

«`html
Исследование Jina-ColBERT-v2: решение для мультиязычного поиска
Сфера информационного поиска (IR) стремительно развивается, особенно с интеграцией нейронных сетей, которые изменили способы извлечения и обработки данных. Нейронные системы поиска становятся все более важными, особенно те, которые используют плотные и многовекторные модели. Однако с ростом спроса на мультиязычные приложения возникает проблема поддержания производительности и эффективности при работе с различными языками. В этой связи становится важным разработать модели, которые будут не только надежными и точными, но также эффективными при работе с масштабными и разнообразными наборами данных без необходимости больших вычислительных ресурсов.
Проблемы и решения в области информационного поиска
Одной из основных проблем в современной среде IR является баланс между производительностью модели и эффективностью ресурсов, особенно в мультиязычных средах. Традиционные модели с одним вектором, хотя и эффективны с точки зрения хранения и вычислений, зачастую нуждаются в большей способности обобщения для работы с различными языками. Мультивекторные модели, такие как ColBERT, предлагают решение, позволяя более детально взаимодействовать с токенами, что улучшает точность поиска. Однако такие модели требуют значительно больше ресурсов, что делает их менее практичными для масштабных и мультиязычных приложений.
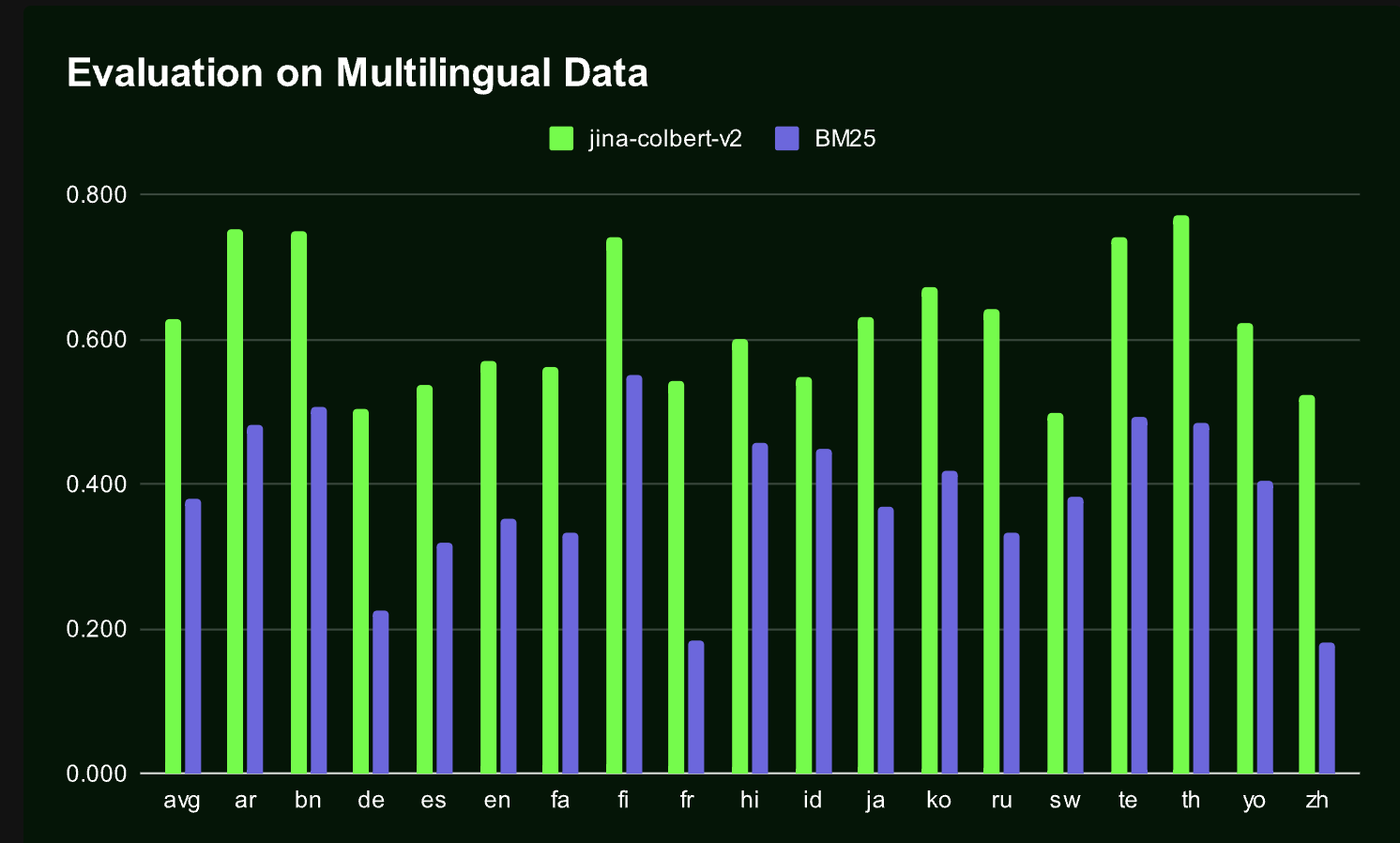
Исследователи из Университета Техаса в Остине и Jina AI GmbH представили Jina-ColBERT-v2, усовершенствованную версию модели ColBERT, разработанную специально для решения текущих проблем. Эта модель включает ряд значительных улучшений, особенно в эффективной работе с мультиязычными данными. Проведенные тесты подтвердили ее эффективность как в англоязычных, так и в мультиязычных средах, что делает ее значительным прорывом в области информационного поиска.
Технологические инновации Jina-ColBERT-v2
Технология Jina-ColBERT-v2 представляет собой совокупность передовых методик, направленных на улучшение эффективности поиска информации. Одним из ключевых инноваций является использование нескольких линейных проекционных головок во время обучения, что позволяет модели выбирать различные размеры токенов во время вывода с минимальной потерей производительности. Эта гибкость достигается за счет Matryoshka Representation Loss, позволяющего модели поддерживать производительность даже при снижении размерности токенов. Благодаря использованию механизмов flash attention и rotary positional embeddings, модель Jina-XLM-RoBERTa становится более эффективной в работе с мультиязычными данными и при этом экономичной в плане хранения и вычислений.
Результаты и перспективы
Испытания Jina-ColBERT-v2 на различных бенчмарках показали его эффективность как в англоязычных, так и в мультиязычных средах. Модель продемонстрировала улучшение производительности по сравнению с предыдущими версиями и показала превосходные результаты в мультиязычных задачах поиска. Способность модели обеспечивать высокую точность поиска при снижении потребностей в хранении на 50% делает ее значительным достижением в области информационного поиска.
В заключение, модель Jina-ColBERT-v2 представляет собой мощное и эффективное решение, интегрирующее передовые техники, такие как flash attention, rotary positional embeddings и Matryoshka Representation Loss. Улучшения производительности на различных бенчмарках подтверждают потенциал модели для широкого применения в академических и промышленных средах. Jina-ColBERT-v2 становится свидетельством непрерывного развития в области информационного поиска, предлагая многообещающее решение для будущего обработки мультиязычных данных.
«`


















