

«`html
Исследование производительности бэкендов вывода больших языковых моделей (LLMs)
Выбор правильного бэкенда вывода для обслуживания LLMs является важным шагом. Производительность и эффективность этих бэкендов напрямую влияют на пользовательский опыт и операционные расходы. Недавнее исследование, проведенное командой инженеров BentoML, предлагает ценные исследовательские данные о производительности различных бэкендов вывода, с фокусом на vLLM, LMDeploy, MLC-LLM, TensorRT-LLM и Hugging Face TGI (Text Generation Inference).
Ключевые метрики
Исследование использовало две основные метрики для оценки производительности бэкендов:
- Время до первого токена (TTFT): измеряет задержку от отправки запроса до генерации первого токена. Низкий TTFT важен для приложений, требующих мгновенной обратной связи, таких как интерактивные чат-боты, поскольку существенно улучшает воспринимаемую производительность и удовлетворение пользователей.
- Скорость генерации токенов: определяет, сколько токенов модель генерирует в секунду во время декодирования. Более высокая скорость генерации токенов указывает на способность модели эффективно обрабатывать высокие нагрузки, что делает ее подходящей для сред с множественными одновременными запросами.
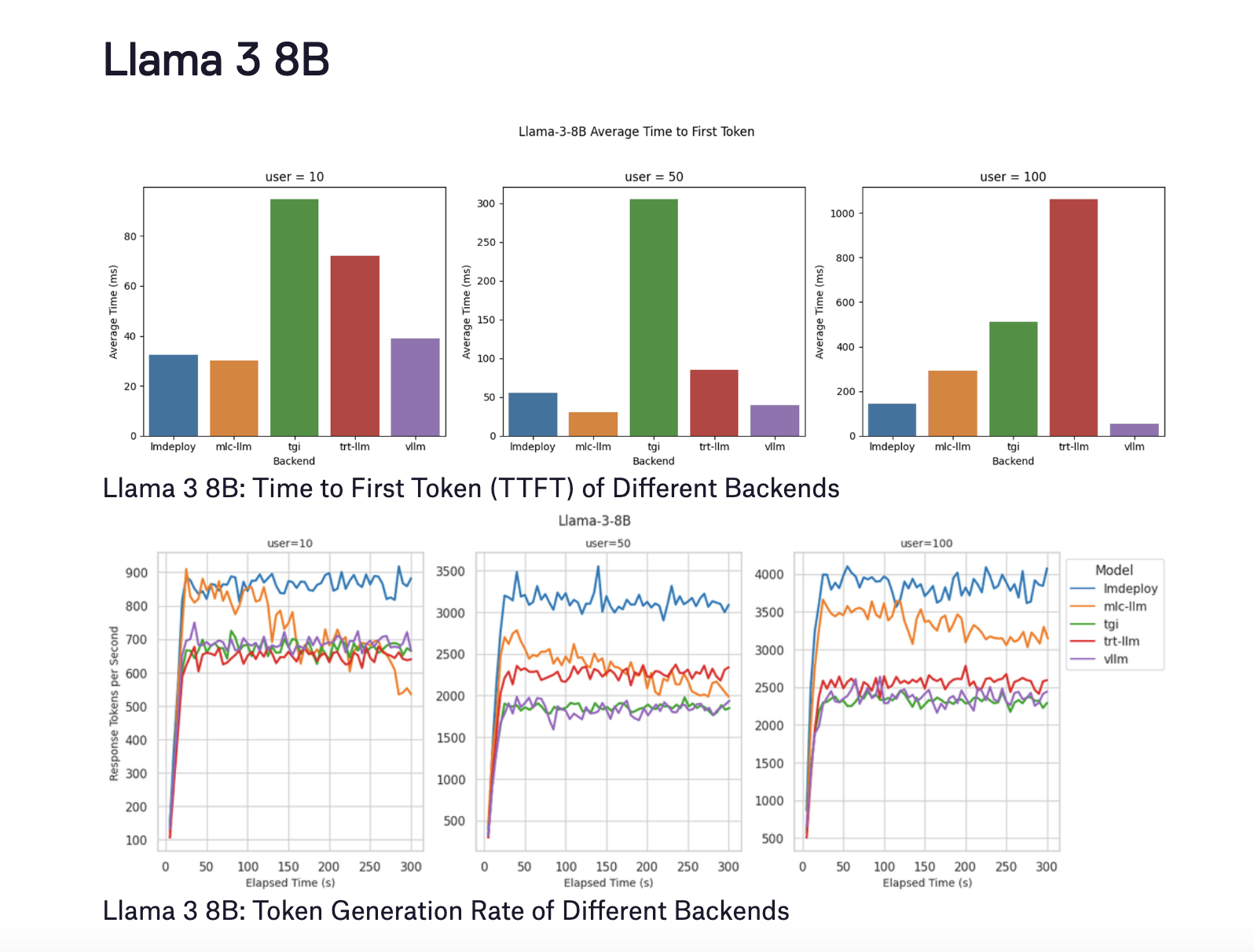
Результаты для Llama 3 8B
Llama 3 8B была протестирована при трех уровнях одновременных пользователей (10, 50 и 100). Ключевые результаты следующие:
- LMDeploy: этот бэкенд показал лучшую производительность декодирования, генерируя до 4000 токенов в секунду для 100 пользователей. Он также достиг лучшего TTFT с десятью пользователями, поддерживая низкий TTFT даже при увеличении количества пользователей.
- MLC-LLM: этот бэкенд достиг незначительно более низкой скорости генерации токенов приблизительно 3500 токенов в секунду для 100 пользователей. Однако его производительность ухудшилась до около 3100 токенов в секунду после пяти минут тестирования. TTFT также значительно ухудшился при 100 пользователях.
- vLLM: хотя vLLM превосходил в поддержании наименьшего TTFT на всех уровнях пользователей, его скорость генерации токенов была менее оптимальной, чем у LMDeploy и MLC-LLM, варьируя от 2300 до 2500 токенов в секунду.
«`



















