

«`html
Изучение поведения обобщения в забывании навыков языковых моделей
Языковые модели (LM) привлекли значительное внимание в последние годы благодаря своим удивительным возможностям. Во время обучения этих моделей сначала происходит предварительное обучение нейронных последовательностей на большом минимально обработанном тексте из Интернета, а затем происходит тонкая настройка с использованием конкретных примеров и обратной связи от людей. Однако эти модели часто обладают нежелательными навыками или знаниями, которые создатели хотели бы убрать перед внедрением. Проблема заключается в эффективном «забывании» или удалении конкретного потенциала без потери общей производительности модели. В то время как недавние исследования сосредоточены на разработке техник для удаления целевых навыков и знаний из LM, было ограниченное оценивание того, как это забывание обобщается на другие входы.
Решения и практические выводы:
Существующие попытки решить проблему машинного «забывания» развивались от предыдущих методов, сфокусированных на удалении нежелательных данных из обучающих наборов, к более продвинутым техникам. К ним относятся методы, основанные на оптимизации, редактировании модели с использованием оценки важности параметров и градиентном восхождении на нежелательные ответы. Некоторые методы включают фреймворки для сравнения незабытых сетей с полностью переобученными, в то время как некоторые методы специфичны для больших языковых моделей (LLM), таких как подсадочные вопросы или манипулирование представлениями модели. Однако большинство этих подходов имеют ограничения в осуществимости, обобщаемости или применимости к сложным моделям, таким как LLM.
Исследователи из MIT предложили новый подход для изучения поведения обобщения в забывании навыков в LM. Этот метод включает тонкую настройку моделей на случайно помеченных данных для целевых задач, простую, но эффективную технику для вызывания забывания. Эксперименты проводятся для охарактеризации обобщения забывания и выявления нескольких ключевых результатов. Подход подчеркивает характер забывания в LMs и сложности эффективного удаления нежелательного потенциала из этих систем. Это исследование показывает сложные закономерности кросс-задачевой изменчивости в забывании и необходимость дальнейшего изучения того, какие данные, использованные для забывания, влияют на предсказания модели в других областях.
