

«`html
Исследование мультимодальных больших языковых моделей (MLLMs)
Исследование мультимодальных больших языковых моделей (MLLMs) фокусируется на интеграции визуальных и текстовых данных для улучшения способностей искусственного интеллекта в рассуждении. Путем объединения этих модальностей MLLMs могут интерпретировать сложную информацию из различных источников, таких как изображения и текст, что позволяет им выполнять задачи, такие как визуальное ответ на вопросы и решение математических задач с большей точностью и проницательностью. Этот междисциплинарный подход использует преимущества визуальных и языковых данных с целью создания более надежных систем искусственного интеллекта, способных понимать и взаимодействовать с миром, как люди.
Создание комплексного датасета и моделей для повышения математического рассуждения MLLMs
Одной из значительных проблем в разработке эффективных MLLMs является их неспособность решать сложные математические задачи, включающие визуальный контент. Несмотря на их умение решать текстовые математические задачи, эти модели часто нуждаются в улучшении в интерпретации и рассуждении через визуальную информацию. Это обстоятельство подчеркивает необходимость улучшенных датасетов и методологий, которые бы лучше интегрировали мультимодальные данные. Исследователи стремятся создать модели, способные понимать текст и извлекать содержательные выводы из изображений, диаграмм и других визуальных пособий, критически важных в областях образования, науки и технологий.
Практические решения и результаты исследования
Существующие методы для улучшения математического рассуждения MLLMs включают методы подсказок и тонкой настройки. Методы подсказок используют скрытые способности моделей через тщательно разработанные подсказки, в то время как методы тонкой настройки корректируют параметры модели, используя данные рассуждений из реальных или синтетических источников. Однако текущие открытые наборы данных для обучения моделей на изображениях ограничены по объему и содержат небольшое количество пар вопрос-ответ на изображение, что ограничивает способность моделей полноценно использовать визуальную информацию. Ограничения этих наборов данных затрудняют разработку MLLMs и требуют создания более полных и разнообразных наборов данных для эффективного обучения этих моделей.
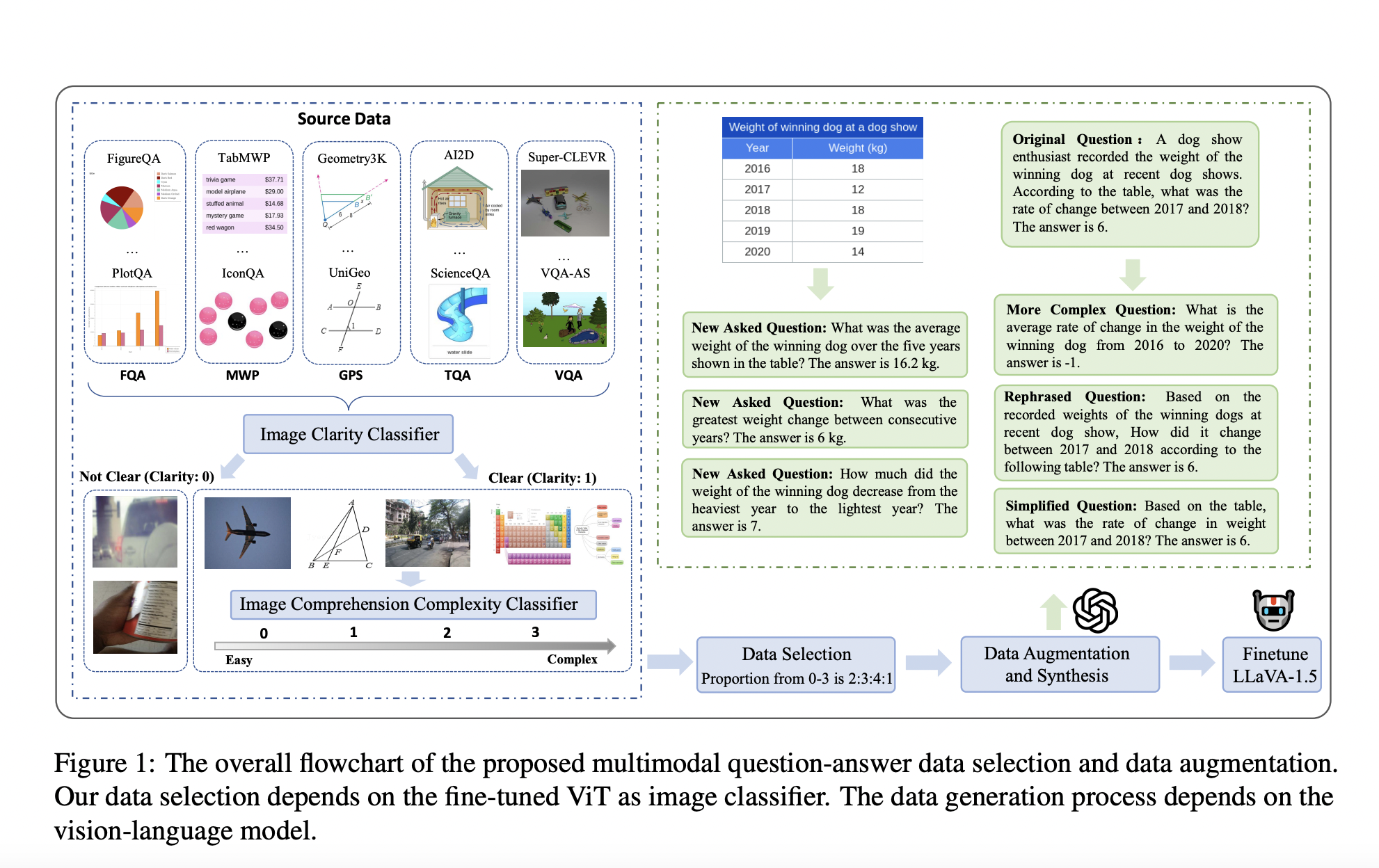
Исследователи из различных институтов, включая Университет электроники и технологии Китая, Сингапурский университет технологий и дизайна, Университет Тунджи и Национальный университет Сингапура, представили Math-LLaVA, модель, тонко настроенную с помощью нового набора данных под названием MathV360K. Этот набор данных включает 40 тыс. высококачественных изображений и 320 тыс. синтезированных пар вопрос-ответ, разработанных для улучшения широты и глубины мультимодальных математических рассуждений. Представление Math-LLaVA является значительным прорывом в этой области, устраняя пробелы, оставленные предыдущими наборами данных и методами.
