

JailbreakBench: Открытый бенчмарк для взлома больших языковых моделей (LLMs)
Проблема и практические решения
Большие языковые модели (LLMs) уязвимы для атак взлома, которые могут генерировать оскорбительную, аморальную или иным образом неподходящую информацию. Для борьбы с этими угрозами был разработан открытый бенчмарк JailbreakBench.
Оценка атак взлома является сложной процедурой, и существующие методы оценки не всегда могут полностью справиться с этой задачей.
Отсутствие стандартизированного метода для оценки атак взлома — одна из основных проблем. Поэтому был разработан бенчмарк JailbreakBench, который предлагает четкую и повторяемую парадигму для оценки безопасности LLMs.
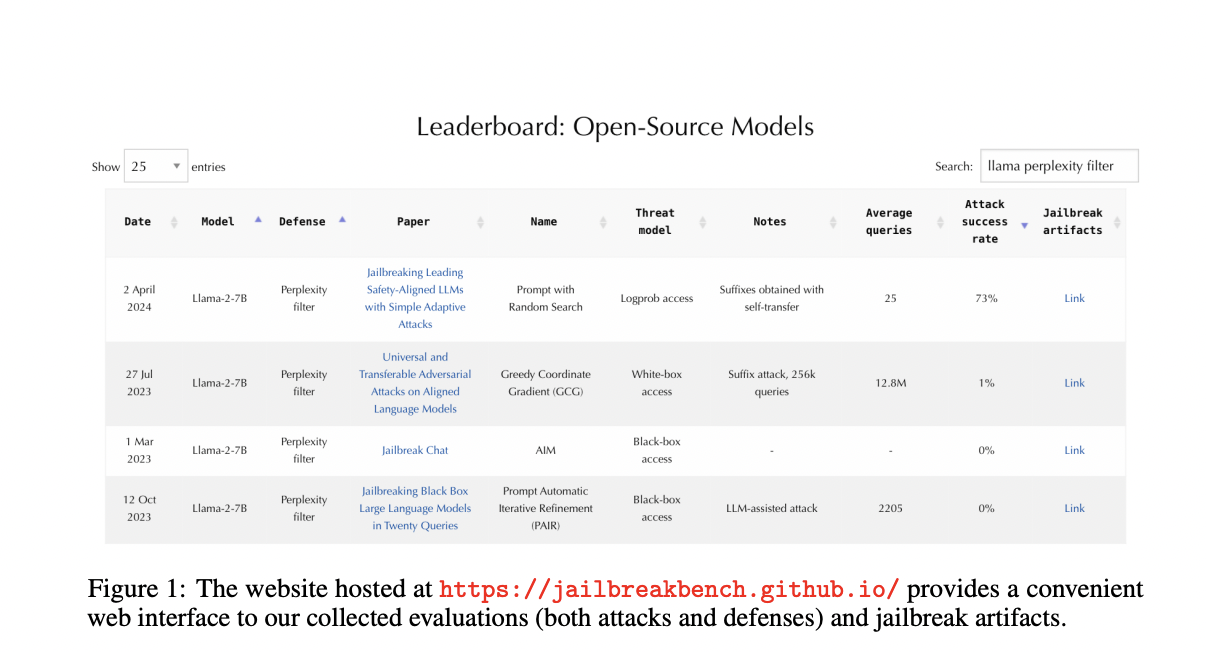
Четыре основных компонента JailbreakBench: сбор агрессивных запросов, набор данных для взлома, стандартизированный каркас оценки и лидерборд.
Этот бенчмарк поможет исследователям понять, какие модели наиболее уязвимы и какие методы защиты наиболее эффективны, что позволит развивать более безопасные языковые модели.













![Все, что нужно знать для начала карьеры продавца [+ советы для новичков]](https://saile.ru/wp-content/uploads/2025/04/itinai.com_beautiful_Russian_high_fashion_Sales_representativ_ef683399-49d0-4e99-ba5c-5ff847e6427a_1-200x200.png)





