

Преодоление ограничений LLM с помощью метода Source2Synth
Проблемы с LLM и их решение
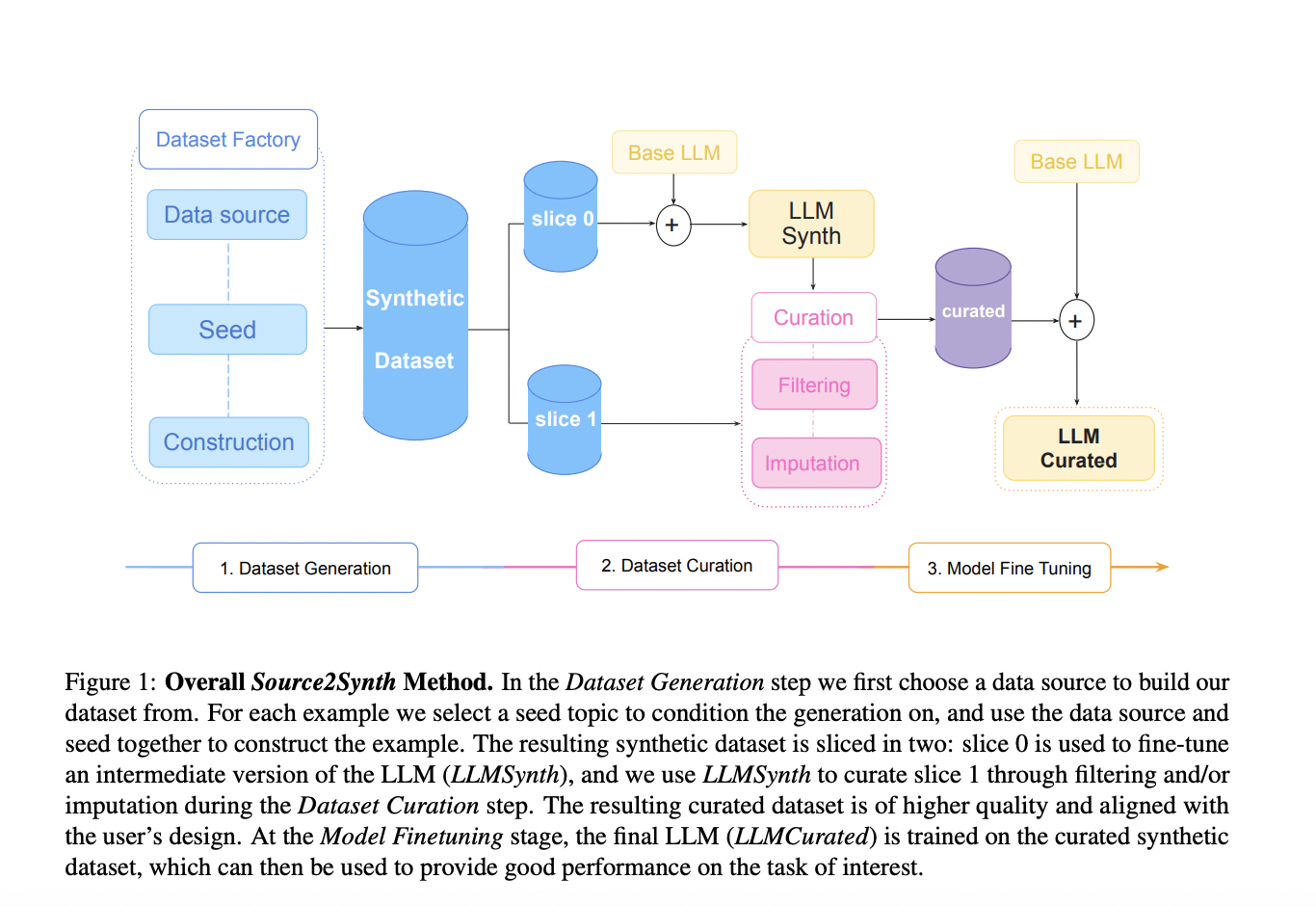
Большие языковые модели (LLM) успешно работают с неструктурированным текстом, но испытывают трудности при обработке структурированных данных, таких как таблицы и базы данных. Для решения этих проблем исследователи из Meta, Оксфордского университета и Университета Лондона представили метод Source2Synth. Он позволяет обучать LLM новым навыкам без дорогостоящих и долгих процессов ручной разметки данных.
Применение метода Source2Synth
Используя реальные данные, Source2Synth создает синтетические примеры с промежуточными шагами логического вывода. Техника фильтрации гарантирует качество данных, и метод был успешно применен в двух областях:
- Многошаговый вопросно-ответный анализ (MHQA): Source2Synth превзошел базовые модели на 22,57% при работе с данными HotPotQA.
- Вопросно-ответный анализ с использованием структурированных данных (TQA): Source2Synth улучшил результаты на 25,51% по сравнению с базовыми моделями на наборе данных WikiSQL.
Заключение
Метод Source2Synth помогает повысить производительность LLM в сложных задачах, не требуя большого количества ручной разметки данных. Это уникальное решение для обучения LLM новым навыкам в области структурированных данных и многошагового рассуждения, обеспечивая высокое качество обучающих примеров.


















