

«`html
Современные решения маркетинга и продаж
Преодоление ограничений в масштабировании системы за счет использования многоАгентного Обучения с Подкреплением
Основная проблема в масштабировании систем искусственного интеллекта (ИИ) заключается в достижении эффективного принятия решений при сохранении производительности. Распределенный ИИ, в частности многоАгентное Обучение с Подкреплением (MARL), предлагает потенциал, декомпозируя сложные задачи и распределяя их между совместными узлами. Однако в реальных приложениях сталкиваются с ограничениями из-за высоких требований к коммуникации и данным. Традиционные методы, такие как модельное предсказывающее управление (MPC), требуют точной динамики системы и часто упрощают нелинейные сложности. MARL, хотя и обещающий в областях автономного вождения и энергосистем, все еще борется с эффективным обменом информацией и масштабируемостью в сложных реальных средах из-за ограничений коммуникации и нереалистичных предположений.
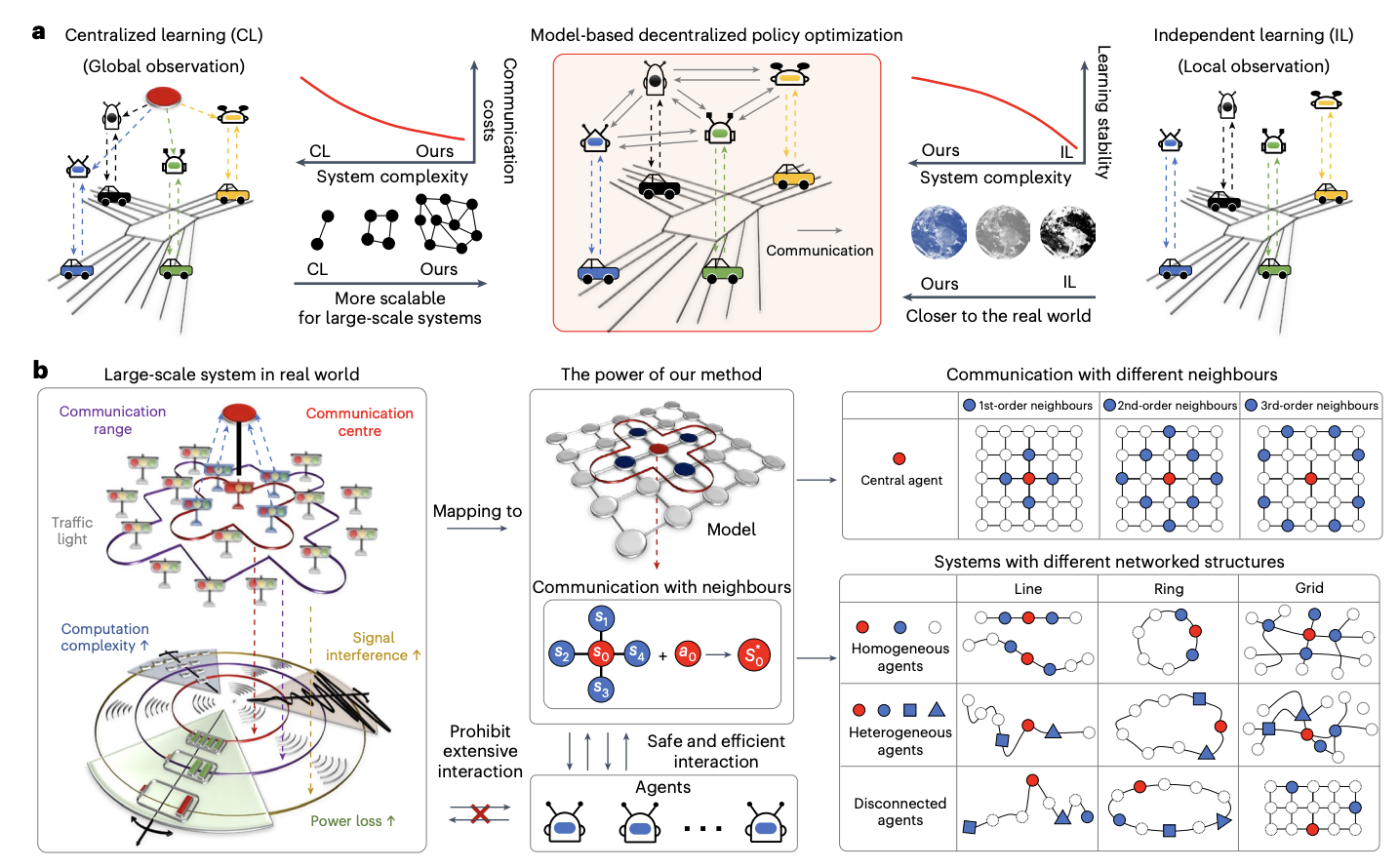
Исследователи Университета Пекина и Королевского Колледжа Лондона разработали децентрализованную схему оптимизации политики для многоАгентных систем. Путем использования локальных наблюдений через топологическое расщепление глобальной динамики они позволяют точную оценку международной информации. Их подход интегрирует изучение моделей для улучшения оптимизации политики с ограниченными данными. В отличие от предыдущих методов, эта схема улучшает масштабируемость путем уменьшения коммуникации и сложности системы. Эмпирические результаты в различных сценариях, включая транспорт и энергосистемы, демонстрируют ее эффективность в управлении масштабными системами с сотнями агентов. Она предлагает превосходную производительность в реальных приложениях с ограниченной коммуникацией и гетерогенными агентами.
