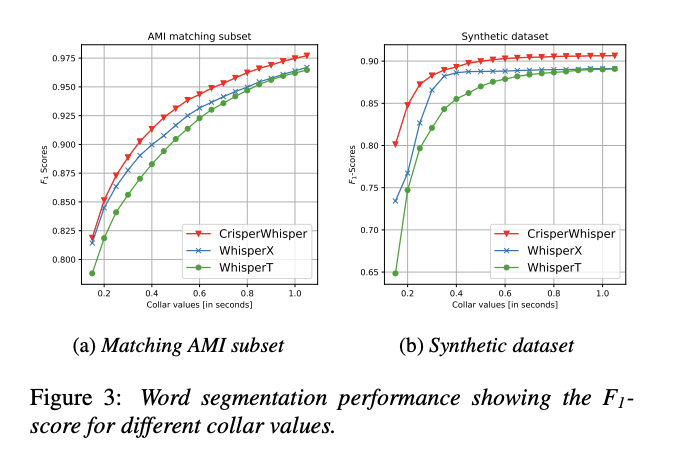
Производительность CrisperWhisper впечатляет по сравнению с предыдущими моделями. Она достигает F1-оценки 0,975 на синтетическом наборе данных и значительно превосходит WhisperX и WhisperT в шумоустойчивости и точности сегментации слов. Например, CrisperWhisper достигает F1-оценки 0,90 на подмножестве дисфлюенций AMI, по сравнению с 0,85 у WhisperX. Модель также демонстрирует превосходную устойчивость к шуму, поддерживая высокие оценки mIoU и F1 даже в условиях соотношения сигнал/шум 1:5. В тестах, включающих наборы данных вербатимной транскрипции, CrisperWhisper снизила уровень ошибок слов (WER) в корпусе AMI Meeting с 16,82% до 9,72% и в наборе данных TED-LIUM с 11,77% до 4,01%. Эти результаты подчеркивают способность модели создавать точные и надежные транскрипции даже в сложных условиях.
Заключение: важность CrisperWhisper для технологии распознавания речи
Nyra Health представила CrisperWhisper, которая решает проблемы точности временных меток и шумоустойчивости. CrisperWhisper представляет собой надежное решение, улучшающее точность транскрипции речи. Ее способность точно захватывать дисфлюенции и поддерживать высокую производительность в шумных условиях делает ее ценным инструментом для различных приложений, особенно в клинических условиях. Улучшения в уровне ошибок слов и общей точности транскрипции подчеркивают потенциал CrisperWhisper установить новый стандарт в технологии распознавания речи.
«`


















