

«`html
Прогрессивная система обучения для улучшения рассуждений искусственного интеллекта через слабое-к-сильному наблюдению
По мере того как крупные языковые модели превосходят возможности человека, обеспечение точного наблюдения становится все сложнее. Метод слабого-к-сильному обучению, который использует менее способную модель для улучшения более сильной, предлагает потенциальные преимущества, но требует тестирования для сложных задач рассуждения. Этот метод в настоящее время не обладает эффективными техниками для предотвращения имитации более сильной моделью ошибок менее способной модели. По мере продвижения искусственного интеллекта к искусственному общему интеллекту (AGI), создание сверхинтеллектуальных систем вносит значительные вызовы, особенно в области наблюдения и парадигм обучения. Традиционные методы, основанные на человеческом контроле или руководстве продвинутой модели, становятся недостаточными по мере того, как возможности искусственного интеллекта превосходят возможности их наблюдателей.
Практические решения и ценность
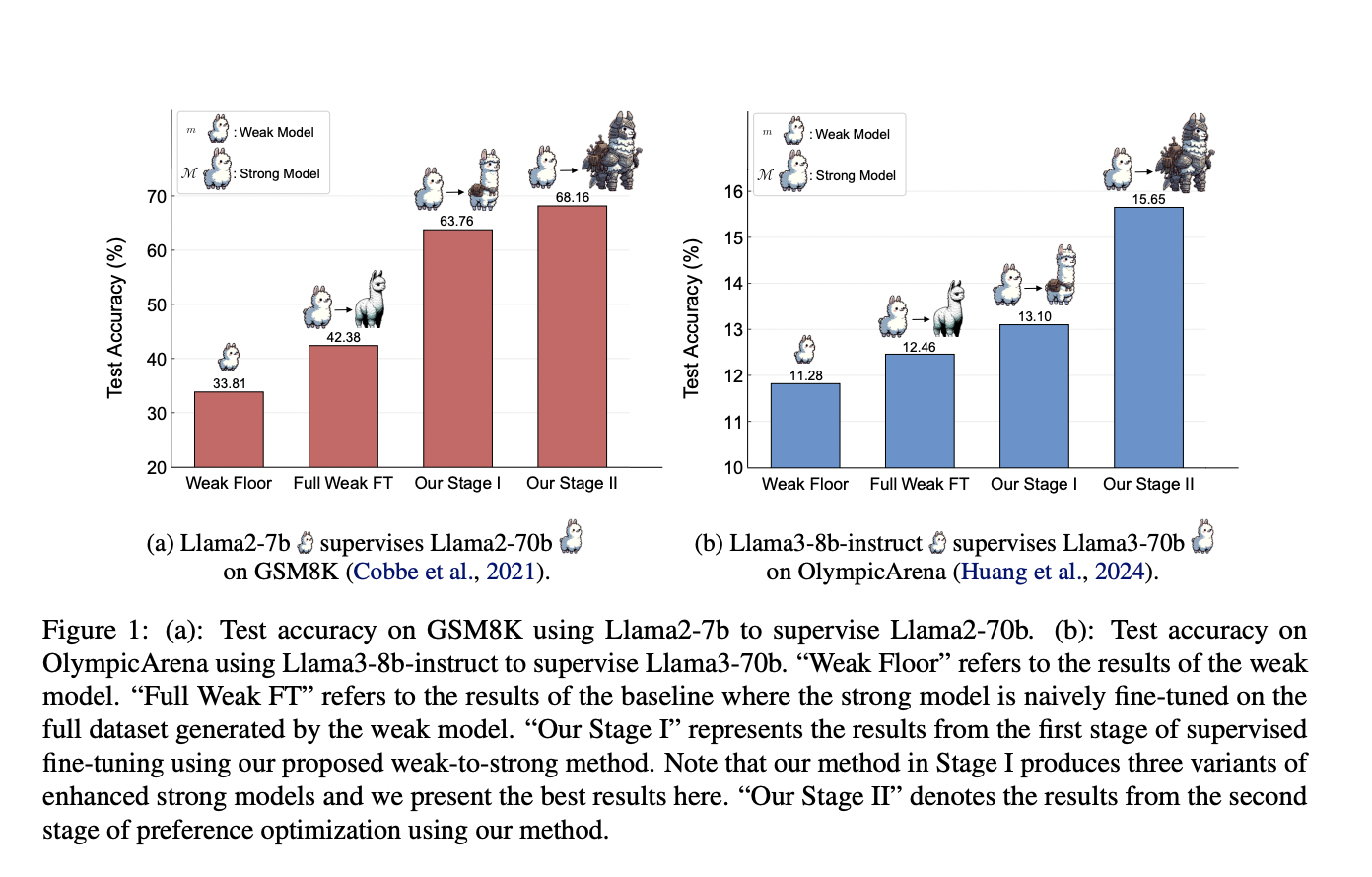
Исследователи из Университета Шанхайского Цзяотун, Университета Фудан, Шанхайской лаборатории искусственного интеллекта и GAIR разработали прогрессивную систему обучения, которая позволяет сильным моделям автономно улучшать свои обучающие данные. Этот подход начинается с надзорной доводки на небольшом высококачественном наборе данных, за которой следует оптимизация предпочтений с использованием контрастных образцов, выявленных сильной моделью. Эксперименты на наборах данных GSM8K и MATH показывают значительное улучшение способностей к рассуждению Llama2-70b при использовании трех различных слабых моделей. Эффективность системы демонстрируется дополнительно с помощью Llama3-8b-instruct, наблюдающей за Llama3-70b на сложном наборе данных OlympicArena, что открывает путь к улучшенным стратегиям рассуждения искусственного интеллекта.
