

«`html
FocusLLM: A Scalable AI Framework for Efficient Long-Context Processing in Language Models
Усиление способностей моделей с длинным контекстом (LLM) для эффективной работы с большими объемами текста является важным для многих приложений, но традиционные трансформеры требуют значительных ресурсов для обработки длинных контекстов. Длинные контексты улучшают задачи, такие как резюмирование документов и ответы на вопросы. Однако возникает несколько проблем: квадратичная сложность трансформеров увеличивает затраты на обучение, LLM требуют помощи с более длинными последовательностями даже после настройки, и сложно получить высококачественные наборы данных для длинных текстов.
Решение проблемы
Для решения этих проблем были исследованы методы, такие как модификация механизмов внимания или сжатие токенов, но они часто приводят к потере информации, затрудняя точные задачи, такие как верификация и ответы на вопросы.
Представление FocusLLM
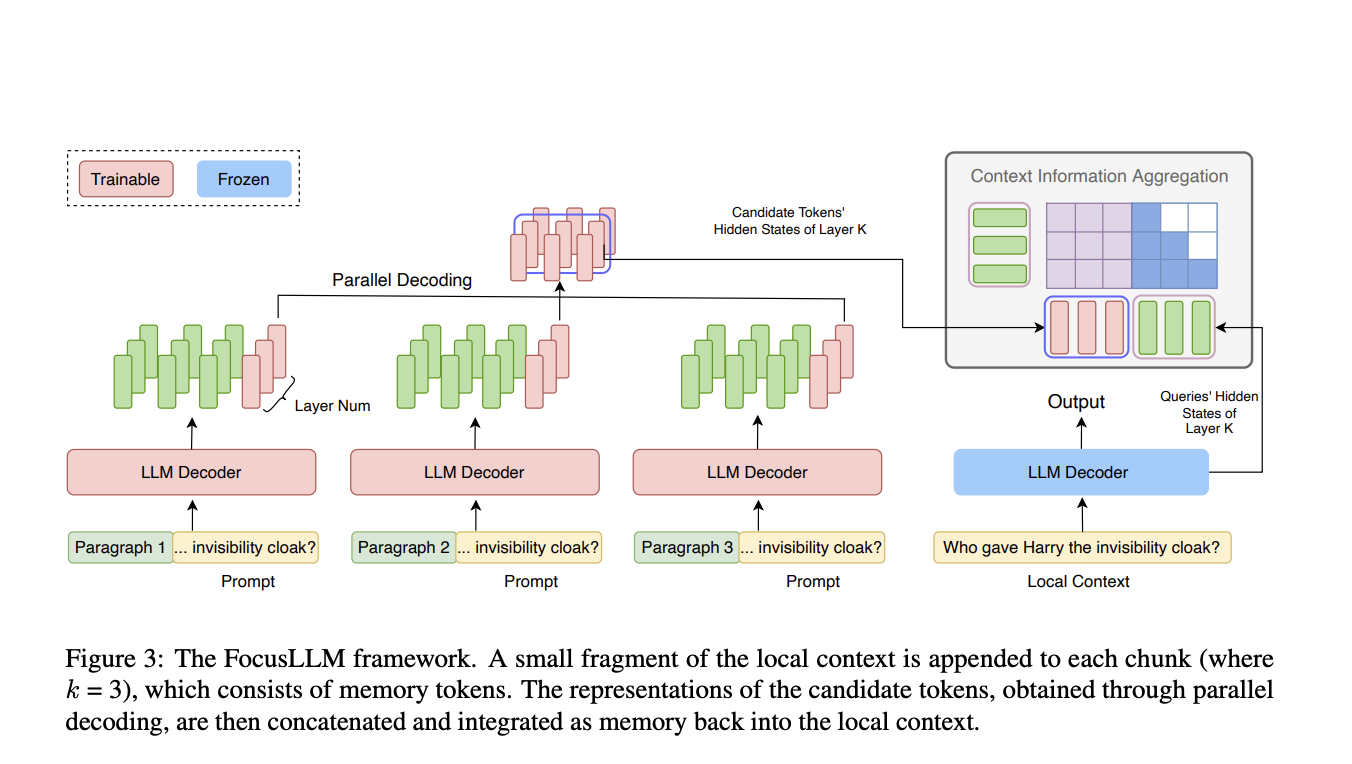
Исследователи из университетов Цинхуа и Сямэнь представили FocusLLM — фреймворк, разработанный для расширения длины контекста LLM только декодерами. FocusLLM делит длинный текст на части и использует параллельный механизм декодирования для извлечения и интеграции соответствующей информации. Этот подход улучшает эффективность обучения и универсальность, позволяя LLM обрабатывать тексты длиной до 400 тыс. токенов с минимальными затратами на обучение. FocusLLM превосходит другие методы в задачах, таких как ответы на вопросы и понимание длинных текстов, демонстрируя превосходную производительность на тестах Longbench и ∞-Bench при сохранении низкой перплексии на обширных последовательностях.
