

«`html
NVIDIA представила модель Mistral-NeMo-Minitron 8B
NVIDIA представила модель Mistral-NeMo-Minitron 8B, высокотехнологичную крупную языковую модель (LLM). Эта модель продолжает работу по разработке передовых технологий искусственного интеллекта. Она выделяется своим впечатляющим производительством по различным критериям, что делает ее одной из самых передовых моделей в своем классе.
Процесс обрезания модели и дистилляции знаний
Обрезка модели — это техника уменьшения размера и увеличения эффективности моделей искусственного интеллекта путем удаления менее критических компонентов. Существуют два основных типа обрезки: обрезка глубины, которая уменьшает количество слоев в модели, и обрезка ширины, которая уменьшает количество нейронов, внимательных голов и встраивающих каналов в каждом слое. В случае модели Mistral-NeMo-Minitron 8B была выбрана обрезка ширины, чтобы достичь оптимального баланса между размером и производительностью.
Производительность и бенчмаркинг
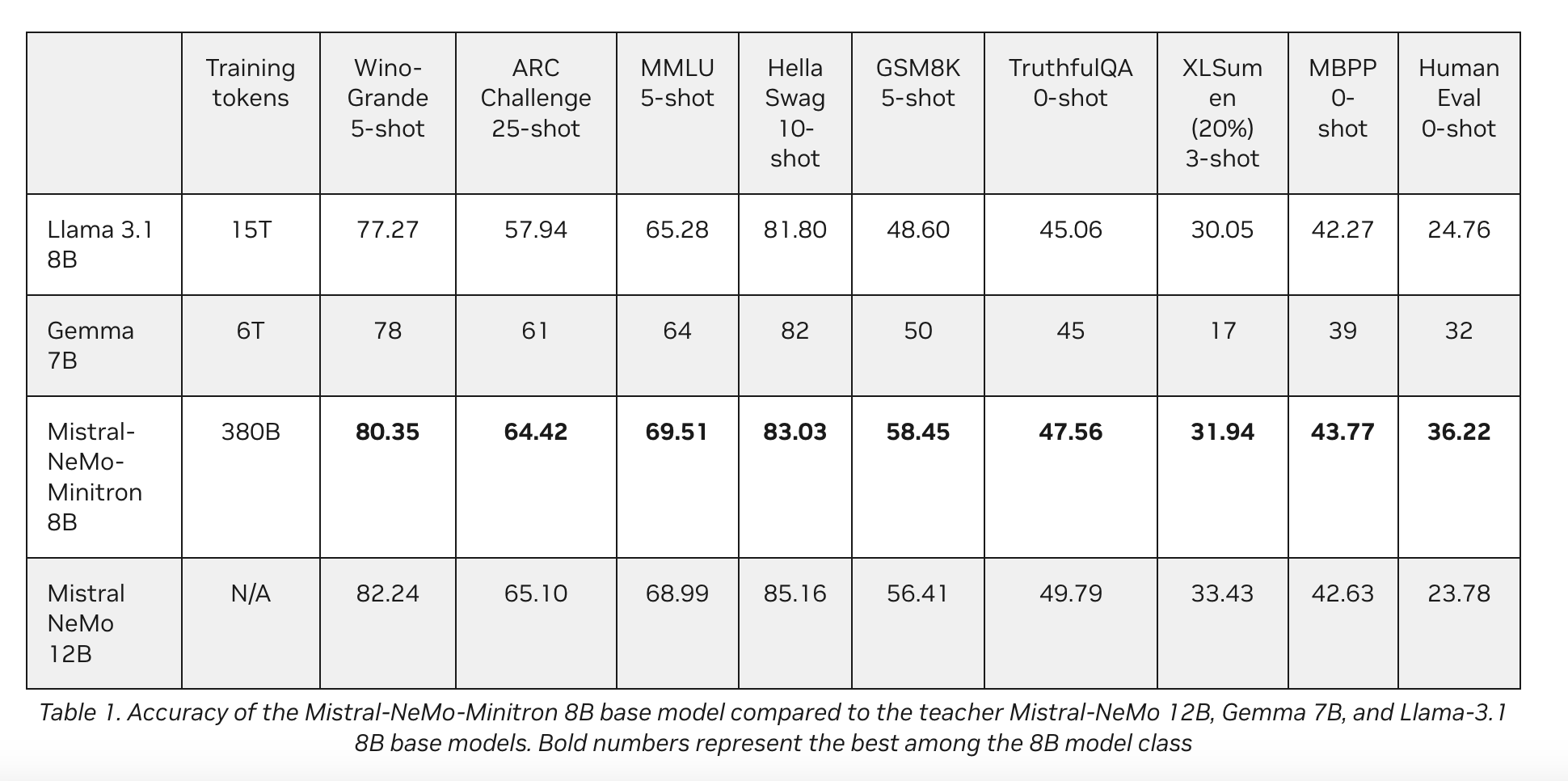
Производительность модели Mistral-NeMo-Minitron 8B — подтверждение успеха подхода обрезки и дистилляции знаний. Модель стабильно превосходит другие модели в своем классе по различным популярным бенчмаркам. Например, на тесте WinoGrande 5-shot модель набрала 80,35, превзойдя модели Llama 3.1 8B и Gemma 7B. Аналогично, она набрала 69,51 на тесте MMLU 5-shot и 83,03 на тесте HellaSwag 10-shot, что делает ее одной из наиболее точных моделей в своей категории.
Технические детали и архитектура
Архитектура модели Mistral-NeMo-Minitron 8B основана на декодере трансформера для авторегрессивного языкового моделирования. Она включает размер встраивания модели 4096, 32 внимательные головы и промежуточное измерение MLP 11 520, распределенные по 40 слоям. Этот дизайн также включает передовые техники, такие как групповое внимание к запросу (GQA) и вращающиеся встраивания позиции (RoPE), способствующие стабильной производительности в различных задачах.
Будущие направления и этические соображения
Выпуск модели Mistral-NeMo-Minitron 8B — это только начало усилий NVIDIA в разработке более маленьких и эффективных моделей через обрезку и дистилляцию. Компания планирует продолжать совершенствовать эту технику для создания еще более маленьких моделей с высокой точностью и эффективностью. Эти модели будут интегрированы в фреймворк NVIDIA NeMo для генеративного искусственного интеллекта, обеспечивая разработчиков мощными инструментами для различных задач обработки естественного языка.
Заключение
NVIDIA представила модель Mistral-NeMo-Minitron 8B, используя обрезку ширины и дистилляцию знаний. Эта модель конкурирует и часто превосходит другие модели в своем классе. По мере того как NVIDIA продолжает совершенствовать и расширять свои возможности в области искусственного интеллекта, модель Mistral-NeMo-Minitron 8B устанавливает новый стандарт эффективности и производительности в обработке естественного языка.
«`


