Набор данных MathV360K был создан путем выбора 40 тыс. высококачественных изображений из 24 уже существующих наборов данных, с фокусом на предметы, такие как алгебра, геометрия и визуальное ответ на вопросы. Исследователи синтезировали 320 тыс. новых пар вопрос-ответ на основе этих изображений для улучшения разнообразия и сложности набора данных. Этот комплексный набор данных был использован для тонкой настройки модели LLaVA-1.5, что привело к созданию Math-LLaVA. Процесс выбора этих изображений включал строгие критерии для обеспечения ясности и сложности с целью охвата широкого спектра математических концепций и типов вопросов. Синтез дополнительных пар вопрос-ответ включал генерацию разнообразных вопросов, проверяющих различные аспекты изображений и требующих несколько шагов рассуждений, что дополнительно усилило надежность набора данных.
Math-LLaVA продемонстрировала значительные улучшения, достигнув повышения на 19 процентных пунктов на минутном разделении MathVista по сравнению с исходной моделью LLaVA-1.5. Более того, она проявила улучшенную обобщаемость и успешно прошла тестирование на стандартных наборах данных. Конкретно, Math-LLaVA достигла точности 57.7% на поднаборе GPS, превзойдя G-LLaVA-13B, обученную на 170 тыс. высококачественных геометрических изображений с подписями и парами вопрос-ответ. Эти результаты подчеркивают эффективность разнообразного и комплексного набора данных MathV360K в улучшении мультимодальных математических рассуждений MLLMs. Производительность модели на различных стандартных тестах подчеркивает ее способность обобщаться на различные математические задачи, делая ее ценным инструментом для широкого спектра приложений.
Заключение и перспективы
Данное исследование подчеркивает критическую необходимость высококачественных и разнообразных мультимодальных наборов данных для улучшения математических рассуждений в MLLMs. Путем разработки и тонкой настройки Math-LLaVA с помощью MathV360K исследователи значительно улучшили производительность и обобщаемость модели, продемонстрировав важность разнообразия и синтеза наборов данных для продвижения возможностей искусственного интеллекта. Набор данных MathV360K и модель Math-LLaVA представляют собой значительный прогресс в данной области, предоставляя прочную основу для будущих исследований и разработок. Эта работа не только подчеркивает потенциал MLLMs трансформировать различные области путем интеграции визуальных и текстовых данных, но и вдохновляет надежду на будущее искусственного интеллекта, прокладывая путь к созданию более сложных и способных систем искусственного интеллекта.
Посмотрите статью. Вся заслуга за это исследование принадлежит ученым этого проекта. Также, не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему Reddit-сообществу.
Math-LLaVA: A LLaVA-1.5-based AI Model Fine-Tuned with MathV360K Dataset
«`



















