

«`html
Выпуск Tulu 2.5 Suite от Allen Institute for AI
Выпуск пакета Tulu 2.5 от Allen Institute for AI представляет собой значительный прогресс в области обучения моделей с использованием методов прямой оптимизации предпочтений (DPO) и оптимизации ближайшей политики (PPO). Пакет Tulu 2.5 включает разнообразные модели, обученные на различных наборах данных для улучшения их моделей вознаграждения и ценности. Этот пакет призван существенно улучшить производительность языковых моделей в различных областях, включая генерацию текста, следование инструкциям и рассуждения.
Обзор пакета Tulu 2.5
Пакет Tulu 2.5 включает коллекцию моделей, тщательно обученных с использованием методов DPO и PPO. Эти модели используют наборы данных предпочтений, которые критически важны для улучшения производительности языковых моделей путем интеграции человекоподобных предпочтений в их процесс обучения. Пакет направлен на улучшение различных возможностей языковых моделей, таких как достоверность, безопасность, кодирование и рассуждения, делая их более надежными и устойчивыми для различных приложений.
Пакет Tulu 2.5 включает несколько вариантов моделей, каждая из которых настроена на конкретные задачи и оптимизирована с использованием различных наборов данных и методологий. Вот некоторые заметные варианты:
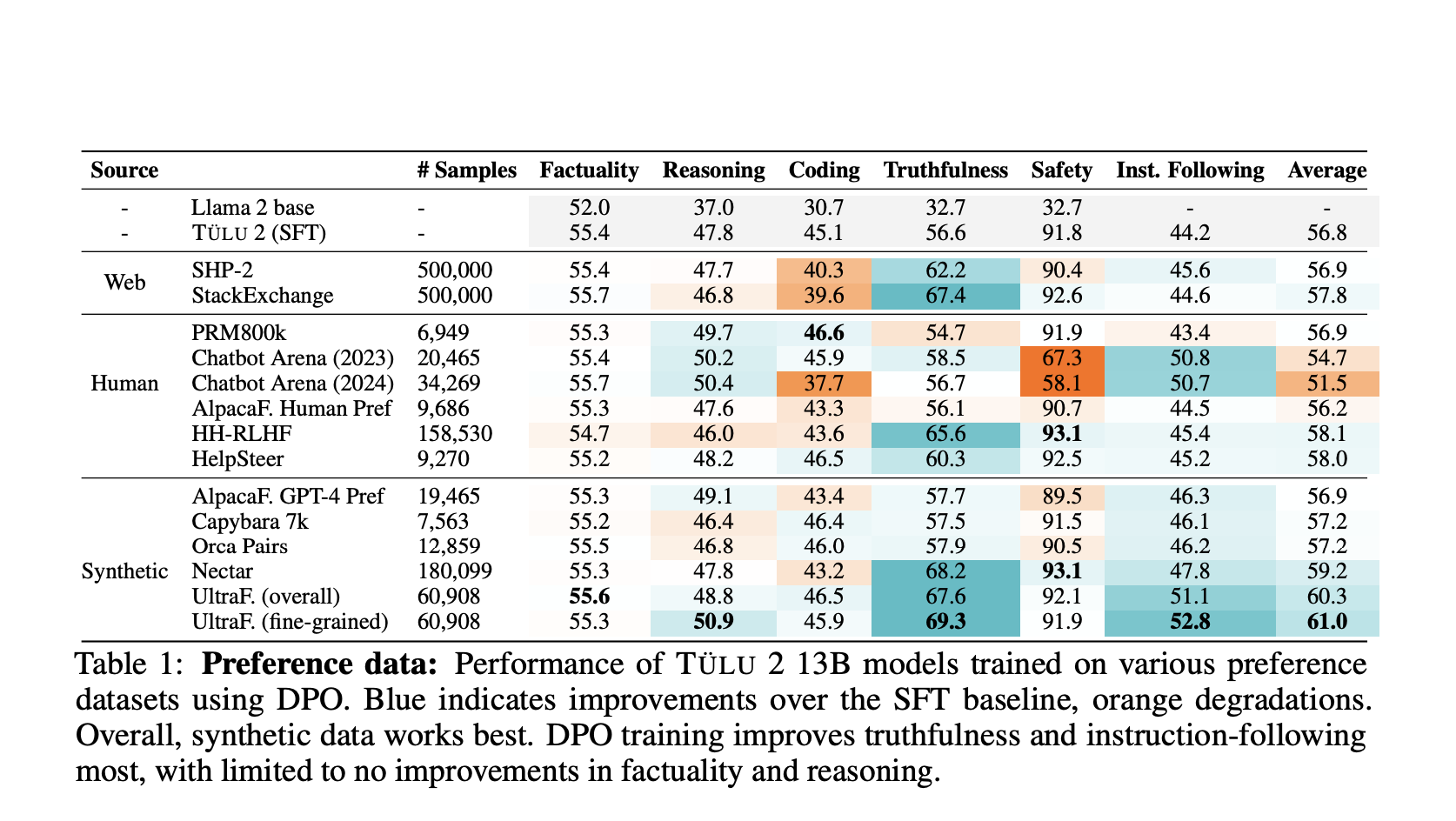
- Tulu 2.5 PPO 13B UF Mean 70B UF RM: Лучшая модель в пакете, обученная с использованием PPO с 70-миллиардным параметрическим моделью вознаграждения, обученной на данных UltraFeedback. Эта комбинация показала превосходную производительность в задачах генерации текста.
