

«`html
Использование Sentence-BERT (SBERT) для оптимизации сравнения предложений в большом масштабе
Исследователи активно разрабатывают и создают модели для эффективной обработки и сравнения человеческого языка в области обработки естественного языка. Одной из ключевых областей исследования являются встраивания предложений, которые преобразуют предложения в математические векторы для сравнения их семантических значений. Эта технология критически важна для семантического поиска, кластеризации и задач вывода естественного языка. Модели, обрабатывающие такие задачи, могут значительно улучшить системы вопрос-ответ, разговорные агенты и классификацию текста. Однако, несмотря на прогресс в этой области, масштабируемость остается основным вызовом, особенно при работе с большими наборами данных или в реальном времени.
Оптимизация сравнения предложений в большом масштабе
Одной из заметных проблем при обработке текста является вычислительная сложность сравнения предложений. Традиционные модели, такие как BERT и RoBERTa, установили новые стандарты для сравнения пар предложений, но они неэффективны для задач, требующих обработки больших наборов данных. Например, поиск наиболее похожей пары предложений в коллекции из 10 000 предложений с использованием BERT требует около 50 миллионов вычислительных операций, что может занять до 65 часов на современных графических процессорах. Эффективность этих моделей создает значительные препятствия для масштабирования анализа текста и делает их непрактичными для многих крупномасштабных приложений, таких как веб-поиск или автоматизация поддержки клиентов.
Попытки решить эти проблемы в прошлом использовали различные стратегии, но большинство из них подвергаются компромиссам в производительности для достижения эффективности. Например, некоторые методы включают отображение предложений в векторное пространство, где семантически схожие предложения размещаются ближе друг к другу. Хотя это помогает уменьшить вычислительную нагрузку, качество полученных встроенных предложений часто страдает. Широко используемый метод усреднения выходных векторов BERT или использование токена [CLS] плохо справляется с такими задачами, давая результаты иногда хуже, чем у более старых и простых моделей, таких как внедрения GloVe. Таким образом, поиск решения, которое балансирует вычислительную эффективность с высокой производительностью, продолжается.
Причина выбора SBERT
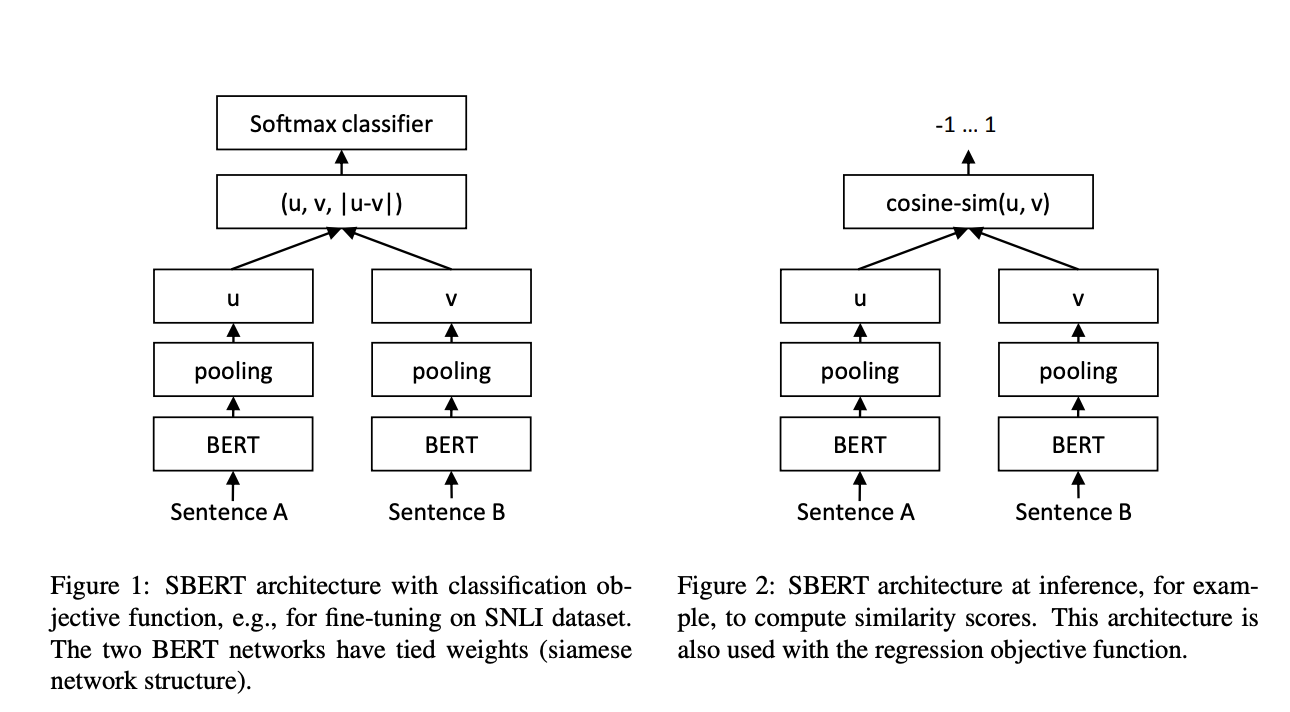
Исследователи из Лаборатории обработки всеобщих знаний (UKP-TUDA) в Департаменте компьютерных наук Технического университета Дармштадта представили модель Sentence-BERT (SBERT) — модификацию модели BERT, разработанную для обработки встраивания предложений более вычислительно осуществимым образом. Модель SBERT использует архитектуру сиамской сети, которая позволяет сравнивать встроенные предложения с использованием эффективных мер сходства, таких как косинусное сходство. Команда исследователей оптимизировала SBERT для сокращения вычислительного времени для сравнения предложений в большом масштабе, уменьшив время обработки с 65 часов до всего лишь пяти секунд для набора из 10 000 предложений. SBERT достигает такой замечательной эффективности, сохраняя уровень точности BERT, доказывая, что скорость и точность могут быть сбалансированы в задачах сравнения пар предложений.
