

«`html
Решение задачи генерации качественных и разнообразных наборов данных для вызова функций
Модели вызова функций, являющиеся значительным прорывом в рамках больших языковых моделей, сталкиваются с проблемой необходимости высококачественных, разнообразных и верифицируемых наборов данных. Эти модели интерпретируют естественно-языковые инструкции для выполнения вызовов API, что критически важно для мгновенного взаимодействия с различными цифровыми сервисами. Однако существующие наборы данных часто не обладают полной верификацией и разнообразием, что приводит к неточностям и неэффективности. Преодоление этих проблем крайне важно для надежного развертывания моделей вызова функций в реальных приложениях, таких как получение данных с фондового рынка или управление взаимодействиями в социальных медиа.
Проблема и решение
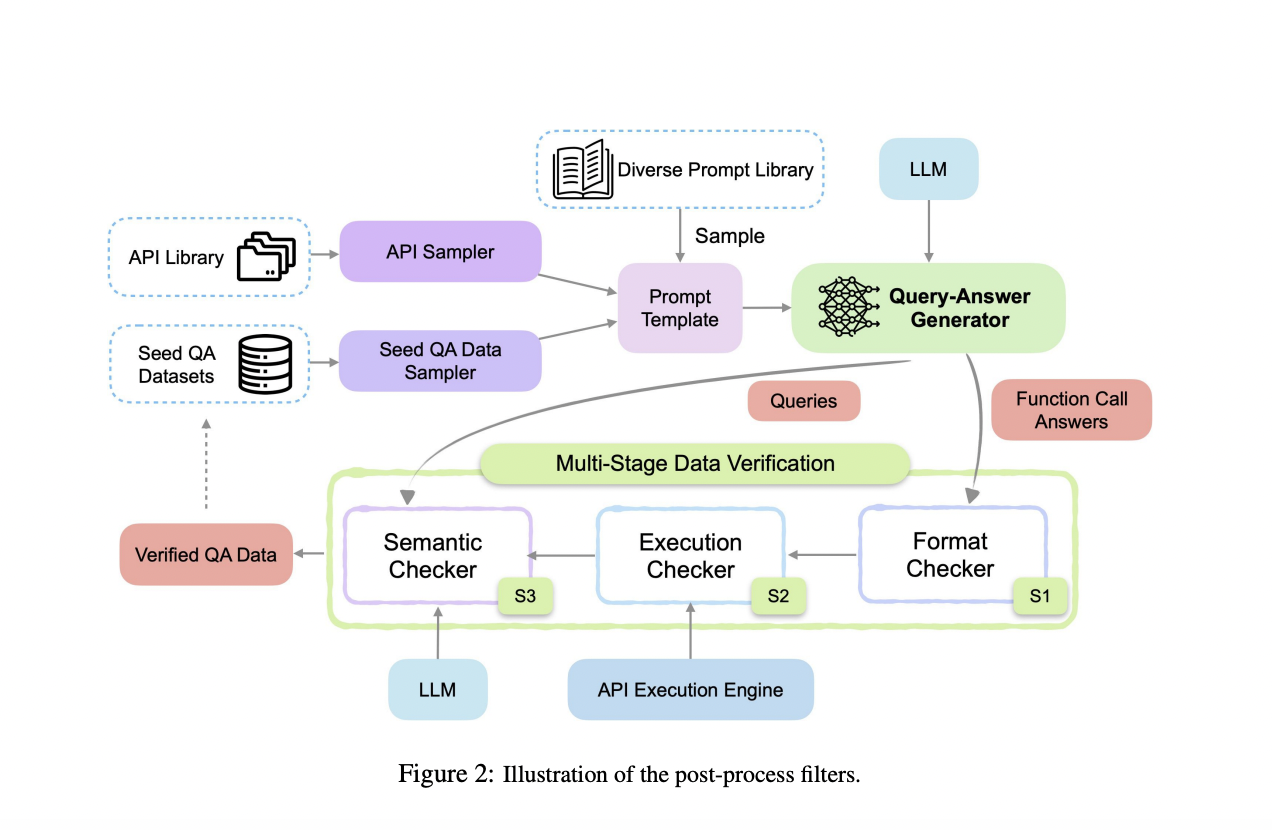
Текущие методы обучения моделей вызова функций основаны на статических наборах данных, которые не проходят тщательной верификации. Это часто приводит к недостаточным наборам данных, когда модели сталкиваются с новыми или невидимыми API, серьезно ограничивая их адаптивность и производительность. Исследователи из Salesforce AI Research предлагают APIGen, автоматизированный пайплайн для создания разнообразных и верифицируемых наборов данных вызова функций. APIGen решает ограничения существующих методов путем включения многоуровневого процесса верификации, обеспечивая надежность и корректность данных. Этот инновационный подход включает три иерархических этапа: проверка формата, фактическое выполнение функций и семантическая верификация. Благодаря тщательной проверке каждой точки данных, APIGen создает высококачественные наборы данных, значительно улучшающие обучение и производительность моделей вызова функций.
Практическое применение
Процесс генерации данных APIGen начинается с выборки API и примеров запрос-ответ из библиотеки, форматируя их в стандартизированный формат JSON. Затем пайплайн использует многоуровневый процесс верификации. Этап 1 включает проверку формата, гарантирующую правильную структуру JSON. Этап 2 выполняет вызовы функций для проверки их операционной корректности. Этап 3 использует семантический проверятор для обеспечения соответствия между вызовами функций, результатами выполнения и целями запроса. Этот процесс приводит к обширному набору данных из 60 000 высококачественных записей, охватывающих 3 673 API в 21 категории, доступных на Huggingface.
Результаты
Наборы данных APIGen значительно улучшили производительность моделей, достигнув передовых результатов на тесте Berkeley Function-Calling Benchmark. Особенно модели, обученные с использованием этих наборов данных, превзошли несколько моделей GPT-4, продемонстрировав значительное улучшение точности и эффективности. Например, модель с всего 7 миллиардами параметров достигла точности 87,5%, превзойдя предыдущие передовые модели значительно. Эти результаты подчеркивают надежность и надежность наборов данных, созданных APIGen, в улучшении возможностей моделей вызова функций.
Заключение
Исследователи представляют APIGen, новую платформу для создания высококачественных и разнообразных наборов данных вызова функций, решающую критическую проблему в исследованиях в области искусственного интеллекта. Предложенный многоуровневый процесс верификации обеспечивает надежность и корректность данных, значительно улучшая производительность моделей. Наборы данных, созданные APIGen, позволяют даже небольшим моделям достигать конкурентоспособных результатов, продвигая область моделей вызова функций. Этот подход открывает новые возможности для разработки эффективных и мощных языковых моделей, подчеркивая важность высококачественных данных в исследованиях в области искусственного интеллекта.
Подробнее о проекте и статье вы можете узнать здесь. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Твиттер и присоединиться к нашим группам в Телеграме и LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка. Не забудьте присоединиться к нашему сообществу в Reddit.
«`



















