

«`html
Решения для обучения больших языковых моделей (LLMs)
Эффективность обучения при использовании WC-моделей
Критической задачей при обучении больших языковых моделей (LLM) для решения задач является определение наиболее эффективного метода генерации синтетических данных, который улучшает производительность модели. Традиционно, для создания высококачественных синтетических данных для настройки использовались более мощные и дорогие языковые модели (SE-модели). Однако этот подход требует больших ресурсов и ограничивает объем данных, генерируемых в рамках фиксированного вычислительного бюджета.
Текущие методы для улучшения способностей LLM включают в себя стратегии, такие как дистилляция знаний, где более маленькая модель учится у большой, и самоулучшение, где модели обучаются на данных, которые они генерируют сами. Однако эти методы имеют существенные недостатки, такие как высокие вычислительные затраты, которые ограничивают объем и разнообразие производимых данных, что потенциально влияет на охват и эффективность обучения.
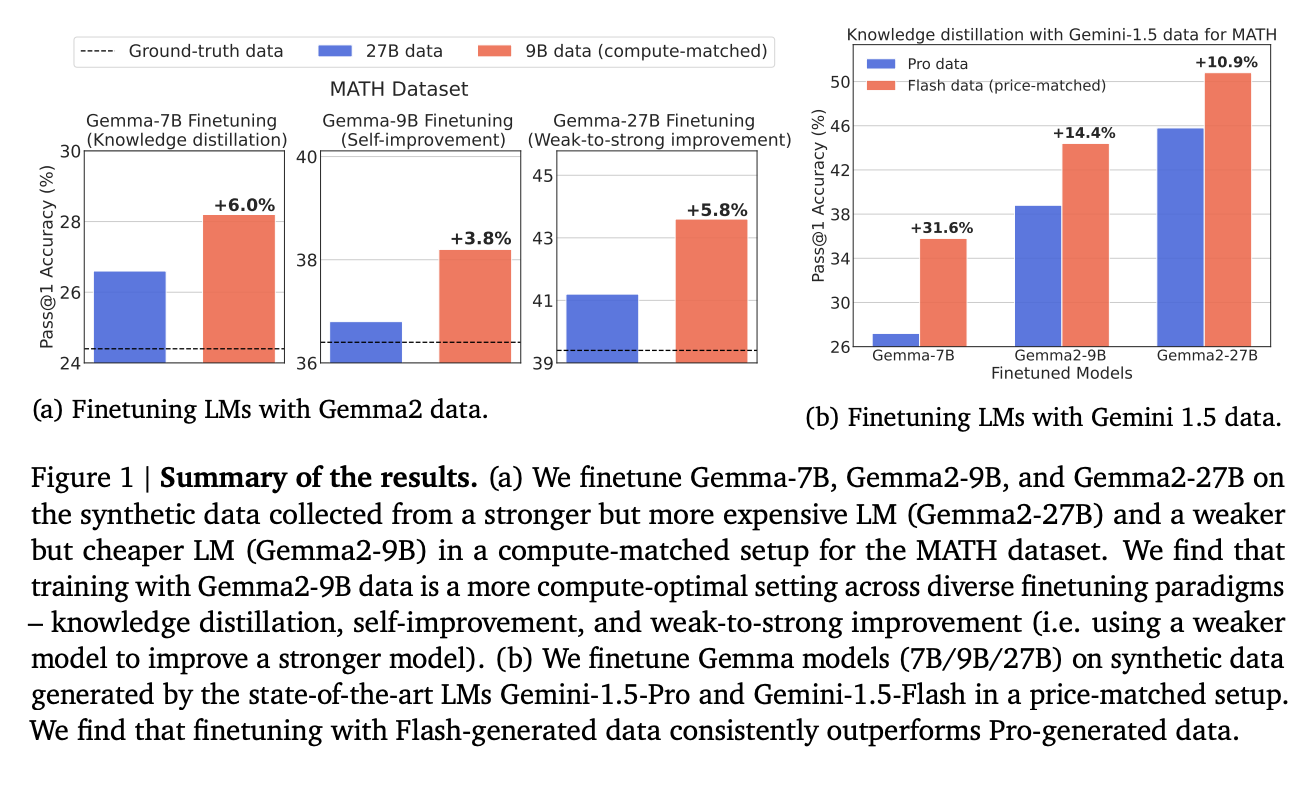
Исследователи из Google DeepMind предлагают новый подход, призывая использовать WC-модели, которые, несмотря на их низкое качество, являются более экономичными и позволяют генерировать больший объем данных в рамках того же вычислительного бюджета. Эта стратегия оценивается по ключевым показателям: охват, разнообразие и уровень ложноположительных результатов (FPR). Результаты показывают, что данные, сгенерированные WC-моделью, несмотря на более высокий уровень FPR, предлагают больший охват и разнообразие по сравнению с данными, сгенерированными SE-моделью. Исследование также представляет парадигму улучшения «слабое-к-сильному», где более мощная модель улучшается с использованием данных, сгенерированных более слабой моделью. Протестированный метод показывает преимущество перед традиционными подходами.
Значительное улучшение производительности LLM наблюдается на различных бенчмарках. Настройка моделей на данных, сгенерированных WC-моделями, последовательно дает лучшие результаты, чем у моделей, обученных на данных от SE-моделей. Несмотря на более высокий уровень ложноположительных результатов, более широкий спектр правильных решений и увеличенное покрытие проблем, предлагаемые WC-моделями, приводят к более эффективной производительности для настроенных моделей.
Использование WC-моделей для генерации синтетических данных оказывается более эффективным с точки зрения использования ресурсов, чем полагание на SE-модели. Генерация более разнообразных и комплексных обучающих данных WC-моделями позволяет обучение более мощных LLM разработок.
«`



















