

«`html
Разблокирование языка белков: как большие языковые модели революционизируют понимание последовательностей белков
Исследователи провели параллели между последовательностями белков и естественным языком из-за их последовательной структуры, что привело к развитию глубоких моделей обучения для обеих областей. Однако приспособление LLMs к пониманию белков сталкивается с проблемой: существующие наборы данных требуют более прямых корреляций между последовательностями белков и текстовыми описаниями, что затрудняет эффективное обучение и оценку LLMs для понимания белков. Несмотря на прогресс в MMLMs, отсутствие комплексных наборов данных, интегрирующих последовательности белков с текстовым содержанием, ограничивает полное использование этих моделей в науке о белках.
Набор данных ProteinLMDataset и бенчмарк ProteinLMBench
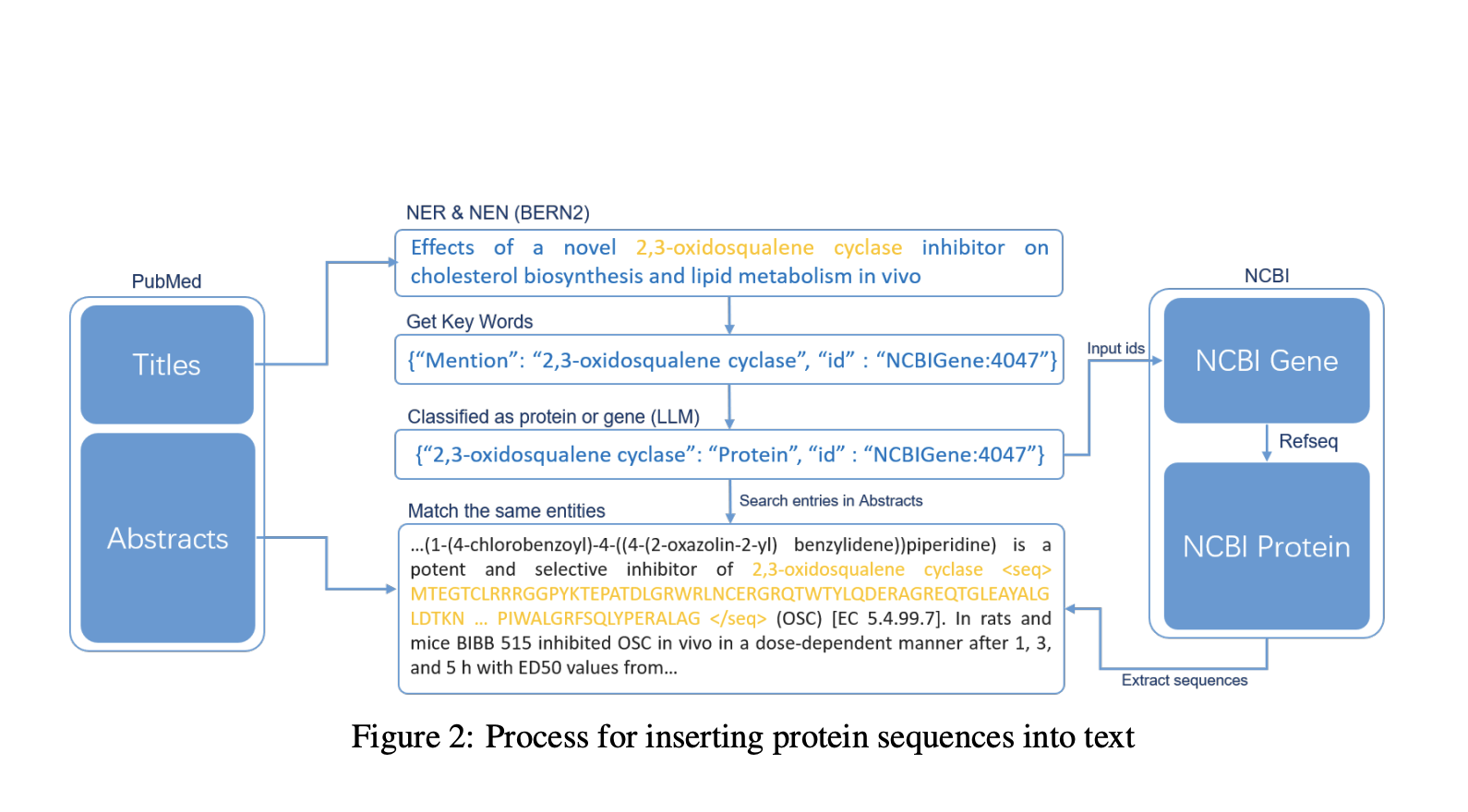
Исследователи из нескольких институтов, включая Johns Hopkins и UNSW Sydney, создали набор данных ProteinLMDataset для улучшения понимания последовательностей белков LLMs. Этот набор данных содержит 17,46 миллиарда токенов для самостоятельного предварительного обучения и 893 тыс. инструкций для контролируемой настройки. Они также разработали ProteinLMBench, первый бенчмарк с 944 вручную проверенными вопросами с множественным выбором для оценки понимания белков в LLMs. Набор данных и бенчмарк направлены на устранение разрыва в интеграции данных о белках и текста, позволяя LLMs понимать последовательности белков без дополнительных кодировщиков и генерировать точные знания о белках с использованием нового подхода ECoT (Enzyme Chain of Thought).
