

«`html
Большие мультимодальные модели: новые возможности с использованием искусственного интеллекта
Большие мультимодальные модели (LMM) быстро развиваются, преодолевая потребность в создании систем искусственного интеллекта, способных обрабатывать и создавать контент в нескольких модальностях, например текст и изображения. Эти модели особенно ценны при выполнении задач, требующих глубокой интеграции визуальной и языковой информации, таких как подписывание изображений, визуальное ответы на вопросы и мультимодальное понимание языка. С развитием технологий ИИ сочетание этих различных типов данных становится все более важным для повышения производительности ИИ в сложных реальных сценариях.
Решение проблем
Несмотря на значительные успехи в развитии LMM, существуют несколько проблем, особенно в области доступности и масштаба ресурсов, доступных исследовательскому сообществу. Основной проблемой является ограниченный доступ к масштабным высококачественным наборам данных и сложным методикам обучения, необходимым для создания надежных моделей.
Решение от Salesforce AI Research и Университета Вашингтона
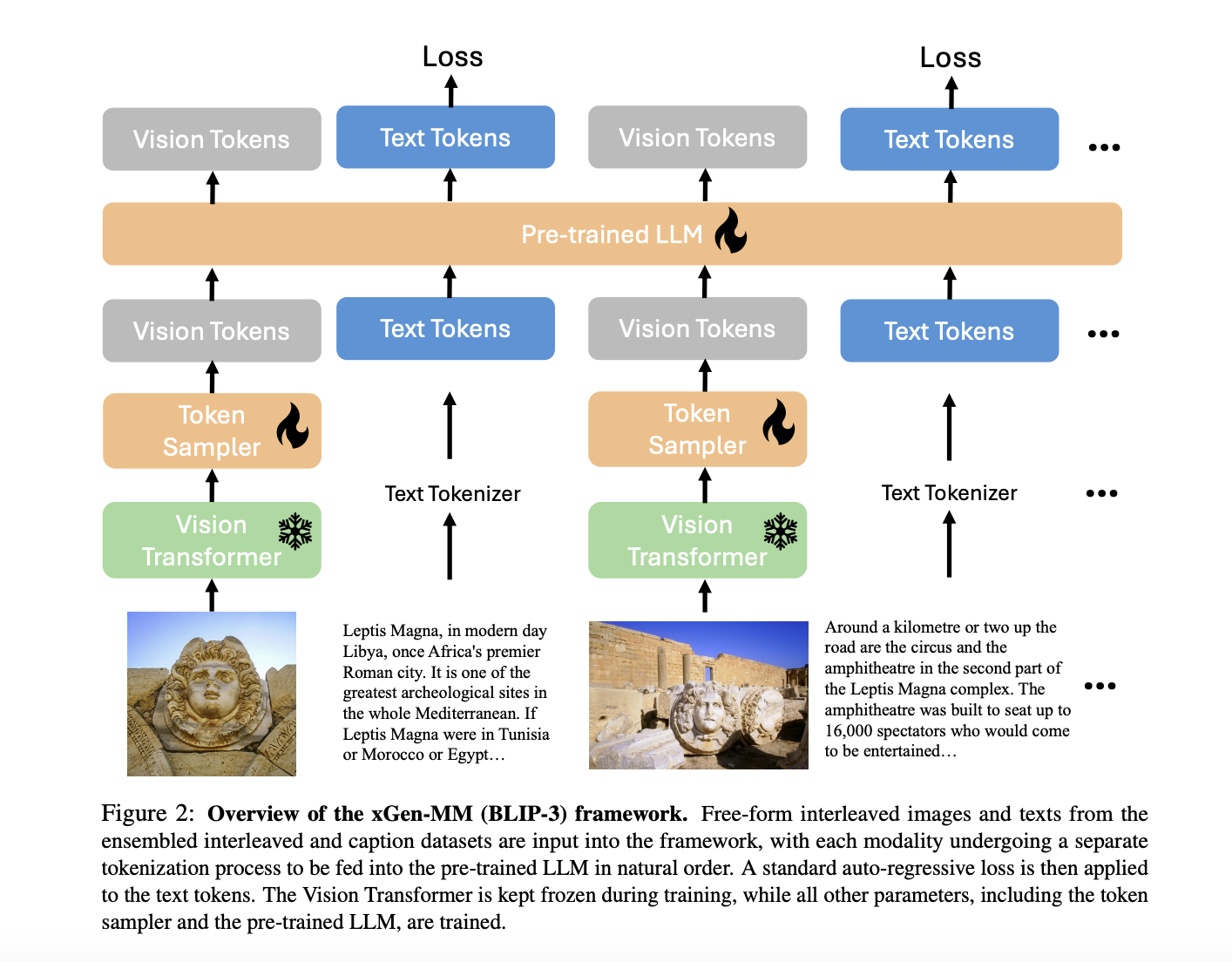
Исследователи из Salesforce AI Research и Университета Вашингтона разработали фреймворк xGen-MM (BLIP-3) в качестве инновационного решения для улучшения масштабируемости и доступности LMM. Фреймворк xGen-MM строится на предыдущих достижениях, но вносит несколько ключевых улучшений, чтобы преодолеть ограничения ранее созданных моделей.
Преимущества xGen-MM (BLIP-3)
Фреймворк xGen-MM (BLIP-3) использует ансамбль мультимодальных межвыборочных наборов данных, подготовленных наборов описаний и общедоступных наборов данных для создания надежной среды обучения. Существенное улучшение xGen-MM заключается в замене слоев Q-Former на более масштабируемый визионный сэмплер, специально настраиваемый персивом. Это упрощает процесс обучения и делает его доступным для крупномасштабного обучения.
Оценка производительности моделей xGen-MM (BLIP-3)
Производительность моделей xGen-MM (BLIP-3) была тщательно оценена на нескольких мультимодальных бенчмарках, продемонстрировав впечатляющие результаты. В частности, модели показали выдающиеся показатели в задачах визуального ответа на вопросы и оптического распознавания символов. Также были внедрены модели, специально настроенные на безопасность, повышающие надежность LMM при сохранении высокой точности в сложных мультимодальных задачах.
Заключение
Фреймворк xGen-MM (BLIP-3) предлагает надежное решение для разработки высокопроизводительных LMM, решая критические проблемы, связанные с доступностью данных и масштабируемостью обучения. Способность фреймворка эффективно и точно интегрировать сложные визуальные и текстовые данные делает его ценным инструментом для исследователей и практиков.
«`


















