

«`html
Важность Данных для Улучшения Производительности LLM
Крупные языковые модели (LLM) привлекли значительное внимание в последние годы. Один из ключевых вызовов в их разработке заключается в понимании влияния данных предварительного обучения на общие возможности моделей.
Исследования и Практические Решения
Исследователи предприняли множество попыток понять и улучшить производительность LLM через манипуляцию данными. Они изучали влияние возраста, качества, токсичности и области данных, а также исследовали методы фильтрации, удаления дубликатов и обрезки данных.
Включение Кода в Модели Предварительного Обучения
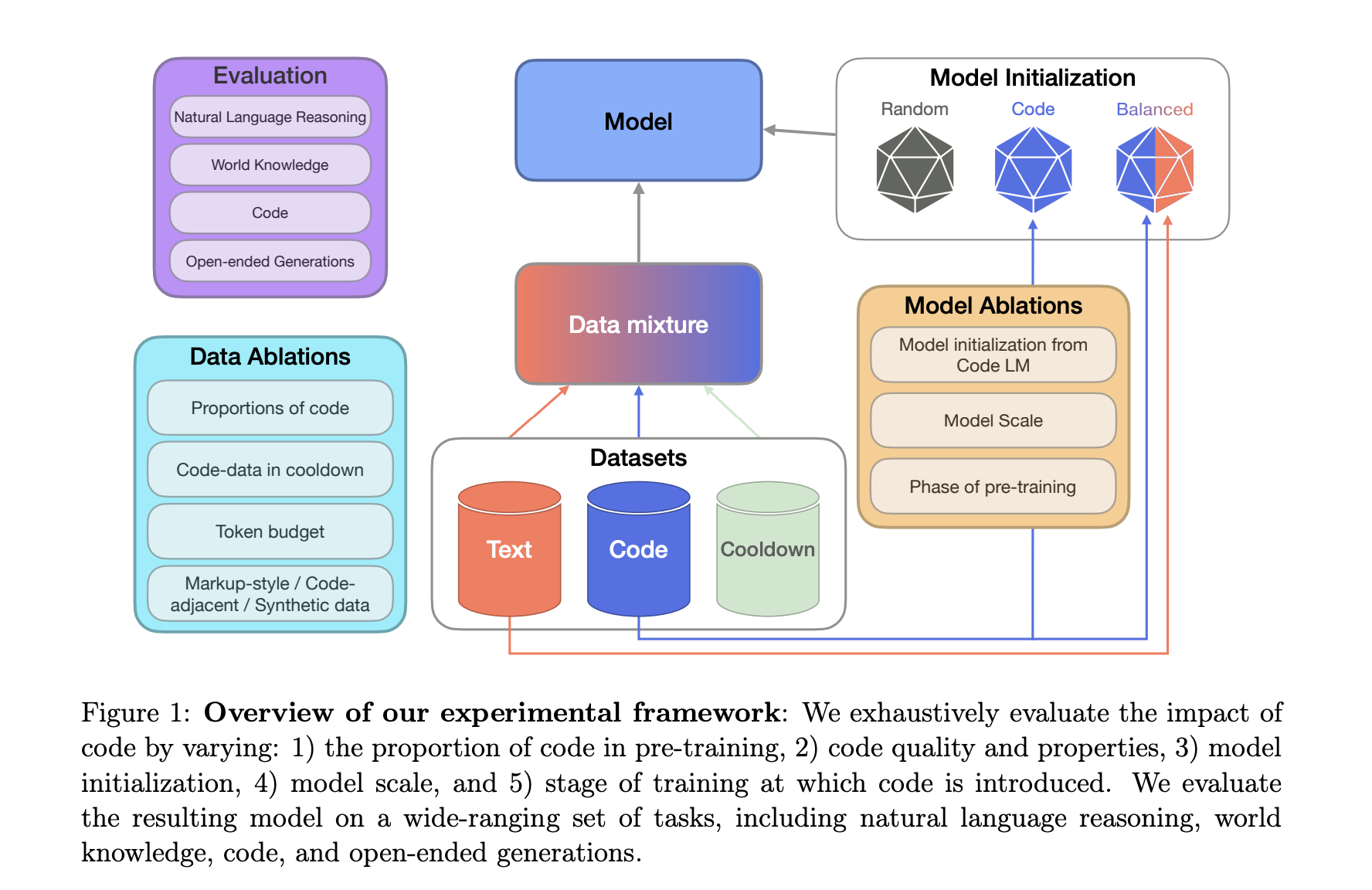
Добавление кода в смеси предварительного обучения стало общей практикой, даже для моделей, не предназначенных для работы с кодом. Предыдущие исследования показывают, что код улучшает производительность LLM на различных задачах обработки естественного языка. Однако полное понимание влияния кода на не-кодовые задачи все еще не получило систематического изучения.
Структурированные Эксперименты и Результаты
Исследователи из Cohere For AI и Cohere провели обширные контролируемые эксперименты по предварительному обучению, чтобы изучить влияние кода на производительность LLM. Основные результаты показали значительное улучшение производительности моделей при включении данных кода в предварительное обучение.
«`


















