

«`html
Введение
Математическое мышление представляет собой серьезную задачу для больших языковых моделей (LLM). Ошибки на промежуточных этапах могут снизить точность и надежность конечных результатов, что особенно важно в таких областях, как образование и научные вычисления.
Проблемы традиционных методов оценки
Традиционные методы, такие как стратегия Best-of-N (BoN), часто не учитывают сложность процессов мышления. Это привело к разработке моделей вознаграждения процесса (PRM), которые оценивают правильность промежуточных шагов. Однако создание эффективных PRM остается сложной задачей из-за проблем с аннотированием данных и методами оценки.
Решения от команды Alibaba Qwen
Команда Alibaba Qwen недавно представила две модели PRM с 7B и 72B параметрами, которые решают значительные ограничения существующих PRM. Эти модели используют инновационные методы для повышения точности и обобщаемости моделей мышления.
Гибридный подход
Ключевым элементом их подхода является гибридная методология, которая сочетает оценку Монте-Карло (MC) с новым механизмом «LLM как судья». Это улучшает качество аннотаций, делая PRM более эффективными в выявлении и устранении ошибок в математическом мышлении.
Технические инновации и преимущества
- Фильтрация консенсуса: Данные сохраняются только в том случае, если как MC, так и LLM согласны с правильностью шага, что значительно снижает шум в процессе обучения.
- Жесткая аннотация: Детерминированные метки, проверенные обоими механизмами, улучшают способность модели различать действительные и недействительные шаги мышления.
- Эффективное использование данных: Комбинирование MC с LLM как судья обеспечивает высокое качество данных при сохранении масштабируемости.
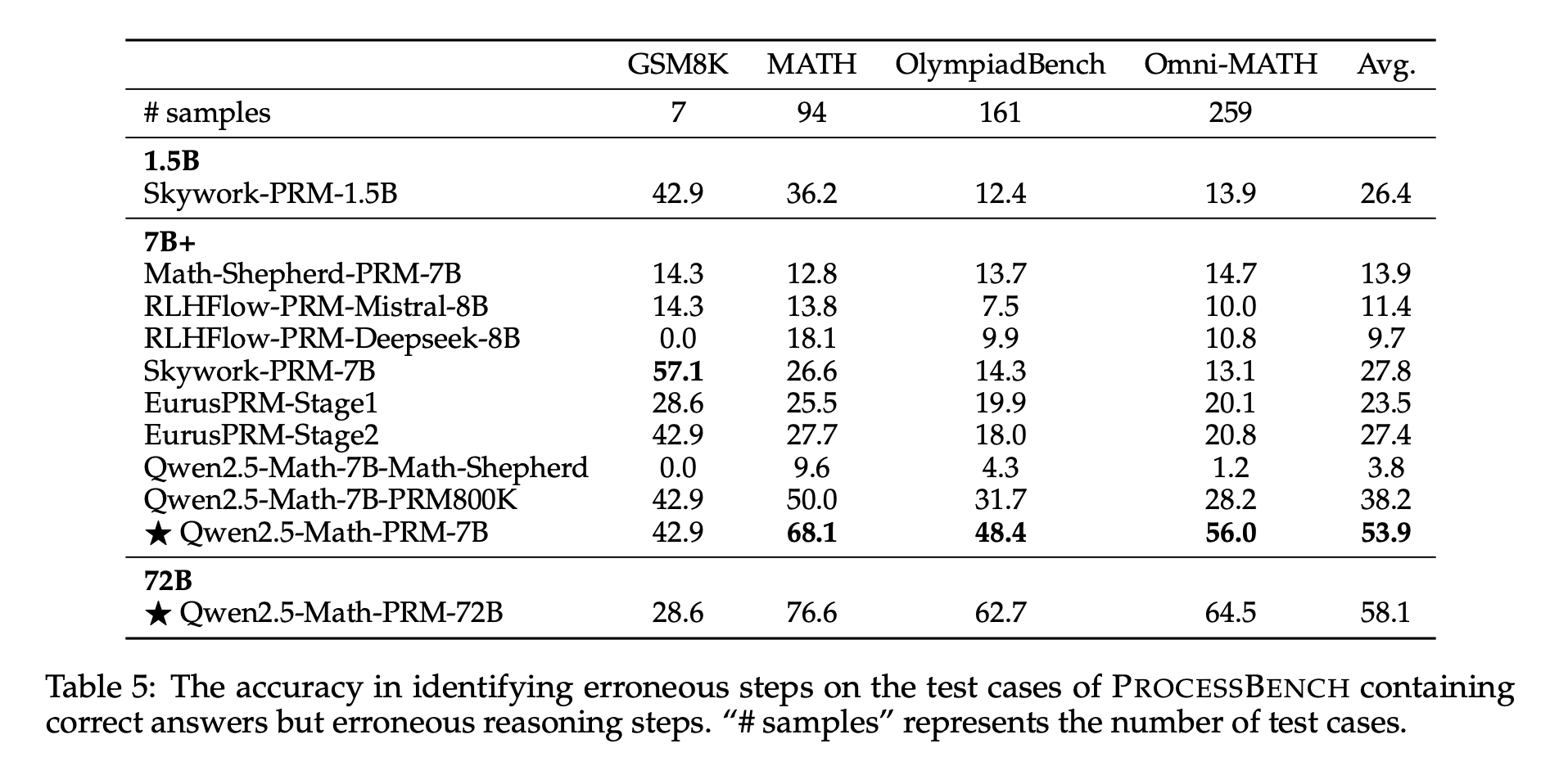
Результаты и выводы
Модели Qwen2.5-Math-PRM продемонстрировали отличные результаты на PROCESSBENCH и других метриках. Например, модель Qwen2.5-Math-PRM-72B достигла F1-оценки 78.3%, что превышает многие альтернативы с открытым исходным кодом.
Качество обучения
Подход фильтрации консенсуса сыграл ключевую роль в улучшении качества обучения, снизив шум данных примерно на 60%. Комбинирование MC с LLM как судья значительно повысило способность модели обнаруживать ошибки.
Заключение
Введение моделей Qwen2.5-Math-PRM представляет собой значительный шаг вперед в области математического мышления для LLM. Эти модели не только превосходят существующие альтернативы, но и предлагают ценные методологии для будущих исследований.
Как использовать ИИ в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ), следуйте этим шагам:
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Подберите подходящее решение, начиная с малого проекта и анализируя результаты.
- Расширяйте автоматизацию на основе полученных данных и опыта.
Если вам нужны советы по внедрению ИИ, пишите нам в Телеграм.
Попробуйте AI Sales Bot — это AI ассистент для продаж, который помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Узнайте, как ИИ может изменить процесс продаж в вашей компании с решением от saile.ru — будущее уже здесь!
«`


















