

«`html
Введение
Широкое использование крупных языковых моделей (LLMs) в критически важных областях создает важную задачу: как обеспечить их соответствие четким этическим и безопасным стандартам. Существующие методы выравнивания, такие как контролируемая дообучение (SFT) и обучение с подкреплением на основе человеческой обратной связи (RLHF), имеют свои ограничения.
Проблемы существующих методов
Модели могут генерировать вредоносный контент, отказываться выполнять законные запросы или испытывать трудности с незнакомыми сценариями. Эти проблемы часто возникают из-за неявного характера текущего обучения безопасности, где модели выводят стандарты косвенно из данных, а не учат их явно.
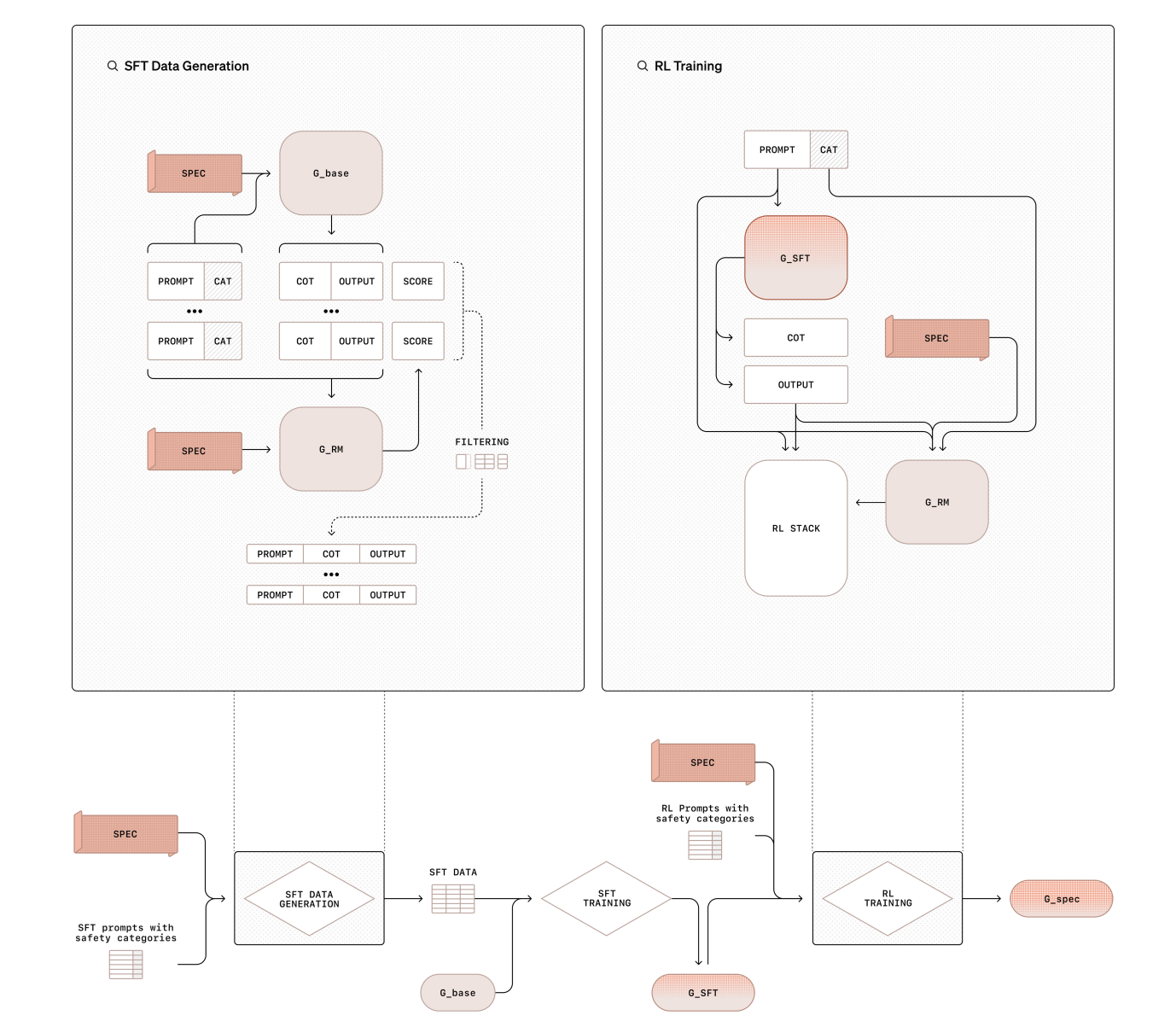
Новое решение: Делиберативное выравнивание
Исследователи OpenAI предложили новое решение — Делиберативное выравнивание, которое напрямую обучает модели стандартам безопасности и тренирует их рассуждать по этим стандартам перед генерацией ответов. Это метод решает ключевые слабости традиционных техник выравнивания.
Преимущества Делиберативного выравнивания
- Обучение моделей явному учету соответствующих политик.
- Использование данных, сгенерированных моделями, и рассуждений в цепочке (CoT) для достижения лучших результатов в области безопасности.
- Улучшенная устойчивость к атакам и меньше отказов на законные запросы.
Технические детали и преимущества
Делиберативное выравнивание включает двухступенчатый процесс обучения:
- Первый этап — контролируемое дообучение (SFT), которое обучает модели ссылаться на стандарты безопасности.
- Второй этап — обучение с подкреплением (RL), которое уточняет рассуждения модели с помощью модели вознаграждения.
Этот процесс не требует аннотированных данных, что снижает ресурсоемкость обучения безопасности.
Результаты и выводы
Делиберативное выравнивание показало заметные улучшения в производительности моделей OpenAI. Например, модель o1 продемонстрировала высокую устойчивость к атакам, а также точность 93% на безвредных запросах.
Заключение
Делиберативное выравнивание представляет собой значительный шаг вперед в выравнивании языковых моделей с принципами безопасности. Оно предлагает масштабируемое и понятное решение для сложных этических задач.
Как использовать ИИ для развития бизнеса
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ), следуйте этим шагам:
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Подберите подходящее решение и внедряйте ИИ постепенно.
- На основе полученных данных расширяйте автоматизацию.
Получите советы по внедрению ИИ
Если вам нужны советы по внедрению ИИ, пишите нам.
Изучите, как ИИ может изменить процесс продаж
Узнайте, как ИИ может изменить процесс продаж в вашей компании с помощью AI Sales Bot. Это AI ассистент для продаж, который помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
«`


















