

«`html
RLHF: Онлайн и оффлайн методы выравнивания LLMs в исследовании Google DeepMind
RLHF — стандартный подход для выравнивания LLMs. Однако, недавние достижения в оффлайн методах выравнивания, таких как прямая оптимизация предпочтений (DPO) и его варианты, вызывают сомнения в необходимости онлайн выборки при RLHF. Оффлайн методы, использующие существующие наборы данных без активного онлайн взаимодействия, показали практическую эффективность и более просты в реализации. Это вызывает вопрос о необходимости онлайн RL для выравнивания ИИ. Сравнение онлайн и оффлайн методов сложно из-за их различных вычислительных требований, что требует тщательной калибровки бюджета для справедливого измерения производительности.
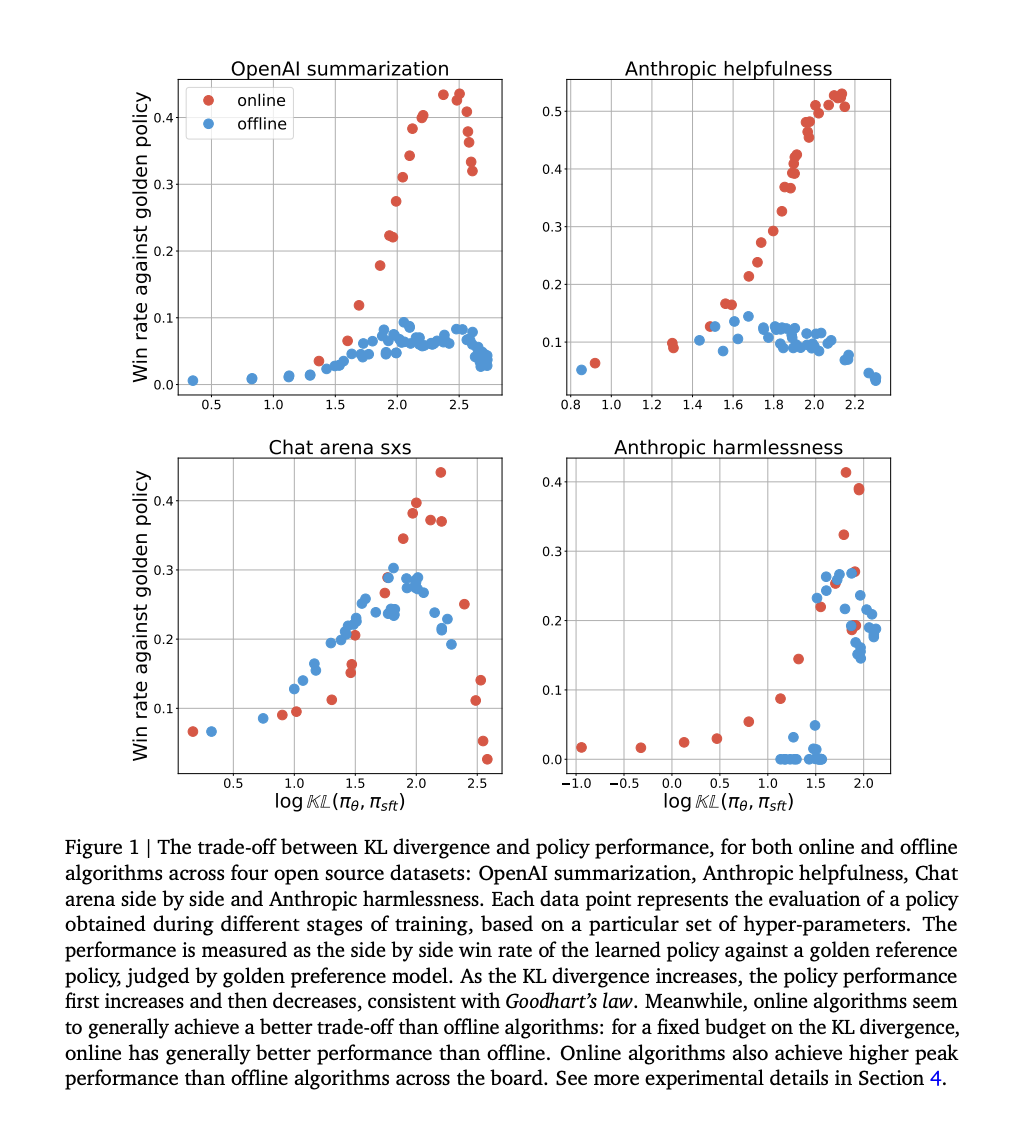
Исследователи из Google DeepMind продемонстрировали, что онлайн методы превосходят оффлайн методы в их начальных экспериментах, что привело к дальнейшему изучению этого разрыва в производительности. Через контролируемые эксперименты они обнаружили, что факторы, такие как покрытие и качество оффлайн данных, полностью объясняют разрыв. В отличие от онлайн методов, оффлайн методы отлично справляются с классификацией попарно, но нуждаются в помощи в генерации. Разрыв сохраняется независимо от типа функции потерь и масштабирования модели. Это указывает на то, что онлайн выборка является ключевой для выравнивания ИИ, подчеркивая сложности оффлайн выравнивания. Исследование использует дивергенцию Кульбака-Лейблера от политики супервайзинга (SFT) для сравнения производительности алгоритмов и бюджетов, раскрывая устойчивые различия.
