

«`html
Оценка качества разговорных помощников на основе искусственного интеллекта
Оценка разговорных помощников на базе искусственного интеллекта, таких как GitHub Copilot Chat, представляет собой сложную задачу из-за их зависимости от языковых моделей и интерфейсов на основе чата. Существующие метрики качества разговора нуждаются в пересмотре для диалогов, специфичных для области, что затрудняет оценку эффективности этих инструментов разработки программного обеспечения. Техники, такие как SPUR, используют большие языковые модели для анализа удовлетворенности пользователя, но они могут упускать специфические для области нюансы. Данное исследование сосредотачивается на автоматическом создании высококачественных, задачно-ориентированных рубрик для оценки разговорных помощников на основе искусственного интеллекта, акцентируя важность контекста и прогресса задач для улучшения точности оценки.
Техника RUBICON для оценки диалогов человек-ИИ
Исследователи из Microsoft представляют технику RUBICON для оценки диалогов человек-ИИ в специфической области с использованием больших языковых моделей. RUBICON генерирует кандидатов для оценки качества разговора и выбирает наилучшие. Он улучшает SPUR, интегрируя специфические для области сигналы и максимы Грайса, создавая пул рубрик, оцениваемых итеративно. RUBICON был протестирован на 100 разговорах между разработчиками и чат-ассистентом для отладки на C#, используя GPT-4 для генерации и оценки рубрик. Он превзошел альтернативные наборы рубрик, достигнув высокой точности в предсказании качества разговора и продемонстрировав эффективность своих компонентов через исследования абляции.
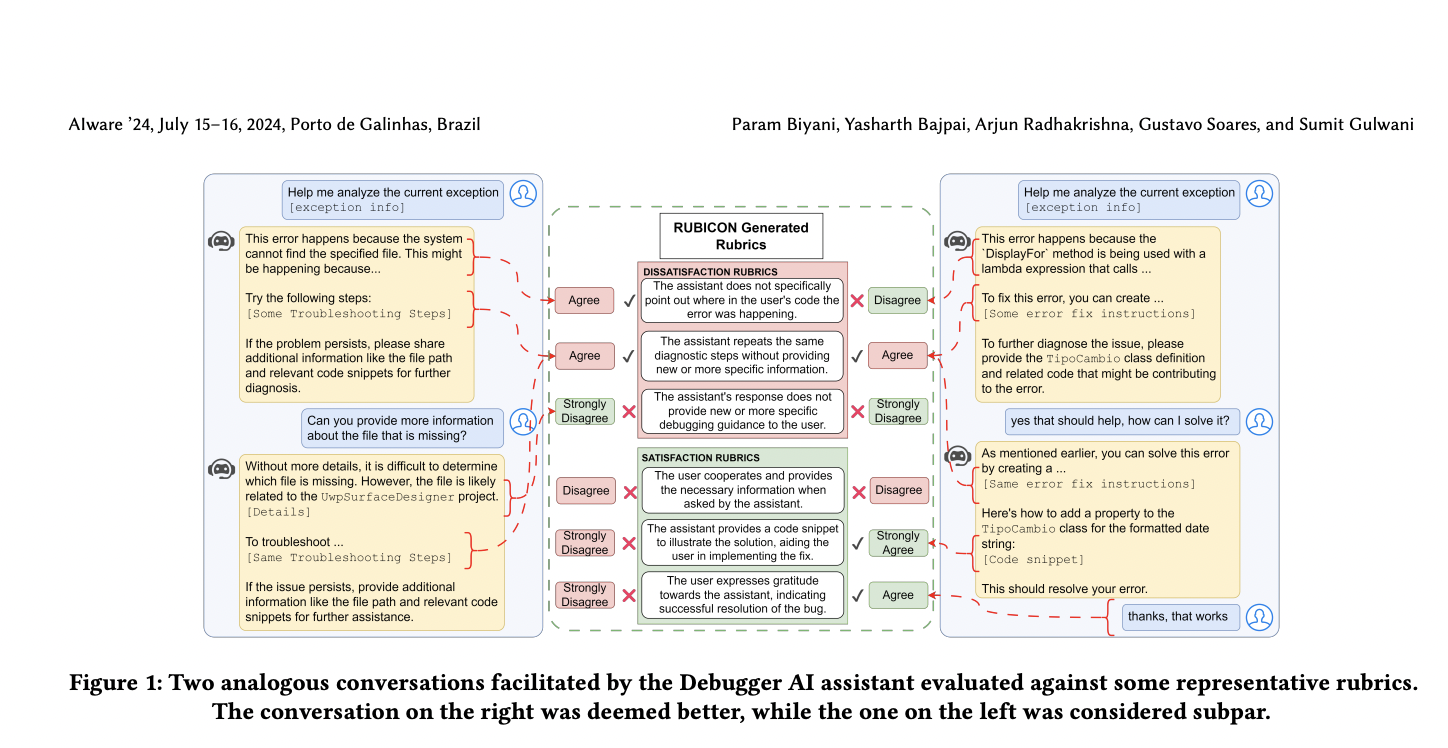
Оценка качества разговоров с помощью RUBICON
RUBICON оценивает качество разговоров для специфических областных ассистентов, изучая рубрики удовлетворения (SAT) и неудовлетворения (DSAT) на основе помеченных диалогов. Он включает три этапа: генерацию разнообразных рубрик, выбор оптимизированного набора рубрик и оценку разговоров. Рубрики представляют собой утверждения естественного языка, захватывающие атрибуты разговора. Разговоры оцениваются с использованием 5-балльной шкалы Ликерта, нормализованной до диапазона [0, 10]. Генерация рубрик включает надзорное извлечение и суммирование, а выбор оптимизирует рубрики для точности и охвата. Потери правильности и четкости направляют выбор оптимального поднабора рубрик, обеспечивая эффективную и точную оценку качества разговора.
Оценка эффективности RUBICON и перспективы развития
Оценка RUBICON включает три ключевых вопроса: его эффективность по сравнению с другими методами, влияние Доменной Сенсибилизации (DS) и Принципов Дизайна Разговора (CDP), а также производительность его политики выбора. Результаты показали, что RUBICON превосходит базовые показатели в разделении положительных и отрицательных разговоров и классификации разговоров с высокой точностью, подчеркивая важность инструкций DS и CDP.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`



















