

«`html
Многопрофильная обработка естественного языка (NLP)
Многопрофильная обработка естественного языка (NLP) — это быстро развивающаяся область, которая нацелена на разработку языковых моделей, способных понимать и генерировать текст на нескольких языках. Эти модели облегчают эффективное общение и доступ к информации на различных языках. Важность этой области заключается в ее потенциале преодоления разрыва между носителями разных языков, делая технологические достижения в области ИИ доступными по всему миру. Однако разработка таких моделей представляет существенные вызовы из-за сложностей одновременной обработки нескольких языков.
Проблемы и решения в многопрофильной обработке естественного языка
Одной из основных проблем в многопрофильной обработке естественного языка является преобладающее внимание к нескольким основным языкам, таким как английский и китайский. Эта узкая концентрация приводит к значительному разрыву в производительности моделей при применении к менее распространенным языкам. Для преодоления этого неравенства требуются инновационные подходы для улучшения качества и разнообразия многопрофильных наборов данных, обеспечивая эффективную работу моделей ИИ на широком спектре языков.
Традиционные методы улучшения многопрофильных языковых моделей часто включают перевод предпочтительных данных с английского на другие языки. Хотя эта стратегия в некоторой степени помогает, она вносит несколько проблем, включая переводные артефакты, которые могут ухудшить производительность модели. Сильная зависимость от перевода может привести к недостатку разнообразия в данных, что критически важно для надежного обучения модели. Сбор высококачественных многопрофильных предпочтительных данных через человеческую аннотацию является потенциальным решением, но это дорого и затратно по времени, что делает его непрактичным для масштабных приложений.
Исследователи из Cohere For AI разработали новый масштабируемый метод для генерации высококачественных многопрофильных данных обратной связи. Этот метод нацелен на балансировку охвата данных и улучшение производительности многопрофильных больших языковых моделей (LLM). Исследовательская группа представила уникальный подход, использующий разнообразные многопрофильные подсказки и завершения, сгенерированные несколькими LLM. Этот подход не только увеличивает разнообразие данных, но также помогает избежать распространенных проблем, связанных с переводными артефактами. Модели, использованные в этом исследовании, включают Command и Command R+ от Cohere, специально разработанные для многопрофильных возможностей.
Методология включает перевод примерно 50 000 английских подсказок на 22 дополнительных языках с использованием модели NLLB 3.3B. Затем эти подсказки используются для генерации завершений на каждом языке, обеспечивая высокое разнообразие и качество данных. Исследовательская группа также сравнила завершения, сгенерированные непосредственно на целевом языке, с теми, которые были переведены с английского, и обнаружила, что первые значительно снизили появление переводных артефактов. Этот подход привел к разнообразному набору многопрофильных пар предпочтений, критически важных для эффективной оптимизации предпочтений.
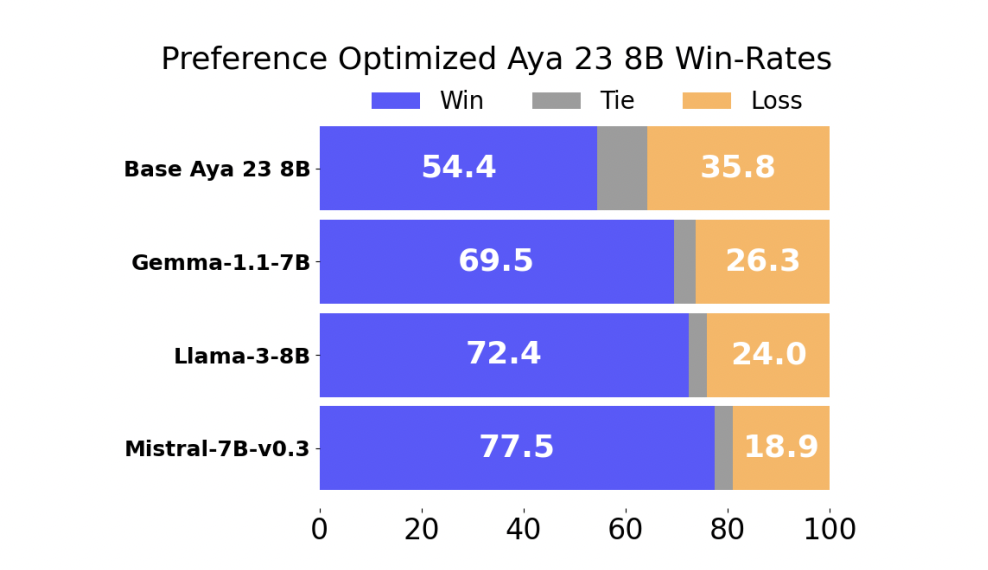
Производительность модели, обученной на предпочтения, была оценена по сравнению с несколькими передовыми многопрофильными LLM. Результаты были впечатляющими: модель, обученная на предпочтения, достигла победного процента 54,4% против Aya 23 8B, в настоящее время ведущей многопрофильной LLM в своем классе параметров. Кроме того, модель показала победный процент 69,5% или выше против других широко используемых моделей, таких как Gemma-1.1-7B-it, Meta-Llama3-8B-Instruct и Mistral-7B-Instruct-v0.3. Эти результаты подчеркивают эффективность подхода исследователей в улучшении производительности многопрофильных LLM через улучшенную оптимизацию предпочтений.
Дальнейший анализ показал, что увеличение количества языков в обучающих данных последовательно улучшало производительность модели. Например, обучение на пяти языках привело к победному проценту 54,9% на невидимых языках, по сравнению с 46,3%, когда обучение производилось только на английском. Более того, онлайн методы оптимизации предпочтений, такие как обучение с подкреплением от человеческой обратной связи (RLHF), оказались более эффективными, чем оффлайн методы, такие как прямая оптимизация предпочтений (DPO). Онлайн техники достигали более высоких победных процентов, причем RLOO превосходил DPO на 10,6% в некоторых случаях.
В заключение, проведенное исследование Cohere For AI демонстрирует критическую важность высококачественных, разнообразных многопрофильных данных для обучения эффективных многопрофильных языковых моделей. Инновационные методы, представленные исследовательской группой, решают проблемы дефицита данных и их качества, что приводит к улучшению производительности на широком спектре языков. Это исследование не только устанавливает новый стандарт для многопрофильной оптимизации предпочтений, но также подчеркивает ценность онлайн методов обучения в достижении превосходного межъязыкового переноса и общей производительности модели.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему подпредприятию ML SubReddit.
Статья This AI Paper from Cohere for AI Presents a Comprehensive Study on Multilingual Preference Optimization была опубликована на MarkTechPost.
«`

















