

«`html
Модели смешанных экспертов (MoE) и их значение в ИИ
Модели MoE становятся важными для развития искусственного интеллекта, особенно в области обработки естественного языка. Они отличаются от традиционных моделей тем, что активируют только определенные группы специализированных экспертов для каждого входного запроса. Это позволяет увеличить возможности моделей, не требуя при этом больших вычислительных ресурсов для обучения и вывода.
Преимущества MoE моделей
- Эффективность: Модели MoE могут улучшать точность и производительность без необходимости создания новых моделей с нуля.
- Экономия ресурсов: Использование существующих плотных моделей с добавлением новых параметров позволяет избежать чрезмерных вычислительных затрат.
Проблемы плотных моделей и их решение
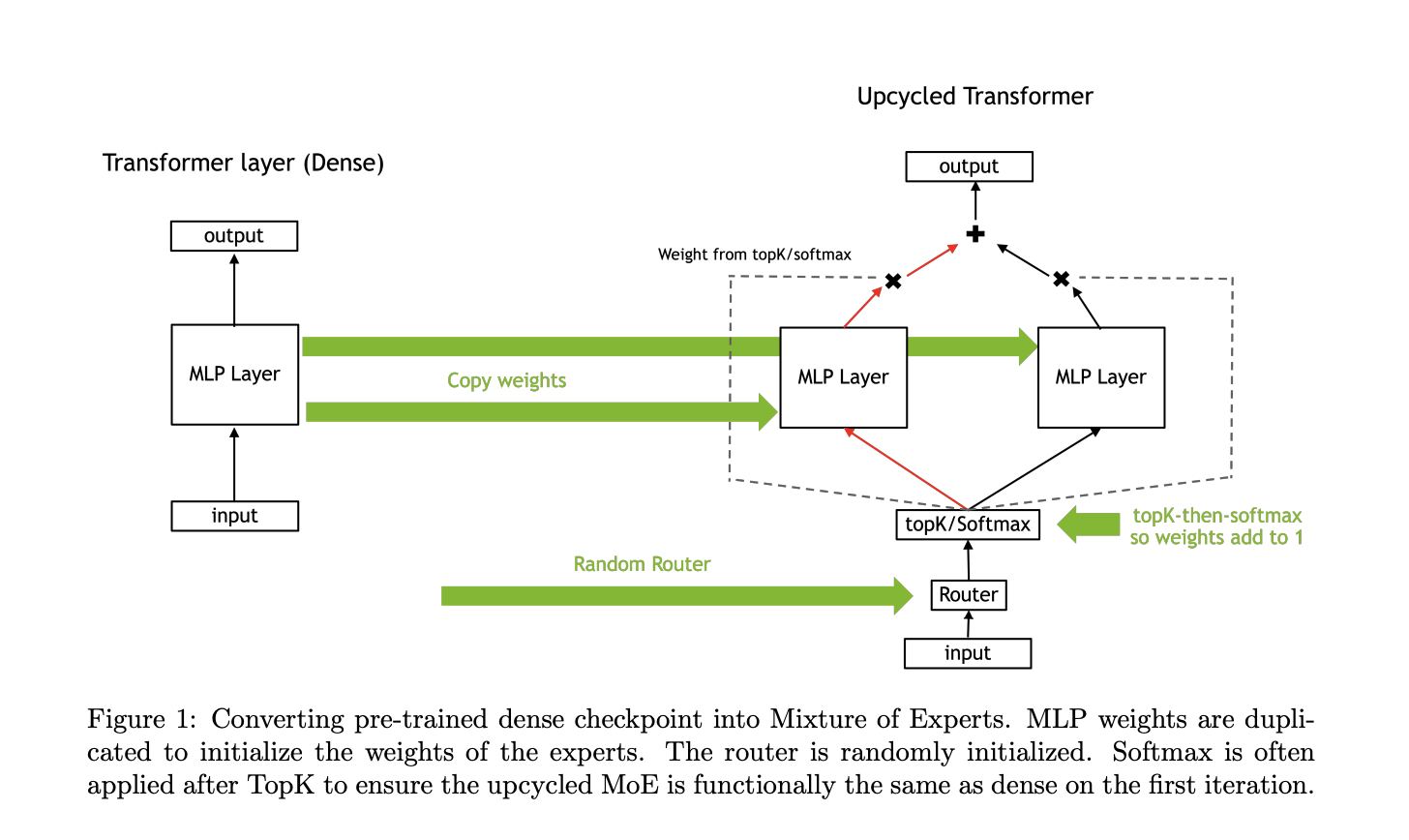
Плотные модели часто достигают плато производительности. Чтобы улучшить их, обычно требуется увеличивать размер модели, что требует повторного обучения и значительных ресурсов. Переработка предобученных плотных моделей в MoE модели позволяет расширить их возможности, добавляя экспертов для выполнения конкретных задач.
Новый подход от NVIDIA
Исследователи NVIDIA разработали новый метод переработки предобученных плотных моделей в разреженные MoE модели. Они предложили схему инициализации «виртуальной группы» и метод масштабирования весов, что облегчает этот процесс.
Преимущества нового подхода
- Улучшенная производительность: Модель Nemotron-4 с 15 миллиардами параметров показала 67.6% на тесте MMLU после переработки.
- Снижение потерь: Метод softmax-then-topK улучшил потери валидации на 1.5% по сравнению с непрерывным обучением плотной модели.
- Экономия вычислительных ресурсов: Переработанные модели продемонстрировали более высокую производительность без дополнительных затрат на вычисления.
Основные выводы исследования
- Переработанные модели MoE могут улучшать точность без значительных изменений в вычислительных ресурсах.
- Использование инициализации виртуальной группы и масштабирования весов является ключевым для достижения или превышения точности исходных плотных моделей.
- Модели с высокой гранулярностью, в сочетании с тщательным масштабированием весов, могут значительно повысить точность.
Заключение
Переработка плотных языковых моделей в MoE модели является эффективным решением для расширения их возможностей. Используя методы инициализации виртуальной группы и маршрутизации softmax-then-topK, можно продолжать повышать точность моделей без необходимости полного переобучения.
Практические рекомендации для бизнеса
- Анализируйте, как ИИ может изменить вашу работу и где возможно применение автоматизации.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Подберите подходящее ИИ-решение и внедряйте его постепенно.
«`


