В децентрализованной модельной схеме оптимизации политики каждый агент поддерживает локализованные модели, предсказывающие будущие состояния и вознаграждения, наблюдая за своими действиями и состояниями своих соседей. Политики оптимизируются с помощью двух буферов опыта: один для данных из реальной среды и другой для модельных данных. Используется ветвистая техника прокрутки, чтобы предотвратить накопление ошибок, запуская модельные прогнозы из случайных состояний в предыдущих траекториях для повышения точности. Обновления политики включают локализованные функции стоимости и используют агентов PPO, гарантируя улучшение политики путем постепенного минимизирования аппроксимации и зависимостей во время обучения.
Методы описывают сетевой Марковский процесс принятия решений (MDP) с несколькими агентами, представленными в виде узлов в графе. Каждый агент общается с соседями, чтобы оптимизировать децентрализованную политику обучения с подкреплением для улучшения локальных вознаграждений и производительности глобальной системы. Рассматриваются два типа систем: независимые сетевые системы (INS), где взаимодействия агентов минимальны, и системы, зависящие от ξ, которые учитывают уменьшающееся влияние с расстоянием. Подход изучения на основе моделей аппроксимирует динамику системы, обеспечивая монотонное улучшение политики. Этот метод тестировался в масштабных сценариях, таких как управление транспортом и энергосистемами, с акцентом на децентрализованное управление агентов для оптимальной производительности.
Исследование демонстрирует превосходную производительность децентрализованной схемы MARL, протестированной как в симуляторах, так и в реальных системах. По сравнению с централизованными базовыми моделями, такими как MAG и CPPO, подход значительно снижает затраты на коммуникацию (5-35%), улучшая сходимость и эффективность выборки. Метод хорошо себя показал в контрольных задачах, таких как управление транспортом и сигналами светофора, управление сетью пандемий и операции с энергосетями, последовательно превзойдя базовые модели. Более короткие длины прокрутки и оптимизированный выбор соседей улучшили прогнозы моделей и результаты обучения. Эти результаты подчеркивают масштабируемость схемы и ее эффективность в управлении масштабными сложными системами.
В заключение, исследование представляет масштабируемую схему MARL, эффективную для управления крупными системами с сотнями агентов, превосходящую возможности предыдущих децентрализованных методов. Подход использует минимальный обмен информацией для оценки глобальных условий, аналогично теории «шесть степеней разделения». Он интегрирует модельную децентрализованную оптимизацию политики, что улучшает эффективность принятия решений и масштабируемость путем снижения требований к коммуникации и данным. Сосредотачиваясь на локальных наблюдениях и совершенствуя политики через изучение моделей, схема поддерживает высокую производительность даже при увеличении размера системы. Результаты подчеркивают ее потенциал для продвинутых приложений в управлении трафиком, энергией и управлении пандемиями.
Подробнее см. статью. Все заслуги за это исследование принадлежат его ученым. Также не забудьте следить за нами на Twitter и LinkedIn. Присоединяйтесь к нашему Telegram-каналу.
«`

















