

«`html
Meta-Rewarding: новый метод для улучшения способности LLM следовать инструкциям
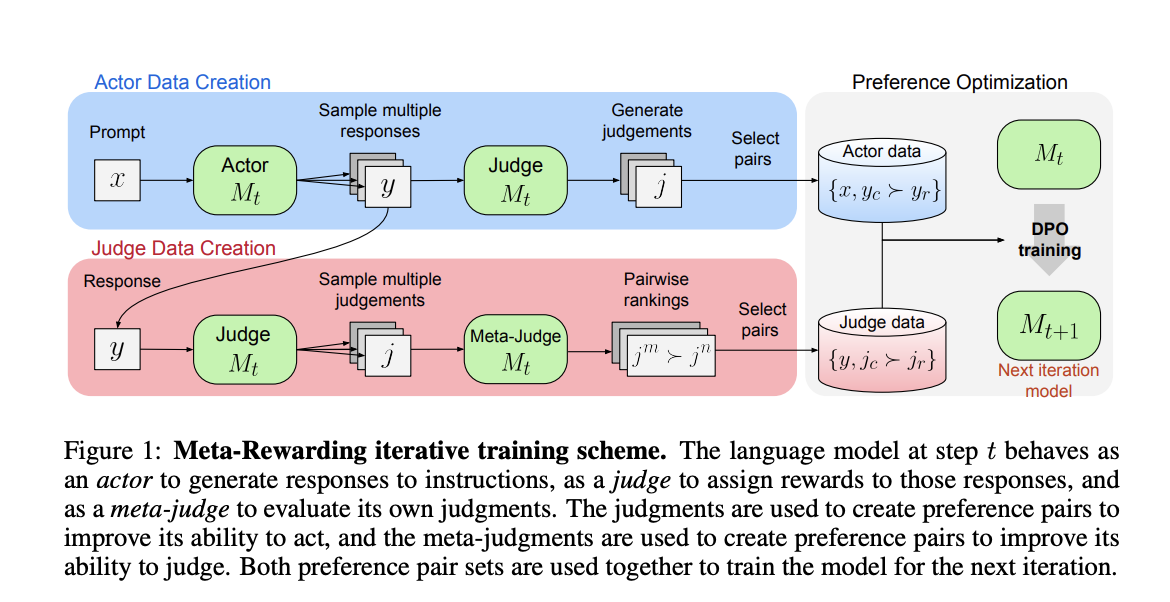
Исследователи предложили метод Meta-Rewarding, который использует мета-судью для оценки и выбора суждений для оптимизации предпочтений, что позволяет преодолеть ограничения предыдущих фреймворков Self-Rewarding путем прямого обучения судьи. Кроме того, он включает новую технику контроля длины, чтобы решить проблемы с длиной при обучении обратной связи ИИ. Способности суждений модели более тесно соответствуют суждениям человеческих судей и передовым ИИ-судьям, таким как GPT-4.
Практические решения и ценность
Если ваша компания хочет оставаться лидером и использовать искусственный интеллект, Meta-Rewarding может быть ключом к развитию. Анализируйте, как ИИ может изменить вашу работу и определите, где можно применить автоматизацию. Подберите подходящее решение и внедряйте его постепенно, начиная с малого проекта и анализируя результаты. Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Используйте AI Sales Bot для автоматизации работы с клиентами: https://itinai.ru/aisales. Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru.
Исследовательская работа
Подробнее о методе Meta-Rewarding исследователи рассказывают в своей статье.
«`


