Для осуществления всесторонней оценочной рамки используется 21 задача с выбором из нескольких вариантов ответов в различных областях, таких как здравый смысл, понимание прочитанного, математика, токсичность и понимание языка. Эти задачи выбраны для охвата широкого спектра возможностей при сохранении последовательного формата с выбором из нескольких вариантов ответов. Процесс оценки следует стандартам оценки языковых моделей (LMEH) для нулевой оценки, используя стандартные подсказки и оценивая вероятности выбора. Задачи бинаризованы, и предпринимаются шаги по очистке наборов данных путем удаления перекрывающихся между обучающими и тестовыми данными и ограничению размеров выборок для сохранения последовательности. Эксперименты в основном используют базовую модель на 7-B параметров Llama2, обеспечивая прочную основу для анализа поведения забывания.
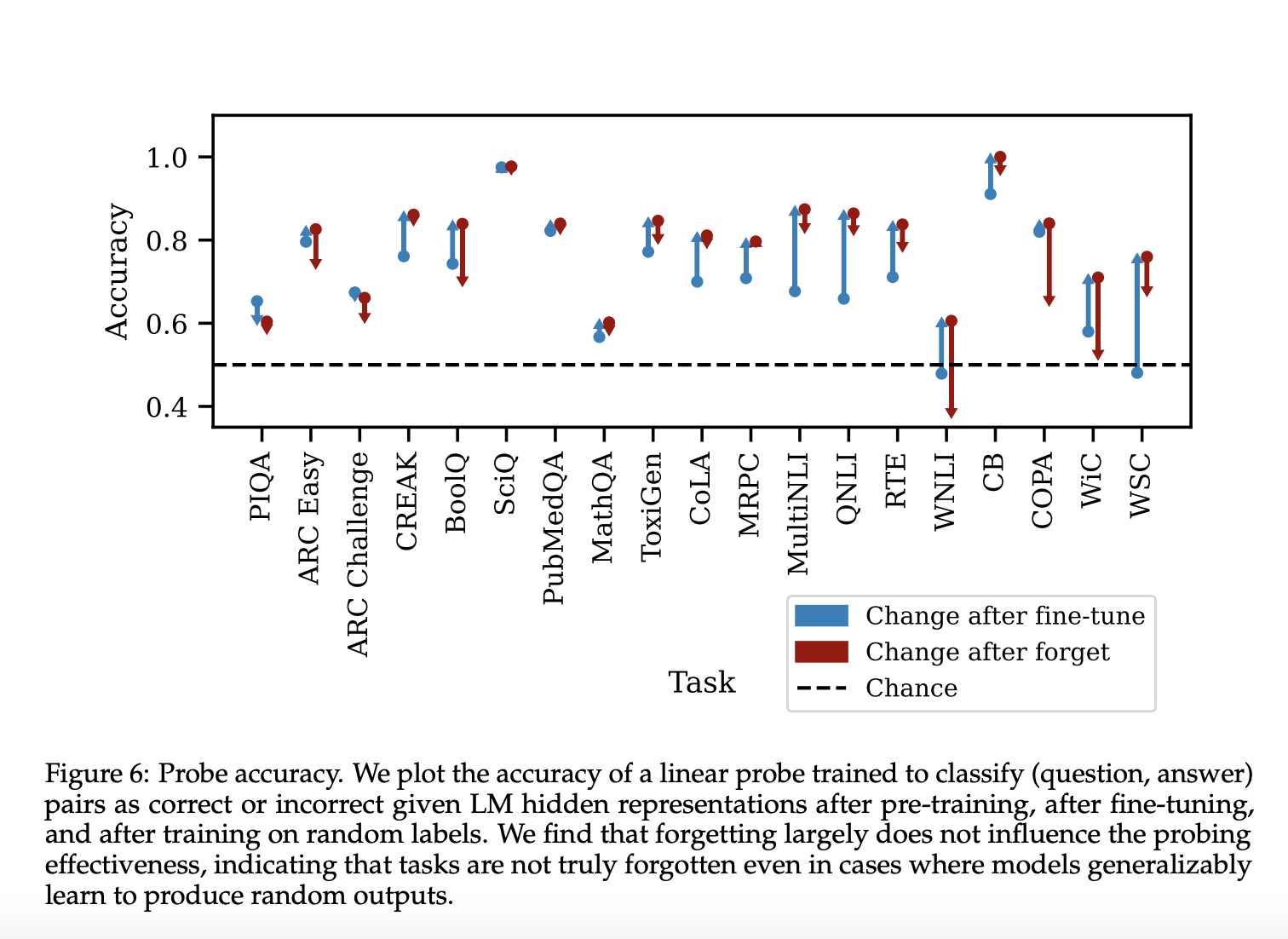
Результаты демонстрируют разнообразное поведение забывания в различных задачах. После тонкой настройки точность теста возрастает, хотя она может немного снизиться, поскольку набор проверки не идентичен набору теста. Фаза забывания производит три различные категории поведения:
- Точность забывания очень похожа на точность тонкой настройки.
- Точность забывания уменьшается, но все равно остается выше точности предварительного обучения.
- Точность забывания уменьшается до уровня ниже точности предварительного обучения и возможно до 50%.
Эти результаты подчеркивают сложную природу забывания в LMs и зависящую от задачи природу обобщения забывания.
В заключение, исследователи из MIT разработали подход для изучения поведения обобщения в забывании навыков в LM. В данной статье отмечается эффективность тонкой настройки LM на случайные ответы для вызывания забывания конкретных навыков. Оценочные задачи определяют степень забывания, и факторы, такие как сложность набора данных и уверенность модели, не предсказывают, насколько хорошо происходит забывание. Однако полная изменчивость скрытых состояний модели коррелирует с успехом забывания. Будущие исследования должны направляться на понимание того, почему некоторые примеры забываются в пределах задач и изучение механизмов объяснения процесса забывания.
«`















![6 обязательных курсов по социальным продажам на 2024 год [и советы экспертов по социальным продажам]](https://saile.ru/wp-content/uploads/2025/04/itinai.com_beautiful_Russian_high_fashion_Sales_representativ_81976356-11a7-4f61-9064-75fe15742118_0-200x200.png)


