

«`html
Проблемы применения обучения с подкреплением
Обучение с подкреплением (RL) сталкивается с основными трудностями, которые мешают его полному потенциалу:
- Низкая эффективность использования выборок. Алгоритмы, такие как PPO, требуют множества эпизодов для изучения базовых действий.
- Методы Off-Policy. Хотя SAC и DrQ более эффективны, они требуют плотных сигналов награды, что снижает их эффективность в условиях редкой награды.
Новые подходы к обучению с подкреплением
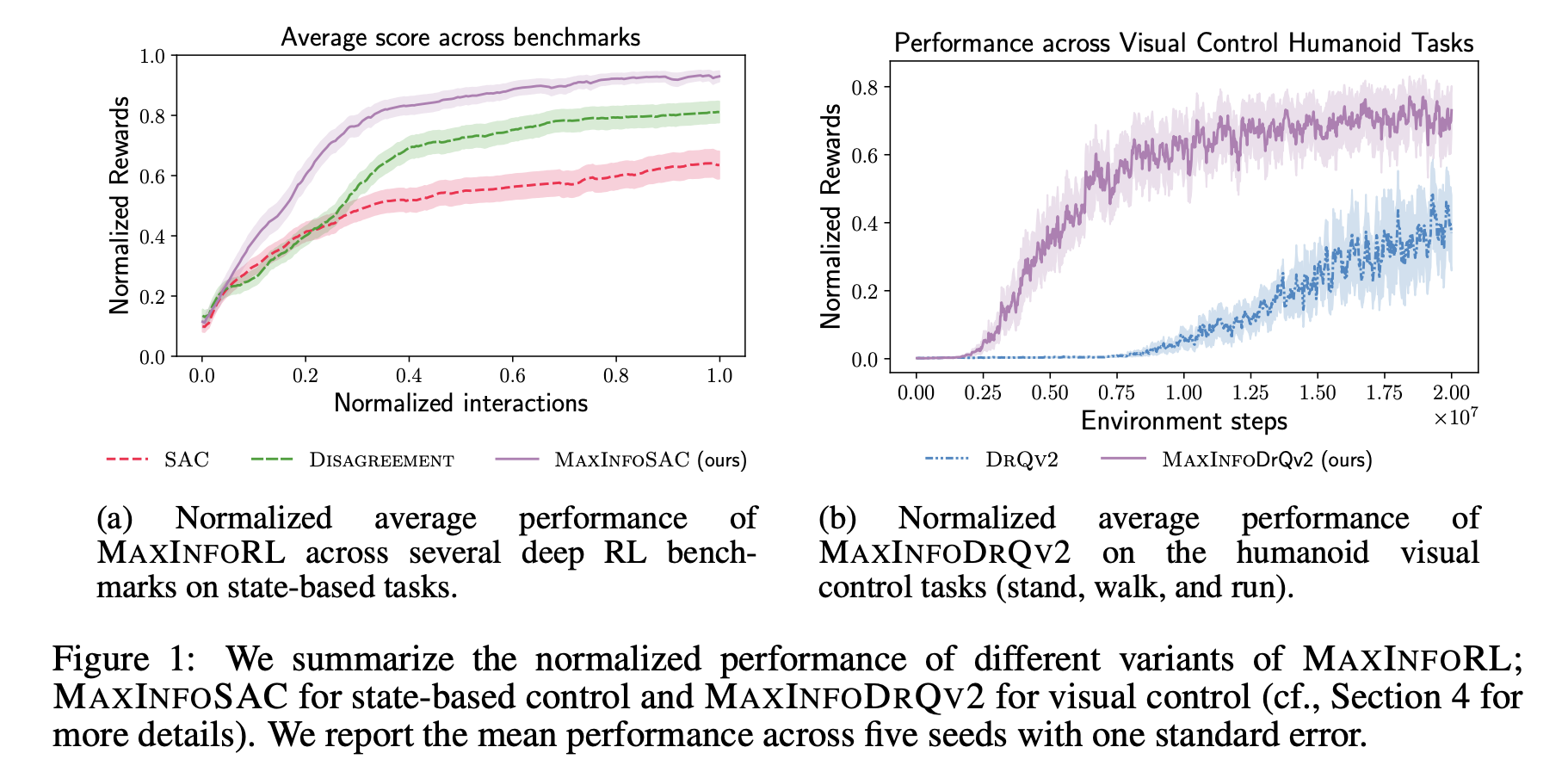
Недавние исследования показывают потенциал внутренней активизации и использования информации для улучшения исследования агентами RL. MAXINFORL от ETH Zurich и UC Berkeley предлагает новые решения:
- Улучшение старых методов. MAXINFORL направляет исследование с помощью внутренних наград, таких как получение информации.
- Автонастройка. Упрощает баланс между исследованием и наградами, повышая эффективность алгоритмов.
Преимущества MAXINFORL
- Оптимизация выбора действий. Использует внутренние награды для информированного исследования.
- Два бонуса для исследования: энтропия политики и получение информации.
- Улучшенная производительность. MAXINFORL демонстрирует превосходство над другими методами на различных задачах.
Выводы
MAXINFORL преодолевает ограничения старых методов, добиваясь лучших результатов в задачах с использованием как внутренней, так и внешней награды, но требует значительных вычислительных ресурсов.
Как использовать AI в вашем бизнесе
- Проанализируйте, как ИИ может оказать влияние на ваш бизнес.
- Определите, где можно применить автоматизацию для получения выгоды.
- Выберите подходящее решение и начинайте с небольшого проекта.
- На основе собранных данных расширяйте автоматизацию.
Советы и решения
Если вам нужны советы по внедрению ИИ, пишите нам!
Узнайте, как ИИ может изменить процесс продаж в вашей компании.
«`



















