

«`html
Введение в функцию вознаграждения в системах обучения с подкреплением
Функции вознаграждения играют ключевую роль в системах обучения с подкреплением (RL), но их разработка представляет собой серьезные трудности. Нужно найти баланс между простотой определения задачи и эффективностью оптимизации.
Проблемы традиционного подхода
Традиционный подход с использованием бинарных вознаграждений прост, но создает трудности в оптимизации из-за недостатка сигналов для обучения. Внутренние вознаграждения помогли улучшить оптимизацию, но их создание требует значительных знаний и опыта.
Автоматизация дизайна вознаграждений с помощью LLM
Недавние подходы используют Большие Языковые Модели (LLMs) для автоматизации дизайна вознаграждений на основе описаний задач на естественном языке. Существует два основных метода:
- Генерация кодов функций вознаграждения с помощью LLM, что показало успех в задачах непрерывного управления, но требует доступа к исходному коду среды.
- Генерация значений вознаграждений напрямую через LLM, как в методе Motif, который требует предварительно помеченных наборов данных.
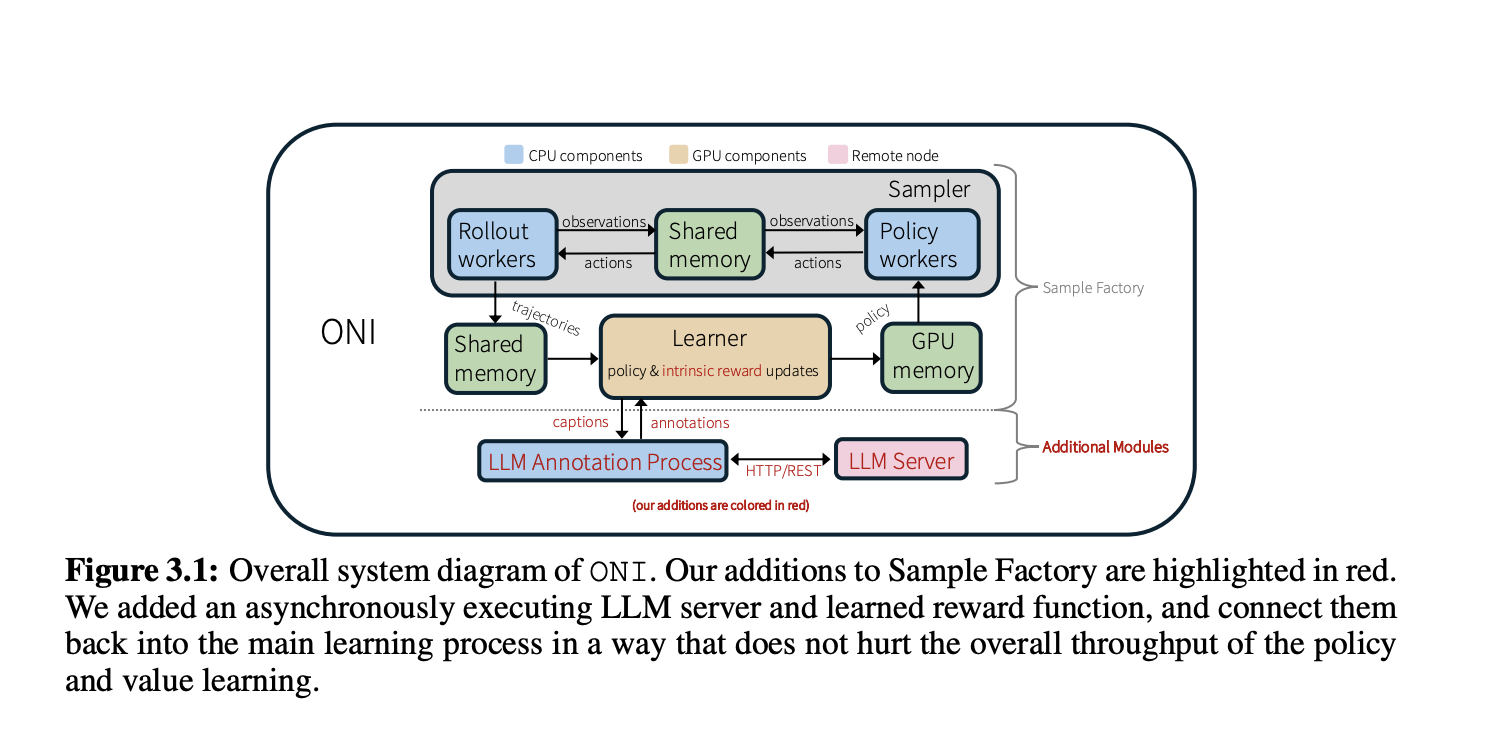
Новая архитектура ONI
Исследователи из Meta, Университета Техаса в Остине и UCLA предложили ONI — новую распределенную архитектуру, которая одновременно обучает политики RL и внутренние функции вознаграждения с помощью обратной связи от LLM. Метод использует асинхронный сервер LLM для аннотирования собранного агентом опыта, который затем преобразуется в модель внутреннего вознаграждения.
Ключевые компоненты ONI
ONI использует несколько ключевых компонентов, включая:
- Сервер LLM на отдельном узле.
- Асинхронный процесс передачи аннотаций наблюдений на сервер LLM.
- Хэш-таблицу для хранения аннотаций и подписей.
- Код для обучения динамической модели вознаграждения.
Результаты экспериментов
Экспериментальные результаты показывают значительные улучшения производительности в различных задачах. Модель ONI демонстрирует передовые результаты в сложных задачах с редкими вознаграждениями, не требуя предварительно собранных данных.
Практические решения для внедрения ИИ
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ), следуйте этим шагам:
- Анализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации.
- Определите ключевые показатели эффективности (KPI). Выберите, что хотите улучшить с помощью ИИ.
- Подберите подходящее решение. Начните с небольшого проекта, анализируйте результаты.
- Расширяйте автоматизацию. Используйте полученные данные и опыт для дальнейшего внедрения.
Если вам нужны советы по внедрению ИИ, пишите нам в Телеграм.
Узнайте, как ИИ может изменить процесс продаж в вашей компании с помощью AI Sales Bot. Это AI ассистент для продаж, который помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Будущее уже здесь!
«`

















