Новый фреймворк искусственного интеллекта, объединяющий RAG с длинными контекстными языковыми моделями для улучшения производительности
«`html
Retrieval-Augmented Generation (RAG) и его применение в современных системах
Методы Retrieval-Augmented Generation (RAG) улучшают возможности больших языковых моделей (LLM), интегрируя внешние знания, извлеченные из обширных корпусов. Этот подход особенно полезен для ответов на вопросы в открытой области, где детальные и точные ответы критически важны. RAG-системы могут преодолеть ограничения, связанные с использованием только параметрических знаний LLM, что делает их более эффективными в обработке сложных запросов.
Проблемы и современные методы в RAG-системах
Одной из значительных проблем в RAG-системах является дисбаланс между компонентами «retriever» и «reader». Традиционные фреймворки часто используют короткие единицы извлечения, например, 100-словные отрывки, что требует от извлекателя просеивать большие объемы данных. Этот дизайн неравномерно распределяет нагрузку между извлекателем и ридером, что приводит к неэффективности и потенциальной семантической неполноте из-за усечения документов.
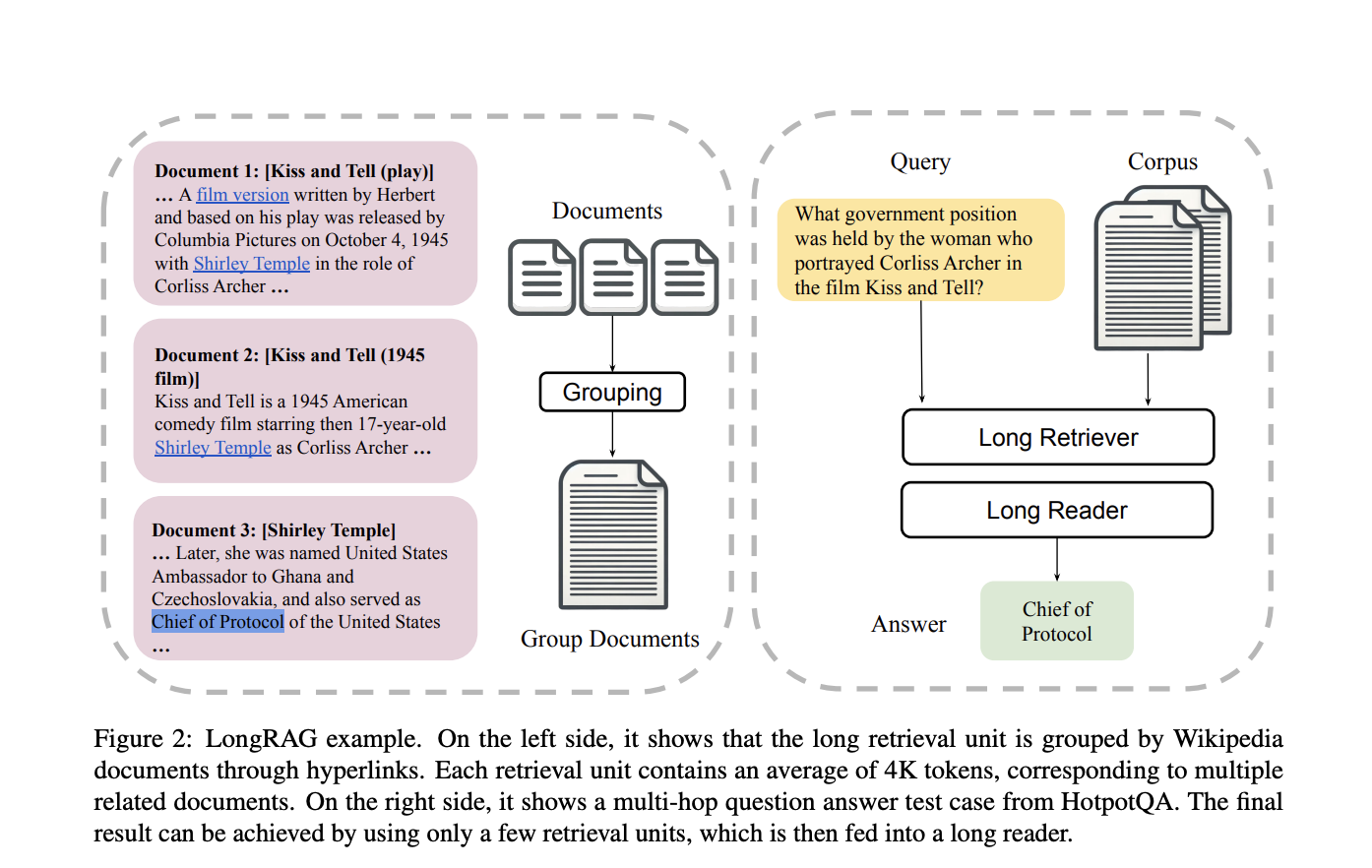
Для решения этих проблем исследовательская группа из Университета Ватерлоо представила новый фреймворк под названием LongRAG. Этот фреймворк включает в себя «длинный извлекатель» и «длинный ридер», предназначенные для обработки более длинных единиц извлечения, около 4 тыс. токенов каждая. Увеличение размера единиц извлечения снижает нагрузку на извлекателя и улучшает показатели извлечения.
Применение LongRAG и его результаты
LongRAG работает путем группировки связанных документов в длинные единицы извлечения, которые затем обрабатывает длинный извлекатель для выявления соответствующей информации. Для извлечения окончательных ответов извлекатель фильтрует топ 4-8 единиц, объединяет их и передает в длинный LLM, такой как Gemini-1.5-Pro или GPT-4o.
Производительность LongRAG действительно впечатляет. На наборе данных Natural Questions (NQ) он достиг точности совпадения (EM) в 62,7%, что является значительным прогрессом по сравнению с традиционными методами. На наборе данных HotpotQA он достиг EM в 64,3%. Эти впечатляющие результаты демонстрируют эффективность LongRAG, соответствуя производительности передовых RAG-моделей.
Завершение и перспективы
LongRAG представляет собой значительный шаг в решении проблем традиционных RAG-систем. Использование длинных единиц извлечения и возможностей продвинутых LLM улучшает точность и эффективность ответов на вопросы в открытой области. Этот инновационный фреймворк улучшает производительность извлечения и подготавливает почву для дальнейших разработок в системах Retrieval-Augmented Generation.
Для получения дополнительной информации ознакомьтесь с статьей и GitHub. Вся заслуга за это исследование принадлежит его авторам.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему SubReddit с 45 тыс. подписчиков.
Попробуйте нашего AI Sales Bot здесь!
«`