

«`html
Vision-Language Models: Practical Solutions and Value
Видение-языковые модели: практические решения и ценность
Модели видение-язык представляют собой ключевой прорыв в области искусственного интеллекта, объединяя области компьютерного зрения и обработки естественного языка. Эти модели обеспечивают широкий спектр применений, включая описание изображений, ответы на визуальные вопросы и создание изображений по текстовым запросам, значительно улучшая возможности взаимодействия человека с компьютером.
Одной из ключевых проблем в моделировании видение-язык является выравнивание высокоразмерных визуальных данных с дискретными текстовыми данными. Это разногласие часто приводит к трудностям в точном понимании и генерации согласованных текстово-визуальных взаимодействий, требуя инновационных подходов для эффективного преодоления этой проблемы.
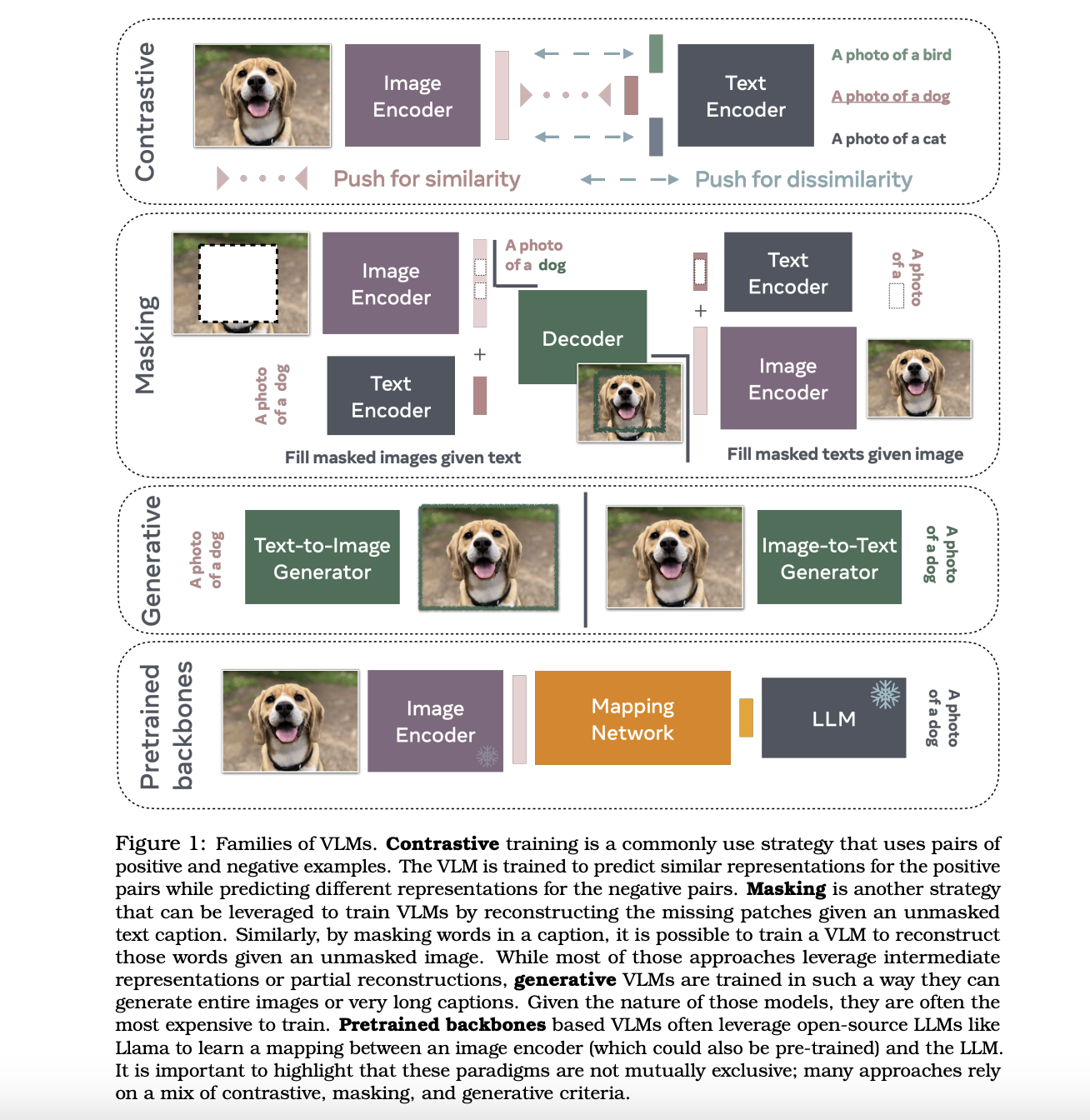
Текущие подходы к моделированию видение-язык включают контрастное обучение, стратегии маскирования и генеративные модели. Контрастные методы, такие как CLIP, обучают модели предсказывать похожие представления для связанных пар изображений и текста. Маскирование включает восстановление маскированных частей изображения или текста, а генеративные модели фокусируются на создании новых изображений или описаний на основе входных запросов.