LLM улучшают решение задач и соответствие инструкциям человека через надзорную доводку (SFT), которая зависит от высококачественных обучающих данных для существенного повышения производительности. Это исследование рассматривает потенциал обучения от слабого наблюдения. Для выравнивания LLM с человеческими ценностями также требуются RLHF и прямая оптимизация предпочтений (DPO). DPO упрощает репараметризацию функций вознаграждения в RLHF и имеет различные стабильные и производительные варианты, такие как ORPO и SimPO. В математическом рассуждении исследователи фокусируются на методах подсказок и создании высококачественных вопросно-ответных пар для надзорной доводки, что значительно улучшает способности к решению проблем.
Метод обучения от слабого к сильному направлен на максимизацию использования слабых данных и улучшение способностей сильной модели. На этапе I потенциально положительные образцы выявляются без истинного значения и используются для надзорной доводки. Этап II включает использование полных слабых данных, сосредотачиваясь на потенциально отрицательных образцах с помощью подходов, основанных на предпочтениях обучения, таких как DPO. Этот метод улучшает сильную модель путем изучения ошибок слабой модели. Ответы сильной модели выбираются, и уровни уверенности используются для определения надежных ответов. Создаются контрастные образцы для дальнейшего обучения, помогая сильной модели различать правильные и неправильные решения, что приводит к улучшению модели.
Эксперименты используют наборы данных GSM8K и MATH, с подмножествами Dgold,1 и Dgold,2, используемыми для обучения слабых и сильных моделей. Начальное обучение на GSM8K было улучшено с использованием дополнительных данных, в то время как данные MATH столкнулись с ограничениями из-за их сложности. Итерационная доводка улучшила слабые модели, что в свою очередь повысило производительность сильной модели. С использованием методов предпочтения обучения были замечены значительные улучшения, особенно на GSM8K. Дальнейший анализ показал лучшую обобщенность на более простых задачах. Тесты с моделями Llama3 на OlympicArena, более сложном наборе данных, продемонстрировали, что предложенный метод обучения от слабого к сильному эффективен и масштабируем в реалистичных сценариях.
В заключение, исследование исследует эффективность прогрессивной системы обучения в сложных задачах рассуждения, представляя метод, который использует слабое наблюдение для развития сильных способностей без участия человека или продвинутых моделей. Сильная модель улучшает свои обучающие данные независимо, даже без предварительных знаний о задаче, постепенно улучшая свои навыки рассуждения через итеративное обучение. Эта самостоятельная кураторская работа с данными является важной для развития способностей рассуждения искусственного интеллекта, способствуя независимости и эффективности модели. Исследование подчеркивает роль инновационного наблюдения за моделью в развитии искусственного интеллекта, особенно для AGI. Ограничения включают использование текущих моделей в качестве замен будущих продвинутых моделей и вызовы, вызванные ошибками и шумом в наблюдении на уровне процесса.
Проверьте статью и репозиторий на GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Твиттер и присоединиться к нашему каналу в Телеграме и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
Найдите предстоящие вебинары по искусственному интеллекту здесь.
Опубликовано на MarkTechPost.