

«`html
Важность оптимизации прямого предпочтения (DPO) в обучении языковых моделей
Оптимизация прямого предпочтения (DPO) представляет собой передовой метод обучения для тонкой настройки больших языковых моделей (LLM). В отличие от традиционного контролируемого обучения, зависящего от одного эталонного значения, DPO обучает модели различать качество различных кандидатских результатов. Эта техника крайне важна для согласования LLM с человеческими предпочтениями и улучшения их способности эффективно генерировать желаемые ответы. Путем внедрения методов обучения с подкреплением DPO позволяет моделям учиться на обратной связи, что делает его ценным подходом в обучении языковых моделей.
Проблемы и решения
Основная проблема, рассмотренная в данном исследовании, заключается в ограничениях, накладываемых зависимостью от эталонных моделей или политик в процессе DPO. Хотя они важны для поддержания стабильности и направления в обучении, эти эталоны могут ограничить потенциальные улучшения производительности LLM. Понимание оптимального использования и силы этих эталонов важно для максимизации эффективности и качества выходных данных обученных с помощью DPO моделей.
Текущие методы в обучении предпочтений включают контролируемую настройку (SFT), методы обучения с подкреплением (RL) и техники обучения на основе вознаграждения. SFT основан на одном эталонном значении, в то время как RL и методы на основе вознаграждения, такие как контрастное обучение, обучают модели ранжировать и предпочитать лучшие результаты на основе обратной связи. DPO включает в себя ограничение KL-дивергенции для управления отклонениями от эталонной модели. Это ограничение гарантирует, что модель не отклоняется слишком сильно от эталона, соблюдая баланс соблюдения эталона с оптимизацией производительности.
Практические результаты и рекомендации
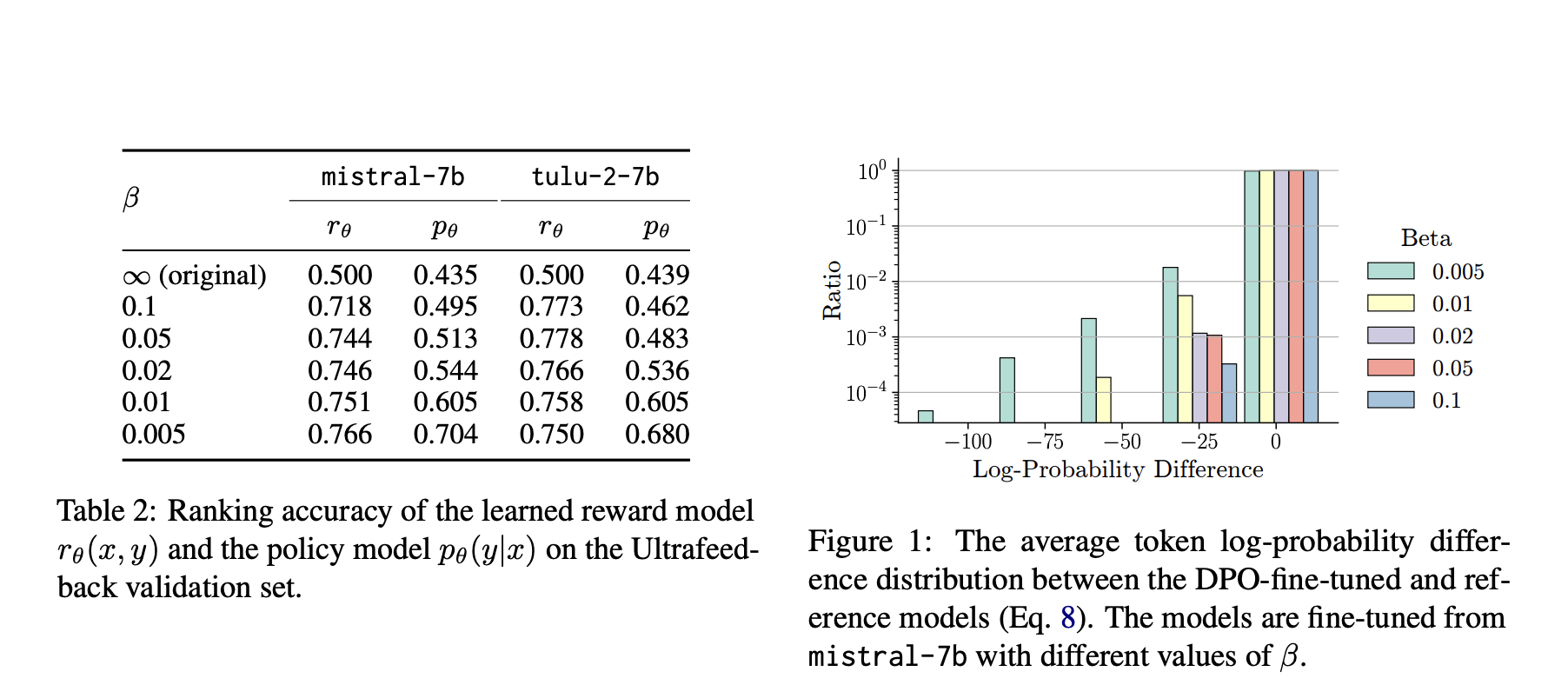
Исследование выявило значительные результаты влияния ограничения KL-дивергенции на производительность DPO. Меньшее ограничение обычно приводило к лучшей производительности, с оптимальным значением β около 0,01-0,02. Кроме того, более сильные эталонные модели, такие как Mistral-v0.2 и Llama-3-70b, предоставляли дополнительные преимущества, но только при совместимости с настроенной моделью. Исследование подчеркивает важность выбора подходящей эталонной политики для достижения оптимальных результатов.
Результаты подчеркивают тонкую роль эталонных политик в DPO. Тщательная калибровка силы ограничения и выбор совместимых эталонных моделей может значительно улучшить производительность LLM. На основе этого исследования предоставляются ценные практические рекомендации для улучшения DPO и продвижения области тонкой настройки языковых моделей.
Подробнее ознакомьтесь с статьей и GitHub.
Не забудьте подписаться на наш Twitter и присоединиться к нашей группе в LinkedIn. Если вам понравилась наша работа, вам понравится наш рассылка.
Присоединяйтесь к нашему SubReddit с более чем 47 тыс. подписчиков.
Находите предстоящие вебинары по ИИ здесь.
Источник: MarkTechPost.
«`



















