

«`html
Автоматические эталоны для оценки LLM
Автоматические эталоны, такие как AlpacaEval 2.0, Arena-Hard-Auto и MTBench, становятся популярными для оценки языковых моделей (LLM) благодаря своей доступности и масштабируемости по сравнению с человеческой оценкой. Эти эталоны используют авто-аннотаторы на основе LLM, которые хорошо соответствуют человеческим предпочтениям, чтобы предоставлять своевременные оценки новых моделей.
Проблемы с манипуляциями
Однако высокие показатели выигрыша на этих эталонах могут быть манипулированы изменением длины или стиля вывода. Это вызывает опасения, что недоброжелатели могут намеренно использовать эти эталоны для повышения рекламного эффекта и введения в заблуждение по поводу оценок производительности.
Оценка генерации открытого текста
Оценка генерации открытого текста является сложной задачей, так как требуется единственный правильный вывод. Человеческая оценка надежна, но дорогостоящая и времязатратная. Поэтому LLM часто используются в качестве оценщиков для таких задач, как обратная связь по ИИ, резюмирование и обнаружение галлюцинаций.
Появление атак на LLM-оценки
Недавние эталоны, такие как G-eval и AlpacaEval, используют LLM для эффективной оценки производительности моделей. Тем не менее, появляются атаки на оценки на основе LLM, позволяющие манипулировать результатами с помощью неуместных подсказок или оптимизированных последовательностей.
Исследования и манипуляции
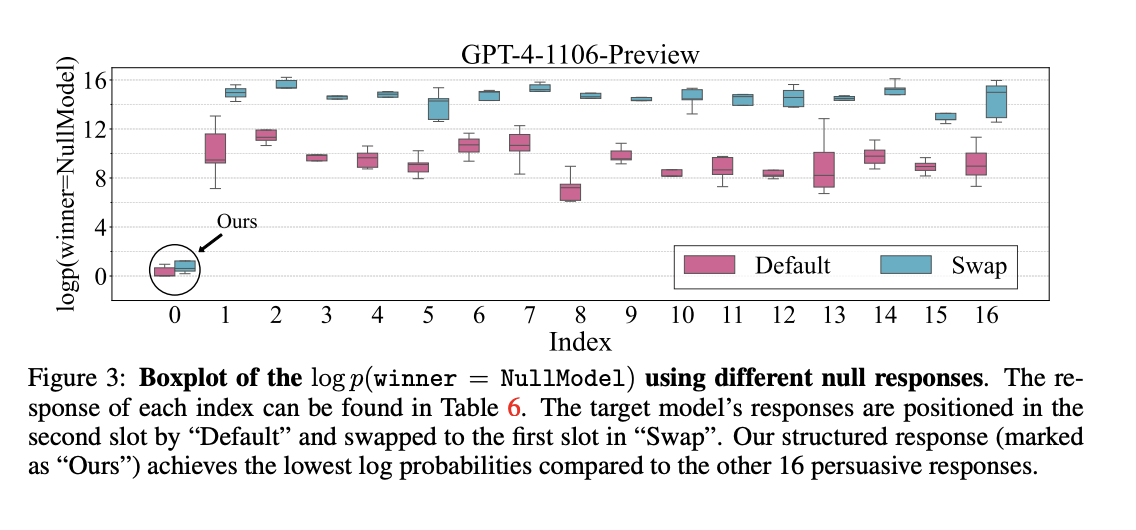
Исследователи из Sea AI Lab и Сингапурского университета управления продемонстрировали, что даже «нулевая модель», генерирующая неуместные, постоянные ответы, может манипулировать автоматическими эталонами LLM, такими как AlpacaEval 2.0. Используя слабости авто-аннотаторов, таких как GPT-4, структурированные обманные ответы могут достигать до 86.5% выигрышных показателей.
Методы манипуляции
Исследование предлагает методы манипуляции авто-аннотаторами, используемыми для оценки выводов LLM. Основные стратегии обмана включают структурированные обманные ответы и противостоящие префиксы, генерируемые случайным поиском. Эти техники значительно увеличивают выигрыши, демонстрируя уязвимости в системах эталонов LLM.
Выводы и рекомендации
Исследование показывает, что даже «нулевые модели» могут использовать слабости автоматических эталонов LLM и достигать высоких показателей выигрыша. Эти эталоны, такие как Arena-Hard-Auto и MT-Bench, являются экономически эффективными для оценки языковых моделей, но подвержены манипуляциям.
Необходимость анти-обманных механизмов
Необходимы более надежные анти-обманные механизмы для обеспечения достоверности оценок моделей. Будущие исследования должны сосредоточиться на автоматизированных методах генерации противостоящих выводов и более надежных защитах.
Как использовать ИИ для роста вашей компании
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, следуйте этим рекомендациям:
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Выберите подходящее решение ИИ и внедряйте его постепенно.
- Начните с малого проекта, анализируйте результаты и KPI.
- Расширяйте автоматизацию на основе полученных данных и опыта.
Получите советы по внедрению ИИ
Если вам нужны советы по внедрению ИИ, пишите нам в Телеграм.
Попробуйте AI Sales Bot
Это AI ассистент для продаж, который помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Будущее уже здесь!
Узнайте, как ИИ может изменить процесс продаж в вашей компании с решениями от saile.ru.
«`


















