

«`html
Мультимодельные генеративные модели в искусственном интеллекте
Мультимодельные генеративные модели представляют собой захватывающий фронт в искусственном интеллекте, фокусирующийся на интеграции визуальных и текстовых данных для создания систем, способных выполнять различные задачи. Эти задачи варьируются от создания высокодетализированных изображений по текстовым описаниям до понимания и рассуждения по различным типам данных. Продвижения в этой области открывают новые возможности для более интерактивных и интеллектуальных систем искусственного интеллекта, способных бесшовно сочетать видение и язык.
Преодоление вызовов в области развития моделей AR
Одним из критических вызовов в этой области является разработка авторегрессионных (AR) моделей, способных генерировать фотореалистичные изображения по текстовым описаниям. В то время как модели диффузии сделали значительные шаги в этой области, AR модели исторически отстают, особенно в отношении качества изображений, гибкости разрешения и способности обрабатывать различные визуальные задачи. Этот разрыв подталкивает к необходимости инновационных подходов для расширения возможностей AR моделей.
Новаторский подход к генерации изображений
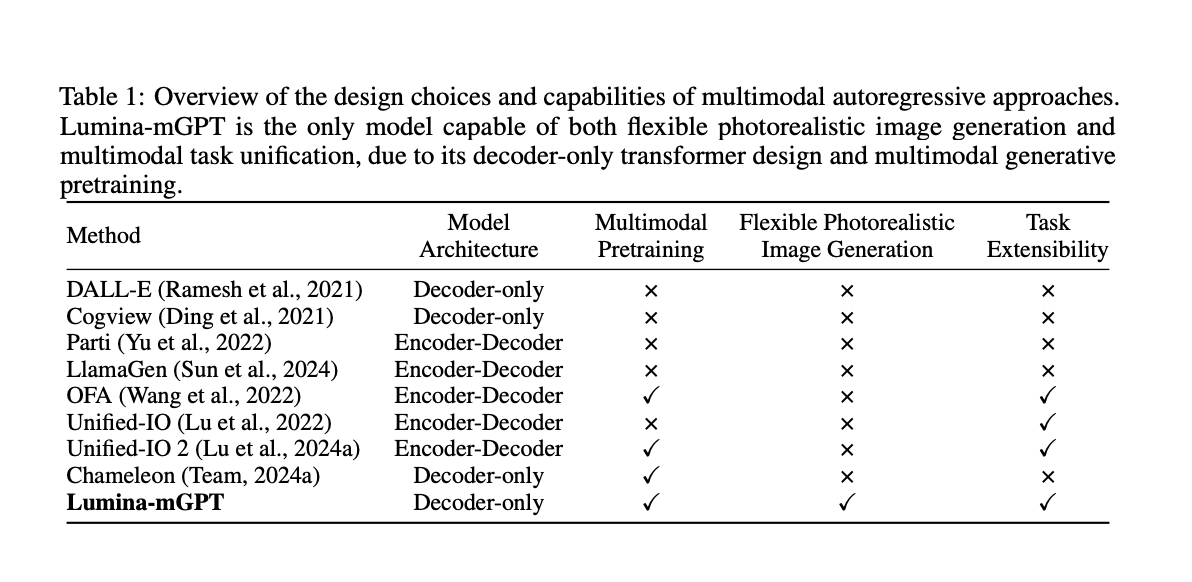
Исследователи из Shanghai AI Laboratory и Chinese University of Hong Kong представили Lumina-mGPT, передовую AR модель, разработанную для преодоления этих ограничений. Lumina-mGPT основана на архитектуре трансформера только с декодером с мультимодальным предварительным обучением (mGPT). Эта модель уникальным образом объединяет задачи видение-язык в единой структуре, нацеленной на достижение того же уровня генерации фотореалистичных изображений, что и модели диффузии, сохраняя простоту и масштабируемость методов AR.
Практическое применение и результаты
Lumina-mGPT продемонстрировала значительное улучшение в генерации фотореалистичных изображений по сравнению с предыдущими AR моделями. Модель поддерживает широкий спектр задач, включая визуальное вопросно-ответное взаимодействие, плотную разметку и управляемую генерацию изображений, показывая свою универсальность как мультимодальный генератор.
Для получения дополнительной информации ознакомьтесь с документом и GitHub.
Авторы исследования: Shanghai AI Laboratory и Chinese University of Hong Kong.
Следите за нашими новостями в Twitter и присоединяйтесь к нашей группе в Telegram.
«`



















