

«`html
Эффективное вычисление скрытых представлений запросов и элементов для приближения оценок CE
Кросс-кодировщики (CE) оценивают сходство, одновременно кодируя пару запрос-элемент, превосходя dot-product с моделями на основе вложений при оценке релевантности запроса-элемента. Текущие методы выполняют поиск k-NN с CE, аппроксимируя CE сходство с пространством векторных вложений, соответствующим двойным кодировщикам (DE) или факторизацией матрицы CUR. Однако методы на основе DE сталкиваются с проблемами низкой полноты из-за плохой обобщенности новых доменов и отделения поиска времени тестирования от CE. Таким образом, методы на основе DE и CUR недостаточны для определенной настройки приложения в поиске k-NN.
Матричная факторизация
Матричная факторизация широко используется для оценки низкорангового приближения плотных расстояний и матриц, не положительно определенных матриц и отсутствующих записей в разреженных матрицах. В данной статье исследователи изучили методы факторизации разреженных матриц вместо плотных матриц. Важным предположением для методов завершения матрицы является то, что базовая матрица M имеет низкий ранг, что помогает восстановить отсутствующие записи путем анализа небольшой доли записей в M. Кроме того, когда доступны признаки, описывающие строки и столбцы матрицы, сложность выборки, используемой в этом методе для восстановления матрицы размером m × n ранга r с m ≤ n, может быть улучшена.
Практическое применение
Исследователи из Университета Массачусетса в Амхерсте и Google DeepMind представили новый метод на основе факторизации разреженной матрицы. Этот метод оптимально вычисляет скрытые представления запроса и элемента для приближения оценок CE и выполняет поиск kNN с использованием приближенного CE сходства. По сравнению с методами на основе CUR, предложенный метод генерирует высококачественное приближение с использованием доли вызовов CE сходства. Факторизация разреженной матрицы, содержащей оценки CE запроса-элемента, выполняется для оценки вложений элементов, и это пространство вложений инициируется с использованием моделей DE.
Эксперименты и результаты
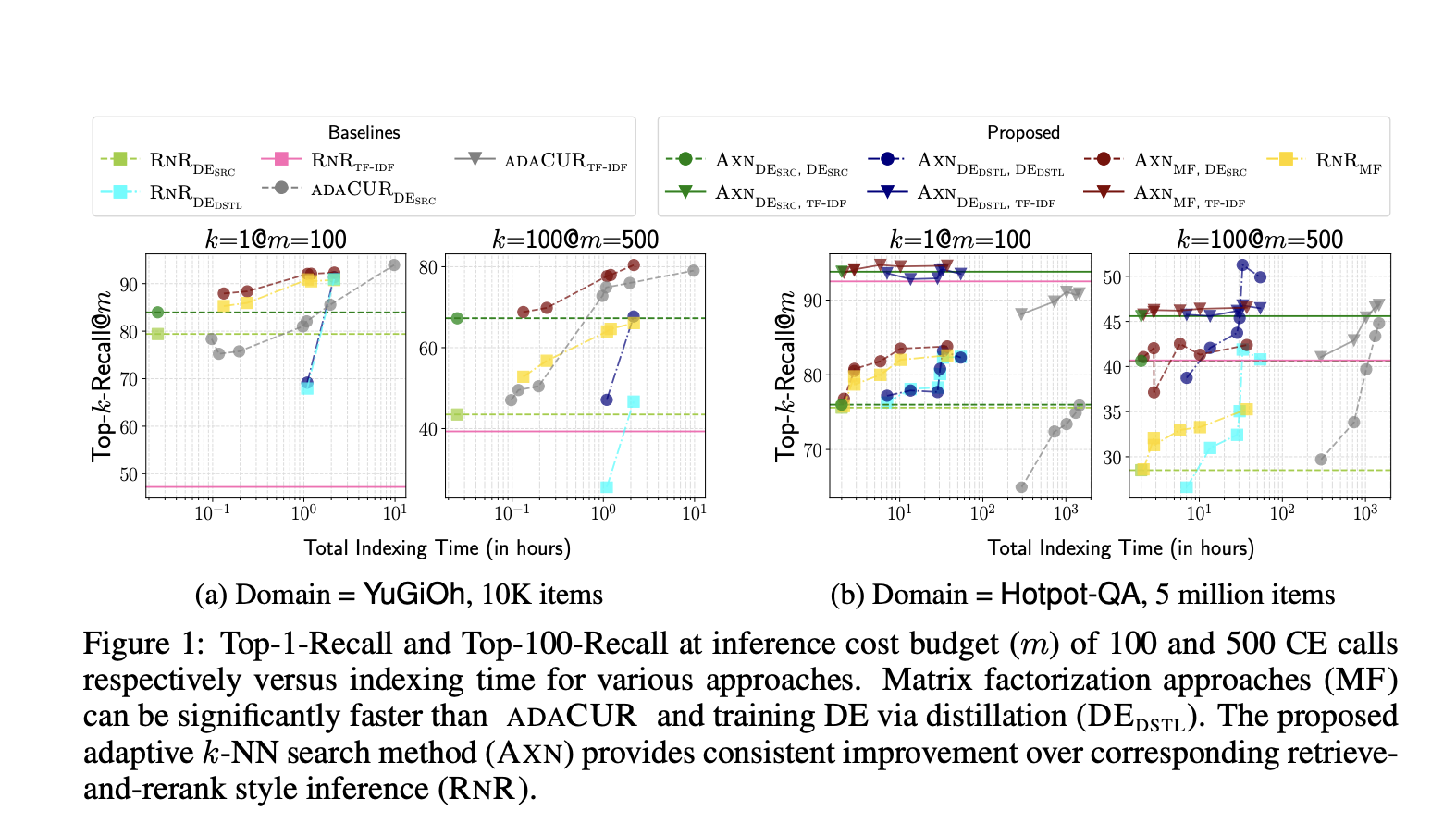
Методы и базовые значения тщательно оцениваются на задачах, таких как поиск k-ближайших соседей для моделей CE и последующие задачи. Важно отметить, что модели CE используются для задач, таких как связывание сущностей без обучения и информационный поиск без обучения, демонстрируя, как различные решения влияют на время индексации данных и точность поиска во время тестирования. Эксперименты проводятся на двух наборах данных, ZESHEL и BEIR, где для обоих наборов данных используются отдельные модели CE, обученные на данных с истинными метками. Используются два тестовых домена из ZESHEL с 10 тыс. и 34 тыс. элементов (сущностей) и два тестовых домена из BEIR с 25 тыс. и 5 млн элементов (документов).
Заключение
Исследователи из Университета Массачусетса в Амхерсте и Google DeepMind представили метод на основе факторизации разреженной матрицы, который эффективно вычисляет скрытые представления запроса и элемента. Этот метод оптимально выполняет поиск k-NN с кросс-кодировщиками, эффективно аппроксимируя оценки кросс-кодировщика с помощью скалярного произведения изученных тестовых запросов и элементов. Также в эксперименте использовались два набора данных, ZESHEL и BEIR, и для обоих использовались отдельные модели CE, обученные на данных с истинными метками.
Подробнее ознакомьтесь с статьей. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 42k+ ML SubReddit.
Источник: MarkTechPost.
«`


















