

«`html
Прогнозирование возможностей масштабирования фронтовых систем искусственного интеллекта
Оценка воздействия масштаба на способность предсказания последующих возможностей моделей фронтового искусственного интеллекта: понимание непредсказуемости
Прогнозирование поведения систем искусственного интеллекта, таких как GPT-4, Claude и Gemini, играет важную роль в создании понимания и разработке стратегий для их использования. Однако предсказать их производительность на конкретных задачах при масштабировании сложно, несмотря на существующие законы масштабирования параметров, данных, вычислений и потерь при предварительном обучении. Например, производительность в стандартных бенчмарках NLP иногда может неожиданно изменяться при масштабировании. Некоторые исследования предполагают, что такие неожиданные изменения могут быть вызваны выбором метрик и недостаточной разрешающей способностью.
Основное внимание исследования сосредоточено на оценке бенчмарков с использованием множественного выбора на основе логарифмических вероятностей. Хотя это важно в контексте таких задач, оно ограничивает более широкое применение результатов. Второе направление исследования объясняет сложность предсказания производительности в множественном выборе с использованием метрик, таких как точность и оценка Брайера. Исследование предполагает доступ к оценкам моделей на различных порядках масштабирования предварительных FLOPs и не использует обратное тестирование.
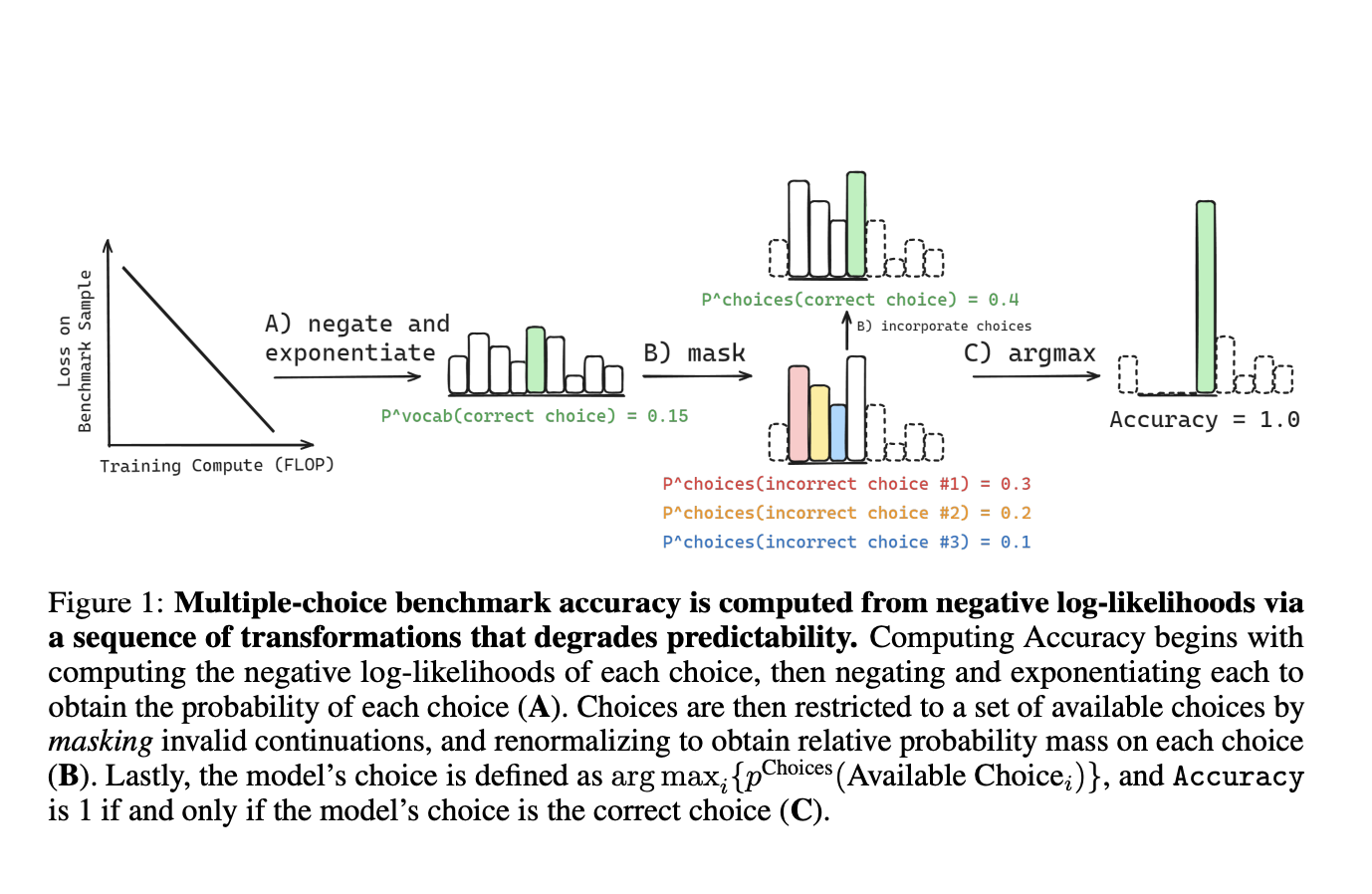
Ученые из Университета Кембриджа, Stanford CS, EleutherAI и MILA показали, что множественные метрики, такие как точность, оценка Брайера и вероятность правильного ответа, могут быть оценены на основе сырых выходных данных моделей. Это достигается через последовательность преобразований, которые постепенно разрушают статистическую связь между этими метриками и параметрами масштабирования. Главная причина заключается в том, что эти метрики зависят от прямого сравнения между правильным ответом и ограниченным набором конкретных неправильных ответов. Поэтому для точного прогнозирования производительности на последующих задачах необходимо моделировать, как вероятность изменяется среди конкретных неправильных альтернатив.