Исследователи из Meta, MIT, NYU и других институтов в совместном усилии представили различные модели видение-язык, используя предварительно обученные основы для снижения вычислительных затрат. Эти модели применяют техники, такие как контрастная потеря, маскирование и генеративные компоненты для улучшения понимания видение-язык. Модели обычно используют архитектуру трансформера, включая кодировщики изображений и декодеры текста. Например, CLIP использует контрастную потерю для выравнивания вложений изображения и текста в общем пространстве. Генеративные модели, такие как CoCa, используют мультимодальный текстовый декодер для задач, таких как описание изображений, улучшая способность модели понимать и генерировать мультимодальный контент. Кроме того, методы, такие как VILA и LAION-aesthetics, оценивают эстетическое качество изображений для выбора высококачественных подмножеств данных, улучшая модели генерации изображений.
Глубокая методология
Методологии, используемые в моделях видение-язык, включают сложное интегрирование архитектур трансформера, кодировщиков изображений и декодеров текста. Одним из основных методов является CLIP, разработанный исследователями в OpenAI, использующий контрастную потерю для выравнивания вложений изображения и текста в общем пространстве. Этот метод позволяет модели изучать представления, эффективно охватывающие визуальную и текстовую информацию. Процесс обучения включает парное сопоставление изображений с соответствующими текстовыми описаниями, позволяя модели развивать нюансное понимание отношений между визуальными и текстовыми данными.
Генеративные модели, такие как CoCa, представленные исследователями в Google, используют другой подход, используя мультимодальный текстовый декодер. Это позволяет модели выполнять задачи, такие как описание изображений с высокой точностью. Мультимодальный текстовый декодер обучается генерировать описательные подписи для заданных изображений, улучшая способность модели производить согласованный и контекстно-релевантный текст на основе визуального ввода.
Еще одной значительной методологией является использование стратегий маскирования. Это включает случайное маскирование частей входных данных — будь то изображение или текст — и обучение модели предсказывать маскированное содержимое. Эта техника помогает улучшить устойчивость модели и ее способность обрабатывать неполные или частично видимые данные, тем самым повышая ее производительность в реальных приложениях, где данные могут быть шумными или неполными.
Производительность и результаты
Производительность моделей видение-язык тщательно оценивается с использованием различных бенчмарков. Одним из наиболее заметных результатов является модель CLIP, которая достигла замечательной точности классификации без обучения на конкретных категориях в тестовом наборе. Такая производительность демонстрирует способность модели обобщать свои данные обучения на новые, невидимые категории.
Еще одним значительным результатом является модель FLAVA, которая установила новые современные показатели производительности в ряде задач, связанных с видением, языком и мультимодальной интеграцией. Например, FLAVA продемонстрировала исключительную точность в задачах описания изображений, генерируя высококачественные подписи, точно описывающие содержание изображений. Производительность модели в задачах визуального ответа на вопросы также заслуживает внимания, с значительными улучшениями по сравнению с предыдущими моделями.
Модель LLaVA-RLHF, разработанная в сотрудничестве между MIT и NYU, достигла уровня производительности в 94% по сравнению с GPT-4. Более того, на бенчмарке MMHAL-BENCH, который направлен на минимизацию галлюцинаций и улучшение фактической точности, LLaVA-RLHF превзошла базовые модели на 60%. Эти результаты подчеркивают эффективность обучения с подкреплением от обратной связи человека (RLHF) в улучшении соответствия выходов модели ожиданиям человека и фактической точности.
Вывод
В заключение, модели видение-язык представляют собой значительный прорыв в области искусственного интеллекта, предлагая мощные инструменты для интеграции визуальных и текстовых данных. Применяемые методологии, включая контрастное обучение, генеративное моделирование и стратегии маскирования, доказали свою эффективность в решении проблем выравнивания высокоразмерных визуальных данных с дискретными текстовыми данными. Впечатляющие результаты производительности, достигнутые моделями, такими как CLIP, FLAVA и LLaVA-RLHF, подчеркивают потенциал этих технологий для трансформации широкого спектра приложений, от описания изображений до визуального ответа на вопросы. Постоянные исследования и разработки в этой области обещают дальнейшее улучшение возможностей моделей видение-язык и расширение их применения.
Проверьте статью. Вся заслуга за этот исследовательский проект принадлежит исследователям. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 43k+ ML SubReddit | Также, ознакомьтесь с нашей платформой AI Events Platform
Статья опубликована на портале MarkTechPost.
«`


