Практическое применение
Недавние достижения в моделировании длинного контекста представили различные подходы для преодоления ограничений трансформеров. Методы экстраполяции длины, такие как позиционная интерполяция, направлены на адаптацию трансформеров к более длинным последовательностям, но часто сталкиваются с отвлекающими элементами от шумного контента. Другие методы, модифицирующие механизмы внимания или использующие сжатие для обработки длинных текстов, не удается эффективно использовать все токены. Модели с улучшенной памятью повышают понимание длинного контекста путем интеграции информации в постоянную память или кодирования и запроса длинных текстов по сегментам. Однако эти методы сталкиваются с ограничениями в экстраполяции длины памяти и высокими вычислительными затратами, тогда как FocusLLM достигает большей эффективности обучения и эффективности на чрезвычайно длинных текстах.
Методология
Методология FocusLLM заключается в адаптации архитектуры LLM для обработки крайне длинных последовательностей текста. FocusLLM разбивает вход на части, каждая из которых обрабатывается расширенным декодером с дополнительными обучаемыми параметрами. Локальный контекст добавляется к каждой части, что позволяет параллельное декодирование, при этом кандидаты на токены генерируются одновременно по частям. Этот подход существенно уменьшает вычислительную сложность, особенно с длинными последовательностями. Обучение FocusLLM использует авторегрессионную функцию потерь, фокусирующуюся на предсказании следующего токена, и использует две функции потерь — функцию продолжения и функцию повторения — для улучшения способности модели обрабатывать различные размеры частей и контексты.
Оценка эффективности
Оценка FocusLLM подчеркивает его высокую производительность в языковом моделировании и задачах на уровне, особенно с входами длинного контекста. Обученный эффективно на 8×A100 GPUs, FocusLLM превосходит LLaMA-2-7B и другие методы без настройки, поддерживая стабильную перплексию даже с длинными последовательностями. На задачах на уровне, используя наборы данных Longbench и ∞-Bench, он превзошел модели, такие как StreamingLLM и Activation Beacon. Дизайн FocusLLM, оснащенный параллельным декодированием и эффективной обработкой частей, позволяет ему эффективно обрабатывать длинные последовательности без вычислительной нагрузки других моделей, делая его очень эффективным решением для задач с длинным контекстом.
Вывод
FocusLLM представляет фреймворк, значительно расширяющий длину контекста LLM за счет использования параллельной стратегии декодирования. Этот подход разделяет длинные тексты на управляемые части, извлекая важную информацию из каждой и интегрируя ее в контекст. FocusLLM превосходит другие модели в задачах на уровне, поддерживая при этом низкую перплексию, даже с последовательностями длиной до 400 тыс. токенов. Его дизайн позволяет добиться замечательной эффективности обучения, обеспечивая обработку длинного контекста с минимальными вычислительными и памятными затратами. Этот фреймворк предлагает масштабируемое решение для улучшения LLM, делая его ценным инструментом для приложений с длинным контекстом.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям данного проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам понравилась наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему сабреддиту по машинному обучению с более чем 49 тыс. участников.
Найдите предстоящие вебинары по ИИ здесь.
The post FocusLLM: A Scalable AI Framework for Efficient Long-Context Processing in Language Models appeared first on MarkTechPost.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте FocusLLM: A Scalable AI Framework for Efficient Long-Context Processing in Language Models .
Практическое применение ИИ в бизнесе
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI. Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями об ИИ в нашем Телеграм-канале https://t.me/aisalesbotnews
Попробуйте AI Sales Bot https://saile.ru/. Это AI ассистент для продаж, он помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить процесс продаж в вашей компании с решением от saile.ru будущее уже здесь!
«`



















