

«`html
Исследование FlashInfer: Эффективное решение для ИИ
Большие языковые модели (LLMs) стали важной частью современных ИИ-приложений, таких как чат-боты и генераторы кода. Однако их использование выявило недостатки в процессах вывода. Механизмы внимания, такие как FlashAttention и SparseAttention, часто сталкиваются с проблемами при разнообразных нагрузках и ограничениях ресурсов GPU. Это подчеркивает необходимость более эффективного и гибкого решения для поддержки масштабируемого вывода LLM.
Что такое FlashInfer?
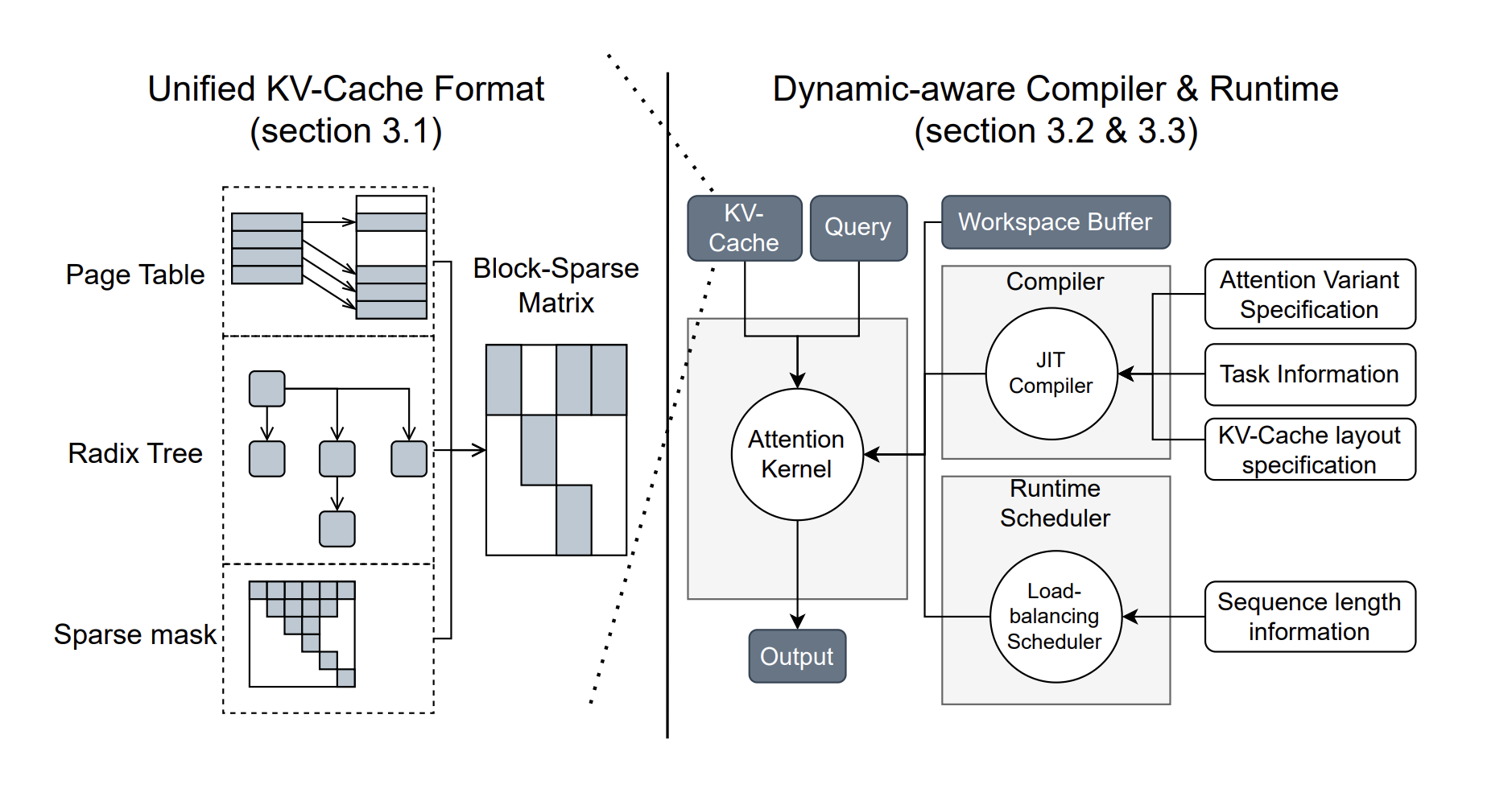
Исследователи из Университета Вашингтона, NVIDIA, Perplexity AI и Университета Карнеги-Меллон разработали FlashInfer — библиотеку ИИ и генератор ядра, предназначенный для вывода LLM. FlashInfer обеспечивает высокопроизводительные реализации ядер GPU для различных механизмов внимания, таких как FlashAttention, SparseAttention и PageAttention. Его дизайн ориентирован на гибкость и эффективность, решая ключевые задачи в обслуживании вывода LLM.
Преимущества FlashInfer
- Качественные ядра внимания: Поддержка различных механизмов внимания, что улучшает производительность для одиночных запросов и пакетного обслуживания.
- Оптимизированное декодирование: Достижение значительного ускорения выводов, например, улучшение скорости декодирования на 31 раз по сравнению с предыдущими решениями.
- Динамическое планирование: Система адаптируется к изменениям во входных данных, снижая время простоя GPU.
- Настраиваемая JIT-компиляция: Пользователи могут создавать и компилировать собственные варианты внимания для специфических задач.
Результаты производительности
FlashInfer демонстрирует заметные улучшения производительности:
- Снижение задержки: Уменьшение задержки между токенами на 29-69% по сравнению с другими решениями.
- Увеличение пропускной способности: Достижение 13-17% ускорения на GPU NVIDIA H100 при параллельных задачах.
- Улучшение использования GPU: Оптимизация пропускной способности и использование FLOP.
Заключение
FlashInfer предлагает практическое и эффективное решение для задач вывода LLM, обеспечивая значительные улучшения в производительности и использовании ресурсов. Его гибкий дизайн и возможности интеграции делают его ценным инструментом для улучшения работы с LLM. FlashInfer открывает путь к более доступным и масштабируемым ИИ-приложениям.
Как использовать ИИ в вашей компании?
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые вы хотите улучшить с помощью ИИ.
- Подберите подходящее решение и внедряйте его постепенно.
- Расширяйте автоматизацию на основе полученных данных и опыта.
Если вам нужны советы по внедрению ИИ, пишите нам в Телеграм.
Попробуйте AI Sales Bot — это ИИ ассистент для продаж, который поможет вам улучшить взаимодействие с клиентами.
«`


