Ученые изучали, как вероятность неправильного выбора изменяется с увеличением вычислительных ресурсов. Это помогает понять, почему отдельные метрики на последующих этапах могут быть непредсказуемыми, в то время как законы масштабирования потерь при предварительном обучении более последовательны, поскольку они не зависят от конкретных неправильных выборов. Для разработки эффективных оценок, отслеживающих прогресс передовых возможностей искусственного интеллекта, важно понимать, что влияет на последующую производительность. Кроме того, для определения того, как изменяются последующие возможности на конкретных задачах в зависимости от масштаба для различных семей моделей, создаются оценки на основе примеров из различных семей моделей и множественных бенчмарков NLP.
Для точного прогнозирования производительности в множественном выборе ответов важно понимать, как меняется вероятность выбора правильного ответа в зависимости от масштаба, а также как меняется вероятность выбора неправильного ответа в зависимости от масштаба. Для метрик, таких как точность, эти прогнозы необходимо делать для каждого вопроса, потому что знание средней вероятности выбора неправильных ответов по многим вопросам не указывает на вероятность выбора конкретного неправильного ответа для конкретного вопроса. Особенно важно рассмотреть, как вероятности выбора правильных и неправильных ответов изменяются вместе при использовании больших вычислительных ресурсов.
В заключение, исследователи выявили фактор, вызывающий непредсказуемость в множественных тестах для фронтовых моделей искусственного интеллекта. Этим фактором является вероятность выбора неправильных ответов. Результаты исследования могут повлиять на разработку будущих оценок для фронтовых моделей искусственного интеллекта, которые можно надежно предсказывать с увеличением масштаба. Будущая работа сосредоточена на создании более предсказуемых оценок для систем искусственного интеллекта, особенно для сложных и важных возможностей. Исследователи предложили несколько направлений для расширения работы и применения своей методики для дальнейшего улучшения предсказуемости масштабирования.
Ознакомьтесь с нашей статьей. Вся заслуга за это исследование принадлежит ученым этого проекта. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему каналу в Telegram, сообществу в Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится нашая рассылка.
Не забудьте присоединиться к нашей группе в SubReddit.
«`



