Исследование дополняет предыдущую работу по RLHF путем сравнения онлайн и оффлайн алгоритмов RLHF. Исследователи выявляют устойчивый разрыв в производительности между онлайн и оффлайн методами, даже при использовании различных функций потерь и масштабировании политических сетей. В то время как предыдущие исследования отмечали сложности в оффлайн RL, их результаты подчеркивают, что они распространяются на RLHF.
Исследование сравнивает онлайн и оффлайн методы выравнивания с использованием IPO потерь на различных наборах данных, изучая их производительность с учетом закона Гудхарта. IPO потери включают оптимизацию веса выигрышных ответов над проигрышными, при этом различия в процессах выборки определяют онлайн и оффлайн методы. Онлайн алгоритмы выбирают ответы по политике, в то время как оффлайн алгоритмы используют фиксированный набор данных. Эксперименты показывают, что онлайн алгоритмы достигают лучших компромиссов между дивергенцией Кульбака-Лейблера и производительностью, более эффективно используя KL бюджет и достигая более высокой пиковой производительности. Предлагаются несколько гипотез для объяснения этих различий, таких как разнообразие покрытия данных и субоптимальные оффлайн наборы данных.
Предположение утверждает, что разрыв в производительности между онлайн и оффлайн алгоритмами можно частично объяснить точностью классификации модели предпочтений по сравнению с самой политикой. Во-первых, модель предпочтений обычно достигает более высокой точности классификации, чем политика при использовании в качестве классификатора. Во-вторых, предполагается, что это различие в точности классификации вносит вклад в наблюдаемый разрыв производительности между онлайн и оффлайн алгоритмами. В сущности, это предположение указывает на то, что лучшая классификация приводит к лучшей производительности, но для подтверждения этой гипотезы требуется дальнейшее изучение и подтверждение на практике.
В заключение, исследование подчеркивает критическую роль онлайн выборки в эффективном выравнивании LLMs и выявляет сложности, связанные с оффлайн методами выравнивания. Исследователи разоблачили несколько распространенных убеждений о разрыве производительности между онлайн и оффлайн алгоритмами через тщательные эксперименты и проверку гипотез. Они подчеркивают важность формирования данных по политике для повышения эффективности обучения политики. Однако они также утверждают, что оффлайн алгоритмы могут улучшиться, приняв стратегии, имитирующие процессы онлайн обучения. Это открывает пути для дальнейшего исследования, такие как гибридные подходы, объединяющие преимущества как онлайн, так и оффлайн методов, а также глубокие теоретические исследования в области обучения с подкреплением для обратной связи от человека.
Проверьте Статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, каналу в Discord и группе LinkedIn.
Если вам понравилась наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему Reddit с более чем 42 тыс. подписчиков.
Это исследование ИИ от Google DeepMind исследует разрыв в производительности между онлайн и оффлайн методами для выравнивания ИИ
«`

