- Tulu 2.5 PPO 13B Chatbot Arena 2023: Этот вариант улучшает возможности чат-ботов, специально обученный с использованием данных из Chatbot Arena 2023, включающих разнообразные подсказки и ответы для улучшения разговорных способностей и качества взаимодействия с пользователем.
- и другие…
Ключевые компоненты и методологии обучения
Наборы данных предпочтений: Основа пакета Tulu 2.5 построена на высококачественных наборах данных предпочтений. Эти наборы данных состоят из подсказок, ответов и рейтингов, которые помогают обучать модели приоритезировать ответы, соответствующие человеческим предпочтениям.
DPO против PPO: Пакет использует как методику DPO, так и PPO. DPO, подход обучения с усилением в офлайн-режиме, оптимизирует политику напрямую на данных предпочтений без необходимости генерации ответов в реальном времени. С другой стороны, PPO включает начальный этап обучения модели вознаграждения, за которым следует оптимизация политики с использованием генерации ответов в реальном времени. Этот двойной подход позволяет пакету получить преимущества обеих методологий, что приводит к превосходной производительности в различных бенчмарках.
Модели вознаграждения и ценности: Пакет Tulu 2.5 включает различные модели вознаграждения, обученные на обширных наборах данных. Эти модели вознаграждения критически важны для оценки сгенерированных ответов, направления процесса оптимизации и улучшения производительности модели. Модели ценности, включенные в пакет, помогают в классификации токенов и других связанных задачах, способствуя общей эффективности пакета.
Производительность и оценка
Модели Tulu 2.5 прошли тщательную оценку по различным бенчмаркам. Оценка охватывает критические области, такие как достоверность, рассуждения, кодирование, следование инструкциям и безопасность. Результаты показывают, что модели, обученные с использованием PPO, в целом превосходят те, которые обучены с использованием DPO, особенно в рассуждениях, кодировании и безопасности.
Заметные улучшения
Следование инструкциям и достоверность: Пакет Tulu 2.5 значительно улучшает следование инструкциям и достоверность, превосходя базовые модели с использованием высококачественных данных предпочтений. Это улучшение особенно заметно в связи с чат-возможностями, где модели лучше следуют инструкциям пользователя и предоставляют достоверные ответы.
Масштабируемость: Пакет включает различные размеры, с моделями вознаграждения, масштабированными до 70 миллиардов параметров. Это масштабируемость позволяет пакету удовлетворять различные вычислительные мощности, сохраняя высокую производительность. При использовании моделей вознаграждения во время обучения PPO, более крупные модели вознаграждения приводят к заметным улучшениям в конкретных областях, таких как математика.
Синтетические данные: Синтетические наборы данных предпочтений, такие как UltraFeedback, доказали свою эффективность в улучшении производительности моделей. Эти наборы данных, аннотированные с предпочтениями по аспектам, предлагают детальный и тонкий подход к обучению на основе предпочтений, что приводит к моделям, лучше понимающим и приоритезирующим предпочтения пользователей.
Выпуск пакета Tulu 2.5 подчеркивает важность непрерывного исследования и совершенствования алгоритмов обучения, моделей вознаграждения и данных предпочтений. Будущая работа, вероятно, будет направлена на оптимизацию этих компонентов для достижения еще больших улучшений производительности. Расширение пакета для включения более разнообразных и всесторонних наборов данных будет критически важным для поддержания его актуальности и эффективности в постоянно изменяющемся ландшафте искусственного интеллекта.
В заключение, пакет Tulu 2.5 от Allen Institute for AI представляет собой значительный прорыв в обучении языковых моделей на основе предпочтений. Этот пакет устанавливает новый стандарт производительности и надежности моделей искусственного интеллекта путем интеграции передовых методов обучения и использования высококачественных наборов данных.
Проверьте Статью и Модели. Вся благодарность за этот проект исследователям. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Телеграм-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему 44k+ ML SubReddit.
Статья Allen Institute for AI Releases Tulu 2.5 Suite on Hugging Face: Advanced AI Models Trained with DPO and PPO, Featuring Reward and Value Models была опубликована на MarkTechPost.
«`
















