

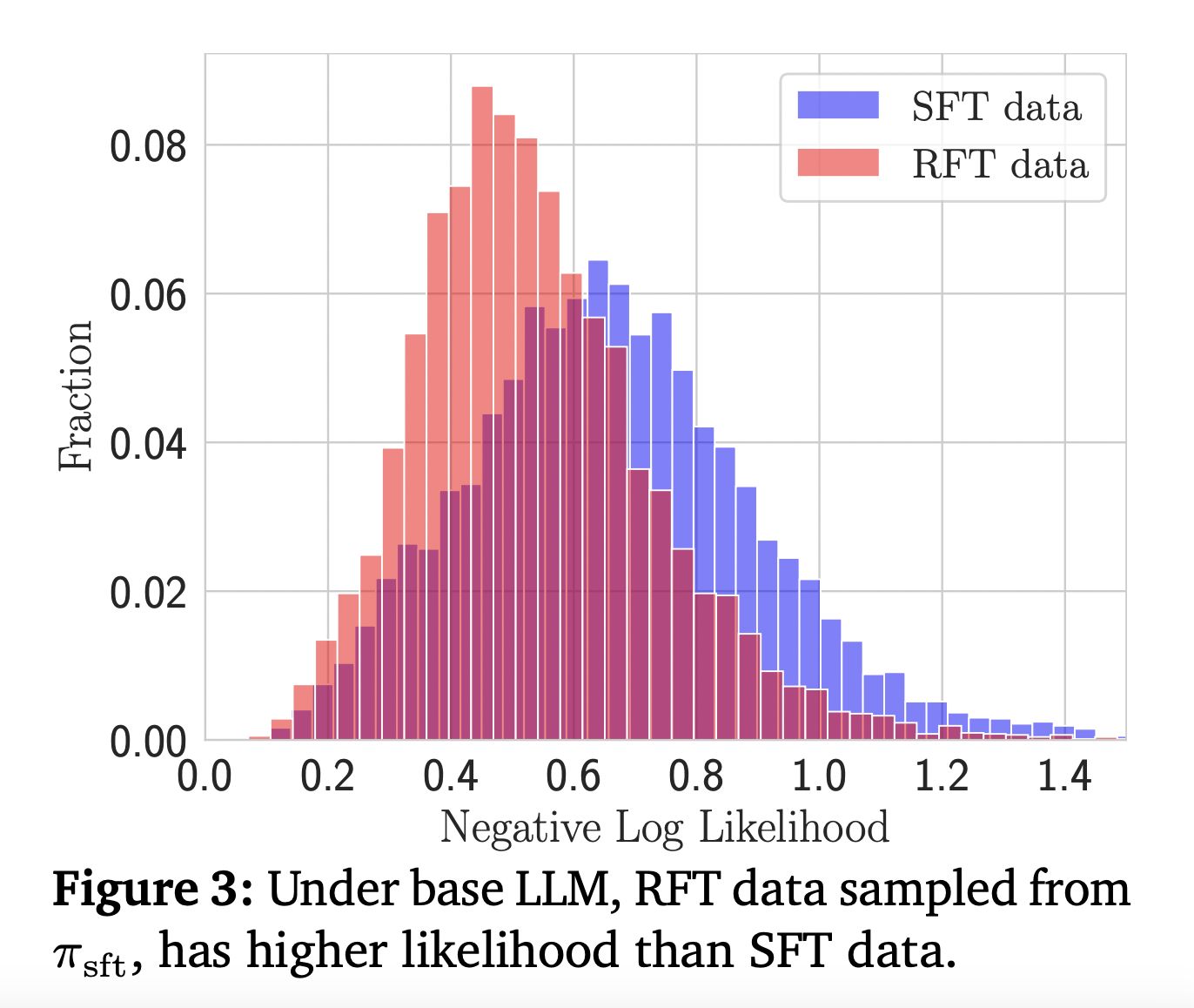
«`html
Исследование влияния синтетических данных на улучшение математических способностей LLMs
Большие языковые модели (LLMs) сталкиваются с критическим вызовом в процессе обучения: нехваткой высококачественных интернет-данных. Прогнозы показывают, что к 2026 году доступный объем таких данных исчерпается, вынуждая исследователей обращаться к синтетическим данным для обучения. Этот сдвиг представляет как возможности, так и риски. Одни исследования показывают, что масштабирование синтетических данных может улучшить производительность на сложных задачах рассуждения, другие выявили тревожную тенденцию. Обучение на синтетических данных может потенциально привести к ухудшению производительности модели, усилению предубеждений, распространению дезинформации и укреплению нежелательных стилевых свойств. Основная задача заключается в создании синтетических данных, которые эффективно решают проблему нехватки данных, не компрометируя качество и целостность результирующих моделей. Эта задача особенно сложна из-за недостаточного понимания того, как синтетические данные влияют на поведение LLM.