Технология за SBERT включает использование различных стратегий пулинга для генерации векторов фиксированного размера из предложений. Стратегия по умолчанию усредняет выходные векторы (стратегия MEAN), в то время как другие варианты включают максимальный пулинг по времени и использование токена CLS. SBERT был донастроен с использованием большого набора данных из задач вывода естественного языка, таких как корпуса SNLI и MultiNLI. Эта доработка позволила SBERT превзойти предыдущие методы встраивания предложений, такие как InferSent и Universal Sentence Encoder, по многим бенчмаркам. На семи распространенных задачах семантической текстовой схожести (STS) SBERT улучшил показатель на 11,7 пункта по сравнению с InferSent и на 5,5 пункта по сравнению с Universal Sentence Encoder.
Производительность SBERT не ограничивается только скоростью. Модель продемонстрировала превосходную точность на нескольких наборах данных. В частности, на бенчмарке STS SBERT достиг корреляции ранга Спирмена 79,23 для базовой версии и 85,64 для большой версии. В сравнении InferSent набрал 68,03, а Universal Sentence Encoder — 74,92. SBERT также успешно проявил себя в задачах обучения передачи с использованием набора инструментов SentEval, где он достиг высоких показателей в задачах предсказания настроения, таких как классификация настроения в обзорах фильмов (84,88% точности) и классификация настроения отзывов о продуктах (90,07% точности). Возможность SBERT донастраивать свою производительность в ряде задач делает его очень универсальным для реальных приложений.
Преимущества SBERT и его применение
Основное преимущество SBERT заключается в его возможности масштабирования задач сравнения предложений, сохраняя при этом высокую точность. Например, он может сократить время, необходимое для поиска наиболее похожего вопроса в большом наборе данных, таком как Quora, с более чем 50 часов с BERT до нескольких миллисекунд с SBERT. Эта эффективность достигается благодаря оптимизированным структурам сетей и эффективным методам сходства. SBERT превосходит другие модели в задачах кластеризации, что делает его идеальным для проектов анализа текста в крупном масштабе. В вычислительных бенчмарках SBERT обрабатывал до 2042 предложений в секунду на графических процессорах, что на 9% больше, чем у InferSent, и на 55% быстрее, чем у Universal Sentence Encoder.
В заключение, SBERT значительно улучшает традиционные методы встраивания предложений, предлагая вычислительно эффективное и высокоточное решение. Сокращая время, необходимое для задач сравнения предложений с часов до секунд, SBERT решает критическую проблему масштабируемости в обработке естественного языка. Его выдающаяся производительность на нескольких бенчмарках, включая STS и задачи обучения передачи, делает его ценным инструментом для исследователей и практиков. Благодаря своей скорости и точности SBERT становится неотъемлемой моделью для анализа текста в крупном масштабе, обеспечивая быстрый и более надежный семантический поиск, кластеризацию и другие задачи обработки естественного языка.
«`
















