

«`html
Преодоление проблемы обвала модели с усиленными синтетическими данными
С увеличением использования данных, сгенерированных искусственным интеллектом (ИИ), возникли опасения относительно ухудшения производительности модели при итеративном обучении на синтетических данных. Проблема обвала модели заключается в существенном ухудшении производительности модели при обучении на сгенерированных синтетических данных. Эта проблема затрудняет разработку эффективных методов создания качественных сводок больших объемов текстовых данных.
Практические решения:
Существующие методы борьбы с обвалом модели включают несколько подходов, таких как использование обучения с подкреплением с обратной связью от человека (RLHF), курирование данных и инженерия подсказок. RLHF использует обратную связь от человека для обеспечения качества данных, используемых для обучения, тем самым поддерживая или улучшая производительность модели. Однако этот подход дорогостоящий и не масштабируемый, так как сильно зависит от человеческих аннотаторов.
Другой метод заключается в тщательном курировании и фильтрации синтетических данных. Это может включать использование эвристик или предопределенных правил для отбрасывания низкокачественных или неактуальных данных перед их использованием для обучения. Хотя этот метод может помочь смягчить негативное влияние низкокачественных синтетических данных, он часто требует значительных усилий для поддержания качества обучающего набора данных и лишь отчасти уменьшает риск обвала модели, если критерии фильтрации достаточно надежны. Кроме того, инженерия подсказок — это техника, которая включает создание конкретных подсказок, направляющих модель на генерацию более качественных результатов. Этот метод не является 100% надежным и может быть ограничен встроенными предубеждениями и слабостями самой модели. Часто он требует экспертных знаний и итеративных экспериментов для достижения оптимальных результатов.
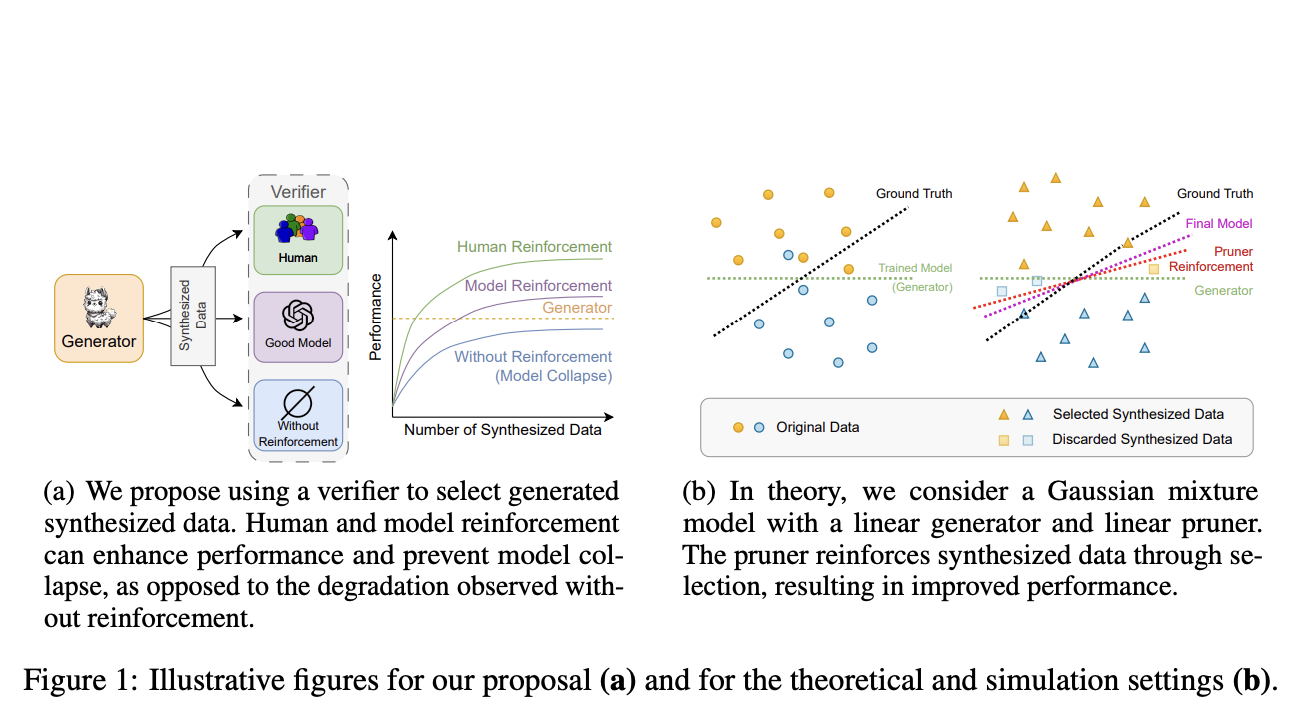
Для преодоления этих ограничений группа исследователей из Meta AI, NYU и Университета Пекина предлагает метод, включающий обратную связь по синтетическим данным с целью предотвращения обвала модели с помощью подкрепляющих методов. Их подход включает использование механизмов обратной связи для выбора или обрезки синтетических данных, обеспечивая использование только высококачественных данных для дальнейшего обучения. Этот метод представляется более эффективным и масштабируемым альтернативой RLHF, так как может быть частично или полностью автоматизирован.
Основа предлагаемой методики заключается в улучшении синтетических данных с помощью механизмов обратной связи, которые могут быть от человека или других моделей. Исследователи предоставляют теоретическую основу, демонстрирующую, что модель классификации смеси Гаусса может достигнуть оптимальной производительности при обучении на усиленных обратной связью синтетических данных.
Два практических эксперимента подтверждают теоретические предсказания. Первый эксперимент заключается в обучении трансформеров для вычисления собственных значений матрицы, задачи, которая сталкивается с обвалом модели при обучении на чисто синтетических данных. Производительность модели значительно улучшается путем обрезки неправильных предсказаний и выбора лучших догадок из синтетических данных, демонстрируя эффективность усиления через выбор данных. Второй эксперимент фокусируется на резюмировании новостей с использованием больших языковых моделей (LLM) таких как LLaMA-2. Здесь усиленные обратной связью данные предотвращают ухудшение производительности, даже когда объем синтетических данных увеличивается, поддерживая гипотезу о том, что подкрепление критично для поддержания целостности модели.
Исследователи используют стратегию декодирования для генерации сводок и оценивают их производительность с помощью метрики Rouge-1. Они также используют мощную модель-проверяющий, Llama-3, для выбора лучших синтетических данных для обучения. Результаты показывают, что предлагаемый метод значительно превосходит исходную модель, обученную на полном наборе данных, даже при использовании только 12,5% данных. Было замечено, что модель, обученная на синтетических данных, выбранных оракулом, достигает лучшей производительности, что указывает на то, что предлагаемый метод эффективно уменьшает обвал модели. Это значительное открытие, так как оно подразумевает, что при правильном усилении высококачественные синтетические данные могут соответствовать и потенциально превосходить качество данных, созданных человеком.
Исследование предлагает многообещающее решение проблемы обвала модели в LLM, обучаемых на синтетических данных. Путем внедрения механизмов обратной связи для улучшения качества синтетических данных предлагаемый метод обеспечивает устойчивую производительность модели без необходимости обширного вмешательства человека. Этот подход представляет собой масштабируемую и экономически выгодную альтернативу текущим методам RLHF, что открывает путь для более надежных и надежных систем ИИ в будущем.
Подробнее см. Paper. Вся заслуга за это исследование принадлежит исследователям проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в SubReddit.
Источник: MarkTechPost.
«`



















