

«`html
Новый подход к синтезу речи: MELLE
В области крупных языковых моделей (LLM) произошло значительное изменение в генерации текста, что побудило исследователей изучать их потенциал в аудио-синтезе. Однако адаптация этих моделей для задач текст в речь (TTS) с высоким качеством вывода представляет собой определенные трудности. Существующие методики, такие как языковые модели с нейронным кодеком, например VALL-E, сталкиваются с ограничениями, включая более низкую точность по сравнению с мел-спектрограммами, проблемы устойчивости, возникающие из стратегий случайной выборки, и необходимость в сложных двухпроходных процессах декодирования. Эти препятствия затрудняют эффективность и качество аудио-синтеза, особенно в задачах zero-shot TTS, требующих мультиязычных, мультиспикерных и мультидоменных возможностей.
Практические решения
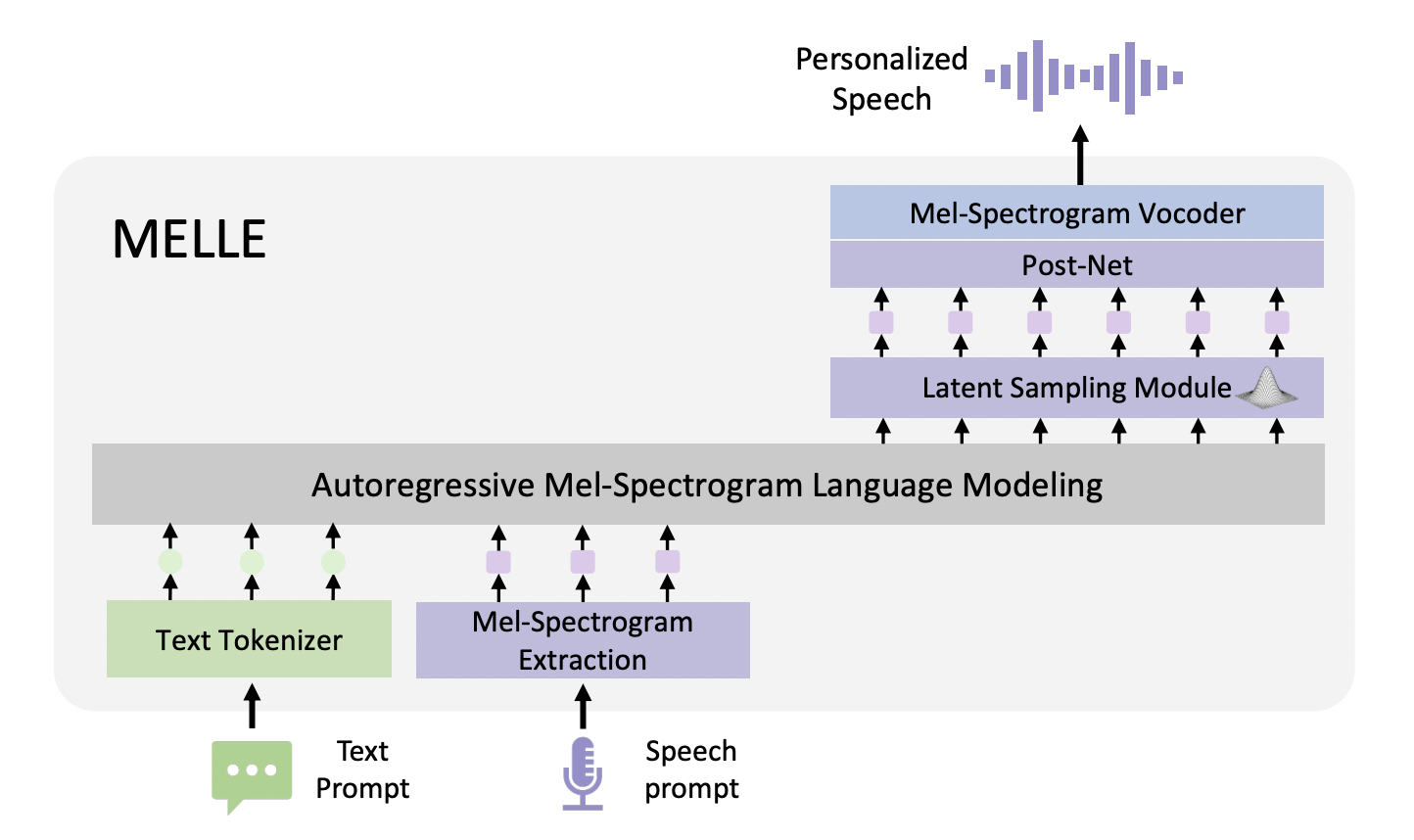
Модель MELLE представляет собой значительное достижение в zero-shot синтезе текста в речь, используя непрерывное представление звука на основе токенов мел-спектрограмм. Она может преодолеть ограничения дискретных кодеков, генерируя непрерывные кадры мел-спектрограммы напрямую из текстового ввода. Модель способна авторегрессивно предсказывать кадры мел-спектрограммы, устраняя проблемы устойчивости, связанные с выбором дискретных кодов, и предлагает улучшенную точность и эффективность синтеза речи.
Применение в бизнесе
Внедрение решений на основе MELLE может привести к улучшению процессов и качества в области синтеза речи. Эффективное использование ИИ в сфере продаж и маркетинга может значительно повысить эффективность и результативность компании, обеспечивая конкурентное преимущество на рынке.
Дальнейшие шаги
Если вам нужны советы по внедрению ИИ в ваш бизнес, пишите нам на Telegram. Следите за новостями о ИИ в нашем Телеграм-канале itinainews или в Twitter @itinairu45358.
«`



