Исследователи исследовали различные подходы к решению проблем обучения LLM с использованием синтетических данных. Стандартные методы, такие как принуждение экспертных данных, показали ограничения, особенно в математическом рассуждении. Усилия по созданию положительных синтетических данных направлены на имитацию высококачественных обучающих данных с использованием источников, таких как более сильные модели-учителя и самогенерируемый контент. Хотя этот подход показал себя перспективным, остаются проблемы в проверке качества синтетических математических данных. Существуют опасения по поводу усиления предубеждений, коллапса модели и переобучения на ложных шагах. Для устранения этих проблем исследователи изучают использование отрицательных модельно-сгенерированных ответов для выявления и отмены проблемных паттернов в обучающих данных.
Исследователи из Университета Карнеги-Меллон, Google DeepMind и MultiOn представляют исследование, которое исследует влияние синтетических данных на математические способности LLM. Оно рассматривает как положительные, так и отрицательные синтетические данные, обнаруживая, что положительные данные улучшают производительность, но с более медленными темпами масштабирования, чем предварительное обучение. Заметно, что самогенерируемые положительные ответы часто соответствуют эффективности в два раза большему объему данных от более крупных моделей. Они представляют надежный подход с использованием отрицательных синтетических данных, контрастируя его с положительными данными на критических шагах. Эта техника, эквивалентная взвешенному обучению с преимуществом на каждом шаге, демонстрирует потенциал увеличения эффективности вплоть до восьми раз по сравнению с использованием только положительных данных. Исследование разрабатывает законы масштабирования для обоих типов данных на общих бенчмарках рассуждения, предлагая ценные идеи по оптимизации использования синтетических данных для улучшения производительности LLM в задачах математического рассуждения.
Подробная архитектура предложенного метода включает несколько ключевых компонентов:
Synthetic Data Pipeline:
- Поддерживает модели, способные генерировать новые задачи, подобные реальным, такие как GPT-4 и Gemini 1.5 Pro.
- Получает следы решений с пошаговым рассуждением для этих задач.
- Реализует бинарную функцию вознаграждения для проверки правильности следов решений.
Dataset Construction:
- Создает положительный синтетический набор данных из правильных пар задач-решений.
- Генерирует положительные и отрицательные наборы данных с использованием модельно-сгенерированных решений.
Learning Algorithms:
- Supervised Finetuning (SFT): Обучает на 𝒟syn с использованием предсказания следующего токена.
- Rejection Finetuning (RFT): Использует политику SFT для генерации положительных ответов для проблем из 𝒟syn.
Preference Optimization:
- Использует прямую оптимизацию предпочтений (DPO) для изучения как положительных, так и отрицательных данных.
- Реализует два варианта: стандартное DPO и DPO на каждом шаге.
Эта архитектура позволяет провести всесторонний анализ различных типов синтетических данных и подходов к обучению, позволяя изучить их влияние на математические способности LLM.
Исследование раскрывает значительные идеи о масштабировании синтетических данных для математического рассуждения LLM. Масштабирование положительных данных показывает улучшение, но с более медленными темпами, чем предварительное обучение. Удивительно, что самогенерируемые положительные данные (RFT) превосходят данные более способных моделей, удваивая эффективность. Самый впечатляющий результат достигается стратегическим использованием отрицательных данных с применением преимуществ на каждом шаге прямой оптимизации предпочтений, что увеличивает эффективность данных в 8 раз по сравнению только с положительными данными. Этот подход последовательно превосходит другие методы, подчеркивая важность тщательного создания и использования как положительных, так и отрицательных синтетических данных в обучении LLM для задач математического рассуждения.
Это исследование исследует влияние синтетических данных на улучшение математических способностей LLMs. Оно показывает, что традиционные методы, использующие положительные решения от продвинутых моделей, показывают ограниченную эффективность. Самогенерируемые положительные данные от дообученных 7B моделей улучшают эффективность в 2 раза, но могут усиливать зависимость от ложных шагов. Удивительно, включение отрицательных (неправильных) следов решений решает эти ограничения. Используя отрицательные данные для оценки преимуществ пошагово и применяя техники обучения с подкреплением, исследование демонстрирует улучшение эффективности синтетических данных в 8 раз. Этот подход, использующий цели оптимизации предпочтений, значительно улучшает математические способности LLMs, эффективно балансируя положительные и отрицательные синтетические данные.
Посмотрите статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Телеграм-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 45k+ ML SubReddit.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте This AI Paper from CMU and Google DeepMind Studies the Role of Synthetic Data for Improving Math Reasoning Capabilities of LLMs .
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизацию: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`
