Оценка ограничений и предложение решений
Обзор литературы выявляет ключевые ограничения существующих наборов данных и бенчмарков NLP и последовательностей белков. Существует потребность в более комплексном, многофункциональном оценивании китайско-английских наборов данных, при этом существующие бенчмарки часто ограничены географически и требуют большей интерпретируемости. В наборах данных последовательностей белков крупные ресурсы, такие как UniProtKB и RefSeq, сталкиваются с проблемами полного представления разнообразия белков и точной аннотации данных, с искажениями и ошибками от сообщественных вкладов и автоматизированных систем. Также существуют ограничения в базах данных о дизайне белков, таких как KEGG и STRING, из-за предвзятости, ресурсоемкой кураторской работы и сложностей в интеграции разнообразных источников данных.
Структура набора данных и бенчмарка
Набор данных ProteinLMDataset разделен на самостоятельную и контролируемую части. Самостоятельный набор данных включает научные тексты на китайском и английском языках, пары последовательностей белков и текстов на английском из PubMed и UniProtKB, а также обширные записи из базы данных PMC, обеспечивая более 10 миллиардов токенов. Контролируемая настройка состоит из 893 тыс. инструкций по семи сегментам, таким как функциональность ферментов и участие в заболеваниях, в основном извлеченных из UniProtKB. ProteinLMBench включает 944 сбалансированных вопроса с множественным выбором для оценки производительности модели. Этот метод сбора данных обеспечивает комплексное представление, фильтрацию и токенизацию для эффективного обучения и оценки LLMs в науке о белках.
Заключение и применение моделей ИИ в бизнесе
Набор данных ProteinLMDataset и бенчмарк ProteinLMBench предназначены для комплексного понимания последовательностей белков. Набор данных разнообразен, с токенами от 21 до более 2 миллионов символов, собранных из нескольких источников, включая пары текстов на китайском и английском языках, аннотации из PubMed и UniProtKB. Самостоятельные данные в основном состоят из последовательностей белков и научных текстов. Контролируемый набор данных охватывает семь сегментов, таких как функциональность ферментов и участие в заболеваниях, с длиной токена от 65 до 70 500. ProteinLMBench включает 944 сбалансированных вопроса с множественным выбором для оценки производительности модели. Тщательные проверки безопасности и фильтрация обеспечивают качество и целостность данных. Результаты экспериментов показывают, что сочетание самостоятельного обучения с контролируемой настройкой повышает точность модели, подчеркивая эффективность набора данных.
Для развития вашей компании с помощью искусственного интеллекта обращайтесь к нам. Мы поможем внедрить AI-решения, которые улучшат эффективность бизнес-процессов и повысят уровень обслуживания клиентов.
Посетите наш сайт, чтобы узнать больше о том, как ИИ может изменить ваш бизнес. Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn, чтобы быть в курсе последних новостей об ИИ. Присоединитесь к нашей 44 тыс. сообществу на Reddit.
Если вам нужны рекомендации по внедрению ИИ, пишите нам в Telegram https://t.me/itinai. Следите за новостями о ИИ в нашем Telegram-канале t.me/itinainews или в Twitter @itinairu45358
Воспользуйтесь AI Sales Bot https://itinai.ru/aisales – это AI-ассистент в продажах, который поможет вам отвечать на вопросы клиентов, генерировать контент для отдела продажи и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru – будущее уже здесь!
«`



















