

«`html
Модели машинного обучения для генерации кода: значимость качественных данных
Модели машинного обучения, особенно предназначенные для генерации кода, сильно зависят от качественных данных во время предварительного обучения. Недавние исследования показали быстрый прогресс в этой области благодаря большим языковым моделям (LLM), обученным на обширных наборах данных, содержащих код из различных источников. Одной из основных задач исследователей является обеспечение изобилия и высокого качества используемых данных, поскольку это значительно влияет на способность модели решать сложные задачи. В приложениях, связанных с кодом, хорошо структурированные, аннотированные и чистые данные гарантируют, что модели могут генерировать точные, эффективные и надежные результаты для задач программирования в реальном мире.
Проблема качества данных в разработке моделей кода
Существенной проблемой в разработке моделей кода является отсутствие точных определений «высококачественных» данных. Несмотря на доступность больших объемов кода, многие из них содержат шум, избыточность или несущественную информацию, что может негативно сказываться на производительности модели. Основываясь на необработанных данных, даже после фильтрации, часто приводит к неэффективности. Эта проблема становится очевидной, когда модели, обученные на больших наборах данных, показывают низкую производительность на практических тестах. Для решения этой проблемы уделяется все больше внимания не только накоплению больших объемов данных, но и курированию данных, которые хорошо соответствуют практическим приложениям, улучшая предсказательные способности модели и ее общую полезность.
Прогресс в предварительном обучении моделей кода
Исторически предварительное обучение моделей кода включало извлечение данных из больших репозиториев, таких как GitHub, и обработку необработанных данных с помощью базовых методов фильтрации и удаления дубликатов. Затем исследователи применяли классификаторы случайного леса или простые фильтры качества для выявления ценного образовательного кода, как в моделях типа Phi-1. Хотя эти методы в определенной степени улучшили качество данных, они не были достаточными для достижения оптимальной производительности на более сложных задачах программирования. Новые подходы используют более сложные инструменты, такие как аннотаторы на основе BERT, для классификации качества кода и выбора данных, которые более эффективно способствуют успеху модели.
Новаторский подход к предварительному обучению моделей кода
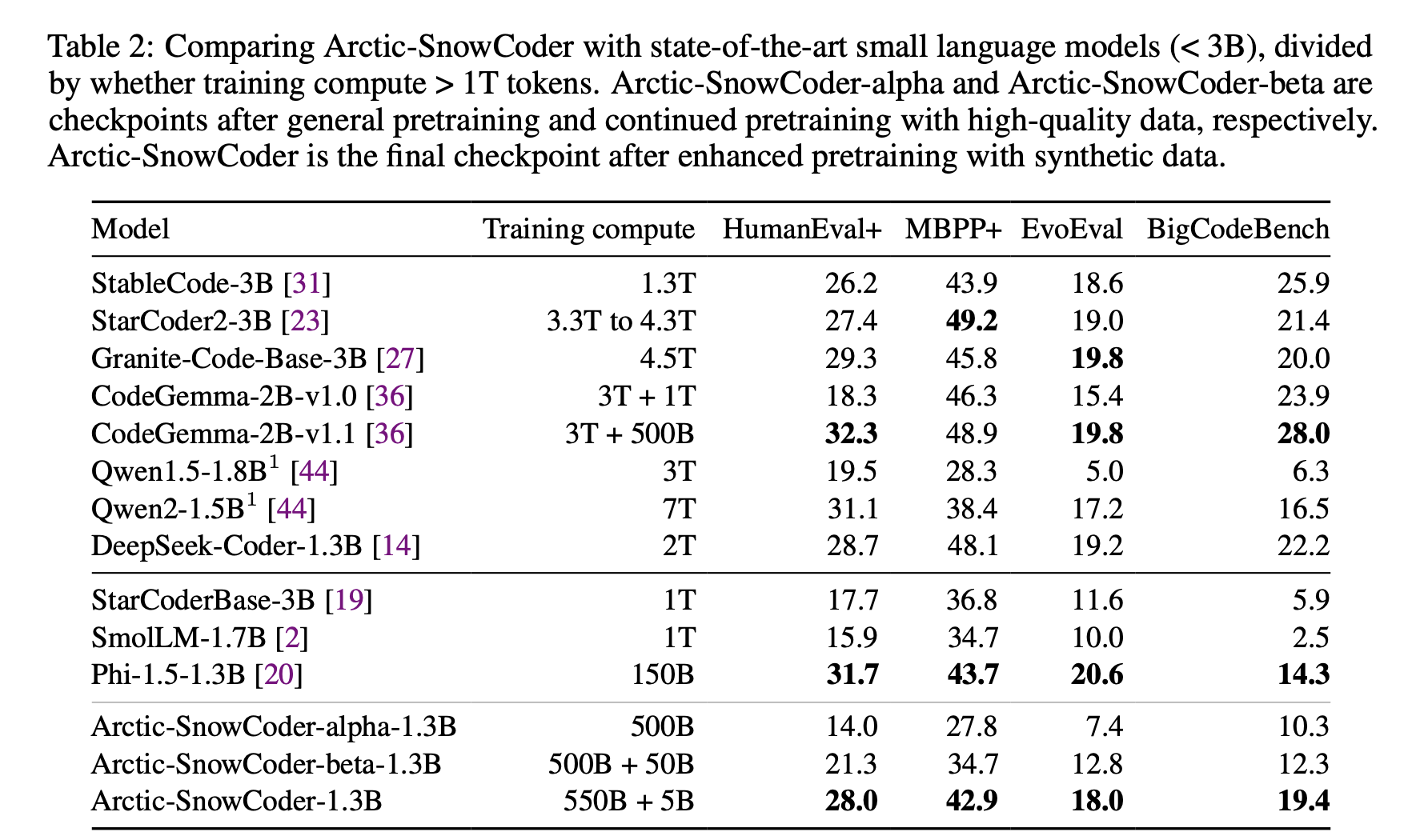
Исследовательская группа из Snowflake AI Research, University of Illinois at Urbana-Champaign и Seoul National University представила Arctic-SnowCoder-1.3B, новый подход к предварительному обучению моделей кода, путем постепенного улучшения качества данных за три различных фазы. Этот метод объединял общее предварительное обучение, продолжающееся предварительное обучение на высококачественных данных и окончательное предварительное обучение на синтетических данных. Исследователи использовали существующие наборы данных, такие как The Stack v1 и данные GitHub, а также искусственные данные, сгенерированные с использованием Llama-3.1-70B, для построения более маленькой и эффективной модели. Этот процесс сосредоточился на оптимизации данных, используемых в каждой фазе, чтобы гарантировать, что модель могла превзойти своих конкурентов.
