Оптимизация взаимодействия CPU и GPU для снижения задержки при работе с LLM
«`html
Исследования и разработки с использованием ИИ
Большие языковые модели (LLMs) сейчас сильно продвигают исследования и разработки. Однако высокие расходы делают их недоступными для многих. Существенной задачей является снижение задержек в операциях, особенно в динамических приложениях, требующих быстрой реакции.
Оптимизация через KV кеш
KV кеш используется для автогенной декодировки в LLM. Он хранит ключи и значения, что снижает сложность обработки. Хотя KV кеш повышает эффективность, его объем может превышать возможности графических процессоров (GPU).
Проблемы с производительностью PCIe
Интерфейсы PCIe могут стать узким местом при передаче кеша между CPU и GPU. Медленные интерфейсы PCIe увеличивают задержки и время простоев GPU.
Новый подход к оптимизации PCIe и GPU
Исследователи Университета Южной Калифорнии предлагают эффективный метод интенсификации LLM, основанный на осведомленности о ввода-вывода между CPU и GPU. Они используют частичную переработку KV кеша и асинхронное перекрытие, чтобы устранить узкие места.
Ключевые модули для снижения задержки
- Модуль профилирования: Сбор информации о системе, такой как пропускная способность PCIe.
- Модуль планировщика: Формулирует задачу как задачу линейного программирования для поиска оптимального точки разбиения KV.
- Рабочий модуль: Координирует передачу данных между устройствами и управляет выделением памяти.
Результаты тестирования
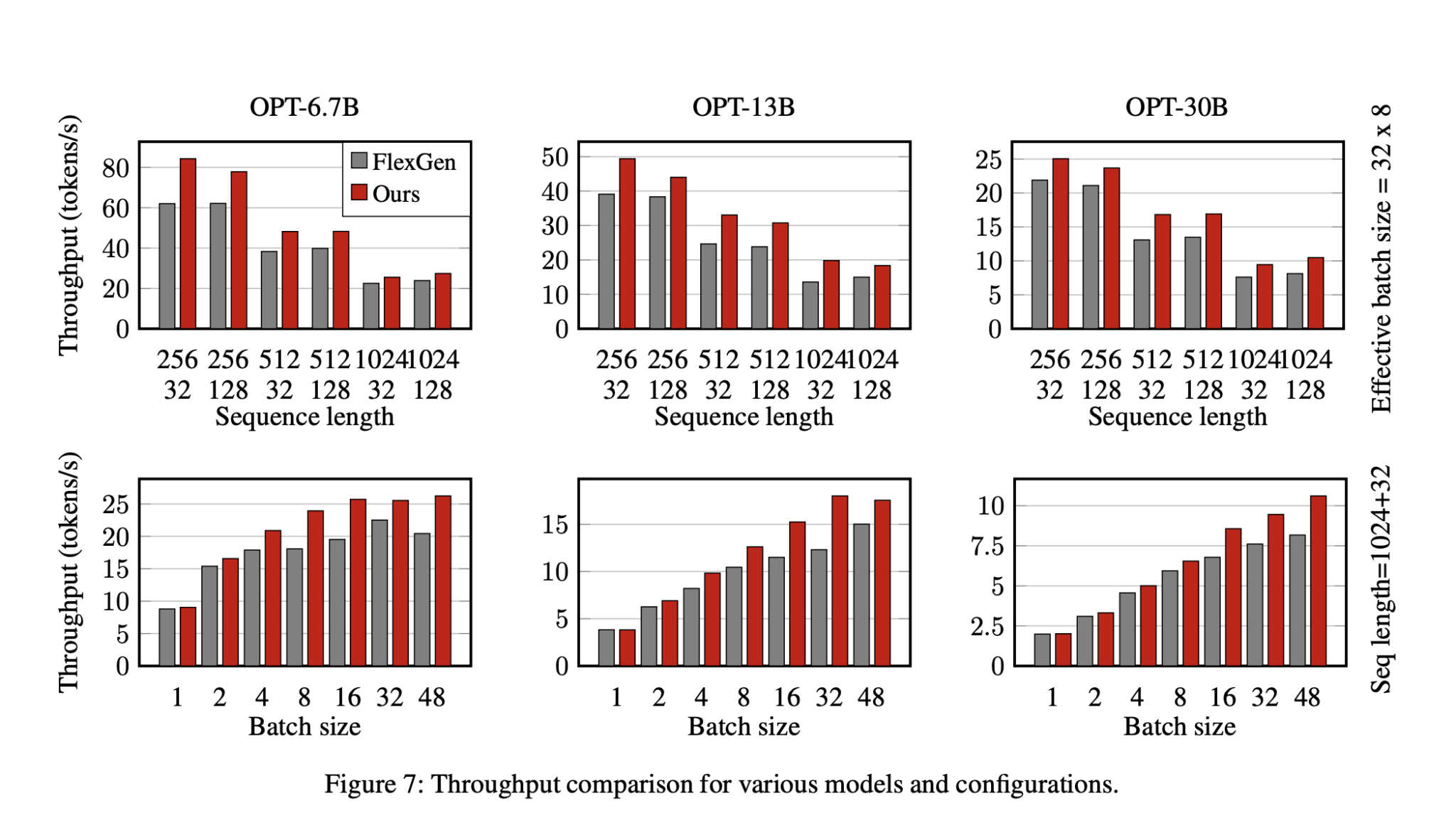
Предложенный метод значительно уменьшил задержку на 35.8% и улучшил производительность на 29% по сравнению с базовыми показателями.
Заключение
Метод I/O-Aware LLM интенсификации эффективно снижает задержки и увеличивает производительность в LLM. Он использует частичную переработку кеша и перекрывание с передачей данных, чтобы минимизировать время простоя GPU.
Преимущества внедрения ИИ в бизнес
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта, используйте методы, подобные описанному выше.
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI) для улучшения с помощью ИИ.
- Подберите подходящее решение и внедряйте его постепенно.
- Расширяйте автоматизацию, основываясь на полученных данных.
Если вам нужны советы по внедрению ИИ, пишите нам в Телеграм. Следите за новостями об ИИ в нашем канале.
AI Sales Bot
Попробуйте AI Sales Bot для автоматизации процессов продаж. Он поможет отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Узнайте, как ИИ может изменить процесс продаж в вашей компании.
«`