

«`html
Искусственный интеллект в области генерации аудио
Новая модель открытого текста-в-аудио от Stability AI
В области искусственного интеллекта открытые генеративные модели становятся основой для прогресса. Они важны для продвижения исследований и стимулирования творчества, позволяя настраивать и служа как эталоны для новых инноваций. Однако существует значительное препятствие, так как многие передовые модели текст-в-аудио остаются собственностью, ограничивая доступ исследователей.
Недавно команда исследователей из Stability AI представила новую открытую модель текст-в-аудио с открытыми весами, обученную исключительно на данных Creative Commons. Эта парадигма призвана гарантировать открытость и этичное использование данных, предлагая сообществу искусственного интеллекта мощный инструмент. Ее ключевые особенности:
- Открытые веса модели позволяют исследователям и разработчикам изучать, изменять и расширять модель, так как ее дизайн и параметры доступны широкой публике.
- Для обучения модели использовались только аудиофайлы с лицензией Creative Commons, гарантируя этичность и законность материалов.
Архитектура новой модели предназначена для создания доступного высококачественного синтеза аудио:
- Модель использует сложную архитектуру, обеспечивающую высокую достоверность генерации текста-в-аудио.
- В процессе обучения использовались разнообразные аудиофайлы с лицензией Creative Commons, гарантируя реалистичность и разнообразие аудиовыходов.
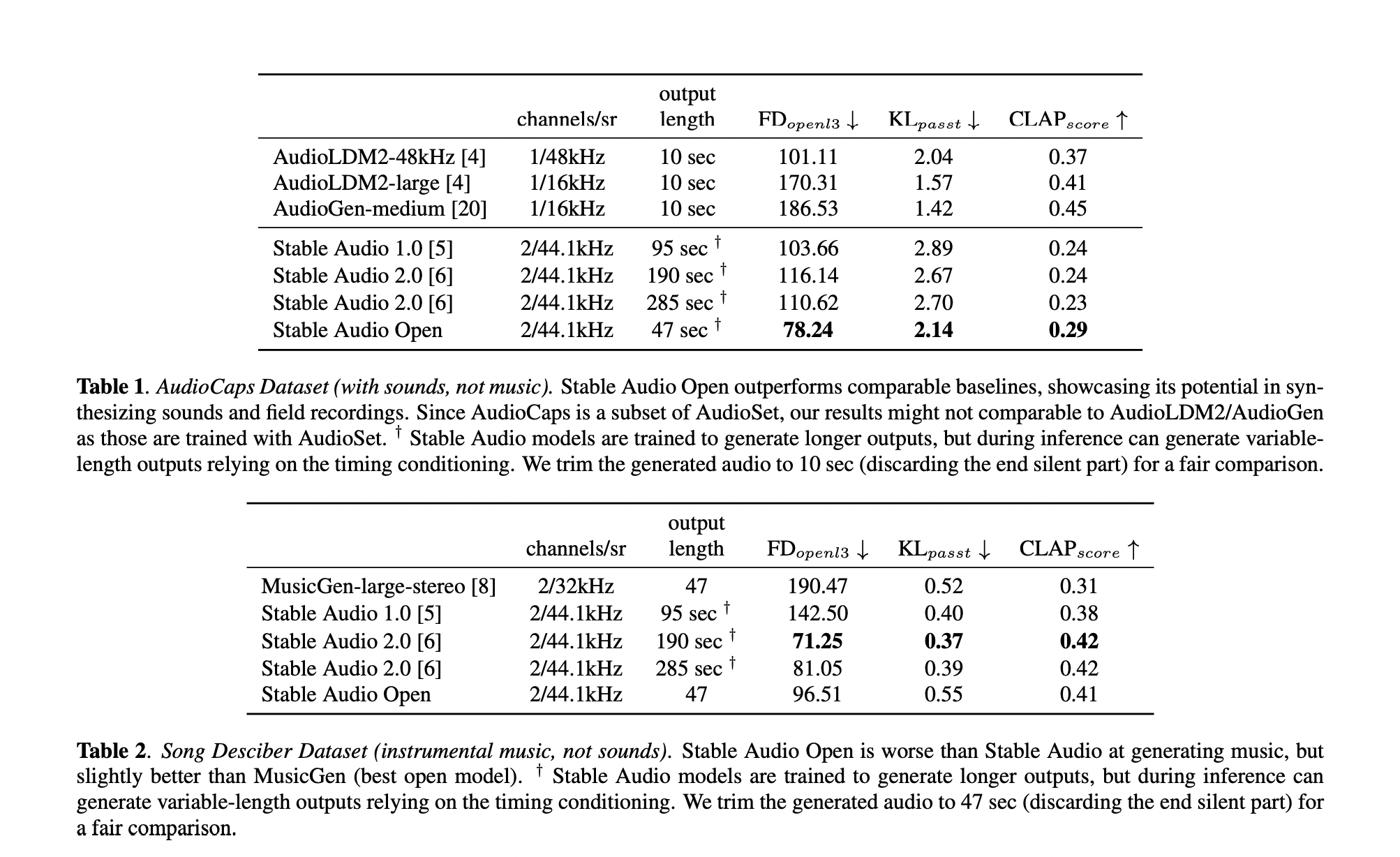
Для оценки производительности новой модели проведено тщательное изучение. Результаты показали, что она способна генерировать высококачественное аудио на уровне лучших моделей отрасли.
Развитие генеративной аудиотехнологии значительно продвинулось с выпуском этой открытой модели текст-в-аудио. Она устанавливает новые стандарты для производства текст-в-аудио и является значительным ресурсом для ученых, художников и разработчиков.
Больше информации о проекте, модели и GitHub можно найти здесь.
Все права на это исследование принадлежат исследователям проекта.
Не забудьте подписаться на наш Twitter и присоединиться к нашим каналам в Telegram и LinkedIn. Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу более чем 46 тыс. участников в ML SubReddit.
Следите за предстоящими вебинарами по ИИ здесь.
Статья опубликована на сайте MarkTechPost.