В первой фазе Arctic-SnowCoder был обучен на 500 миллиардах токенов кода, полученных из источников необработанных данных, таких как The Stack v1 и GitHub. Эти данные прошли базовые этапы предварительной обработки, включая фильтрацию и удаление дубликатов, что привело к примерно 400 миллиардам уникальных токенов. Во время этой фазы модель обучалась без продвинутых фильтров качества, и данные были сгруппированы по языку программирования и репозиторию. Этот подход гарантировал широкую базу знаний о коде, но требовал дальнейшего уточнения. Во второй фазе исследовательская группа выбрала 50 миллиардов токенов из этого первоначального набора данных, сосредоточившись на высококачественных данных. Был использован аннотатор на основе BERT для ранжирования файлов с кодом, и лучшие 12,5 миллиарда токенов были повторены четыре раза для дальнейшего обучения модели. Это значительно улучшило качество данных, поскольку аннотатор был специально обучен для выбора токенов, соответствующих практическим задачам модели.
Окончательная фаза включала улучшенное предварительное обучение с использованием 5 миллиардов синтетических токенов, сгенерированных Llama-3.1-70B. Эти токены были созданы с использованием высококачественных данных из второй фазы в качестве исходных данных, превращая менее качественные данные в синтетические высококачественные документы. Эта фаза дополнительно улучшила способность модели генерировать точный код, обеспечивая, что обучающие данные были актуальны и представляли собой реальные задачи программирования. Результатом стала модель, которая прошла поэтапное более строгое обучение, причем каждая фаза способствовала улучшению ее производительности.
Значимость подхода Arctic-SnowCoder-1.3B
Эффективность этого подхода очевидна по результатам Arctic-SnowCoder-1.3B. Несмотря на обучение всего на 555 миллиардах токенов, он значительно превзошел другие модели схожего размера, такие как Phi-1.5-1.3B и StarCoderBase-3B, обученные на более чем 1 триллионе токенов. На практическом тесте BigCodeBench, который фокусируется на сложных задачах программирования, Arctic-SnowCoder превзошел производительность Phi-1.5-1.3B на 36%. Он превзошел StarCoder2-3B, обученную на более чем 3 триллионах токенов, на HumanEval+, достигнув оценки 28,0 по сравнению с 27,4 у StarCoder2-3B. Несмотря на обучение на меньшем количестве токенов, способность модели показать хорошие результаты подчеркивает важность качества данных перед количеством.
В заключение, Arctic-SnowCoder-1.3B иллюстрирует критическую роль постепенно улучшенных высококачественных данных в предварительном обучении моделей кода. Приняв трехфазный подход, исследователи значительно улучшили производительность модели по сравнению с более крупными моделями, обученными на гораздо большем количестве токенов. Этот метод демонстрирует важность согласования данных предварительного обучения с последующими задачами и предоставляет практические рекомендации для будущего развития моделей. Успех Arctic-SnowCoder является подтверждением ценности высококачественных данных, показывая, что тщательная кураторская работа с данными и генерация синтетических данных могут привести к существенным улучшениям в моделях генерации кода.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter и LinkedIn. Присоединяйтесь к нашему Telegram-каналу.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 50k+ ML SubReddit
«`

















